為什么要重構到微服務架構
公司決定將支付業務從原來所在部門剝離出來,成為一個獨立的團隊,以應付迅速發展的業務需求。原團隊負責支付系統開發的幾位同學轉到現團隊,形成開發班底。此后開始招聘,三個月團隊擴充到10多個人。與此同時,公司業務也在快速發展,6月份宣布會員突破2千萬。一些熱片上映往往也會引發會員注冊繳費的小高峰。其他業務,包括直播,閱讀,動漫等,也都進入了發展的快車道。每天訂單量早已經超過百萬,比去年某片上映時把系統打垮時還早高。移動端每個月發布一個版本,桌面則是半個月。產品經理們夜以繼日地規劃各種功能,待開發功能都排到好幾個月之后。而隨著項目團隊的日益擴大,卻出現一些奇怪的事情:
- 開發效率和以前沒有太大區別,盡管隊伍擴大了4倍多,人員素質則有所提升。
- 大部分開發工作還是幾位老員工在忙,新員工還比較難介入核心開發工作。
除了管理因素,作為工程師,我們還是期待從技術上找到根源所在,解決問題,提高效率。最終的決策,是使用微服務架構來重構現有系統。這一系列博文,描述在這過程中我們做的選擇、取得的成果、走過的彎路,以及經驗教訓。
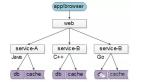
一、原有架構
從技術角度看,原有系統是一個基于SSH架構的傳統實現,軟件架構整體上是大家所熟知的多層Java軟件架構:

代碼讓人看的非常懷舊,雖然開發人員和我說是4年前開發的,但這熟悉的SSH架構,可是妥妥10年前的東西。使用Apache Struts做展示層,對數據訪問層做個簡單封裝實現業務邏輯層,基于Spring 的AOP以及Hibernate實現數據訪問。 數據保存在MySQL中,單庫多表的結構。
二、架構問題
1. DAO層
使用Hibernate來封裝數據庫訪問操作。其優勢是在面向對象領域,通過系統自動生成數據庫訪問語句的方式,使得開發者無需考慮數據庫的實現細節,專注于對象的設計和使用,簡化了開發工作。另外,使用Hibernate還支持系統可以在不同類型的對象數據庫間無縫遷移。在業務對象關系復雜的管理系統開發中廣泛使用。存在的問題是,它隱藏了數據庫的實現細節,這導致在大數據場景下開發人員很難對數據庫訪問進行優化,而這卻是互聯網應用開發的重點。
2. Service層
業務邏輯層為Controller層提供具體業務的實現。但在實現上,問題還不少。如果是嚴格按照分層架構來實現,對業務邏輯層進行拆分,將本地調用變成遠程調用,即可比較容易實現拆分。但實際中往往會碰到如下問題:
- 這個層往往并未實現單向依賴,部分業務邏輯層實現被注入了接口層的參數(request,response),使其耦合到接口層。
- 為了應對不斷變更的需求,不少接口會使用map作為輸入輸出參數,此類接口在維護時無法約束其參數。
- Service層絕大部分實現是使用工廠模式來管理數據對象。僅對工廠類建模,未對業務實體建模。這個層的實現是不完整的。 這使得對業務實體的操作需要推遲到Controller層來實現,導致Controller臃腫。
- 當服務之間存在大量依賴關系時,開發人員往往會直接將Spring BeanFactory注入到各個服務中,或者簡單封裝一個FacadeService,通過這個Service可以訪問到所有的業務邏輯對象。這個類的使用導致無法評估Controller層對Service業務對象的具體依賴。
3. Controller層
基于Apache Struts來實現, Apache Struts 漏洞頻繁爆發,修復慢。當前已經很少在對外的應用中使用了。由于Service層實現上的問題,Controller層承擔了部分業務邏輯實現,使其臃腫,難以測試。
三、功能問題
從功能模塊上來看,并沒有區分對端的服務以及對運營管理系統的服務,僅實現了支付系統的基本功能:

四、實施問題
1. 可擴展性差,性能提升困難
web應用性能瓶頸基本都在數據庫上。這個系統使用mysql作為數據庫。三個應用對應三個數據庫。沒有讀寫分離。讀寫都在一個庫上操作。數據量***的表當時在5000萬條數據。高峰期數據庫操作的QPS在1000左右,壓測結果是可以支撐2000的QPS。這個指標令我詫異。為什么能有這么好的性能?首先是,沒有復雜的查詢邏輯,所有查詢都在一個表里操作,沒有跨表事務處理,復雜的處理,分解為多個語句來執行。最復雜的一個action中,執行了將近20次數據查詢。其次,也是最重要的因素,這里用的是SSD磁盤。從目前情況看,撐到年底應該是可以的,這也為我們技改爭取了足夠的時間。盡管這樣,對mysql還是沒有把握。每次運營部門搞活動,我們都玩膽戰心驚地盯著,祈禱活動不要太有效果。
從應用層來看,目前讀寫比在10:1,接口日訪問量10億。高峰期訪問量在300QPS。公司業務增長迅猛,數據量半年翻一番,訪問量預估10倍增長。還有一個嚴峻的挑戰,產品同學揚言要搞秒殺,秒殺…每秒十萬的量必須支持到。這就超過MYSQL能承受的壓力范圍,需要把讀操作切到內存數據庫上,但是在SSH架構下,讀寫分離實現就得傷筋動骨了。另外由于Hibernate封裝了對數據庫的操作,不用寫SQL了,精細優化也搞不定了。每次系統變慢,就得求DBA,幫看看有那些SQL被卡住了。每隔一段時間,還得請DBA導出SQL語句,研究怎么建索引。
2. 系統臃腫,學習周期長
100多個接口,分為三個大項目。***項目有1300多個類,其次是600多個和300多個類。SSH架構,SVN版本控制,resin作為容器,Nginx前置路由。路由這個讓人欣慰,它是整個重構工作的有力支撐。純后端的項目,為移動端app,PCWEB應用提供接口。這也使得重構工作難度大大降低。如果把前端也耦合進來,那就更酸爽了。
龐大的系統規模為團隊成員接手帶來困難。 支付業務獨立出來后,開發人員從原來的5人,在2個月內擴充到10人。與此同時,興奮的產品同學也都跟打雞血一樣,各種想法紛紛變為產品,開發壓力驟增。但是新增的同學,看著幾百個類,往往一片茫然,無法下手。不知道哪些功能實現了,哪些功能是待改進的。一直到3個月后,新員工才逐步進入角色。盡管如此,還是有不少恐龍級代碼,無人敢挑戰。***的一個類的規模是2000多行, 核心方法超過500行,大量重復代碼, 每次調整都以失敗告終。
3. 合作成本高
隨著項目組人員增加,每次新版本開發都需要多人一起合作,修改同一個項目代碼。 雖然使用版本控制工具來對分支進行管理,但是不可避免的,大量的時間花費在代碼沖突處理上。新增功能,增強功能,bug修復,支持各種客戶端,都在一個項目上進行,需要建立不同的分支,高峰期五六個分支同時進行都是常見的。這種情況下,代碼沖突的頻率非常高。一個周的小版本開發,1天時間在解決沖突都是很正常的。
4. 測試難度大
測試工作也逐步的惡化了。
- 測試環境構建難度高。隨著分支的增加,每個進入測試的分支,都需要準備獨立的測試環境。環境構建成本高。
- 剛測試完的功能,由于分支合并沖突處理,又得重新跑一遍。嚴重影響項目進度。
5. 上線風險高
隨著系統復雜度的增加,上線風險也越來也大。一個小功能的修改,打印一個日志,修復一個bug,都需要整體上線。一旦有一個地方修改錯了,這個系統就崩潰了。上線時間長,一次上線,半個小時是必須的。
6. 引入新技術困難
互聯網公司對新技術的追求和使用顯得特別饑渴,SSH框架降低開發難度和成本同時,也屏蔽了其他技術的導入。緩存機制,數據庫優化,讀寫分離等,SSH有自己的一套邏輯體系,要調整姿勢,成本相對高,技術難度也大,需要對實現底層有深入了解。
CONWAY’S LAW
很長一段時間,這個系統是2-3位開發人員在維護,對外接口、運營系統,都混雜在一起實現,訪問量也不算大。3個獨立系統,對應3個版本庫,每個人負責1-2個系統。當有新功能添加到系統中的時候,大家優先考慮的是如何對現有系統進行改進,而不會考慮是否需要建立新系統。而當公司做業務調整,人員迅速增加后,原有的合作方式,就需要變更了。這就應了所謂的康威定律:
| Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure. |
我們需要一套新的機制來應對新形式下的系統演化的需求。
五、分層與共享庫
避免對原有系統作大規模調整,我們首先考慮的是利用原系統分層實現的特點,實現基于層的分工。在實踐方面,以前負責的管理系統的開發項目,使用SSH架構的,大部分是采用基于分層的分工:
- 將業務邏輯層、數據訪問層、數據表示層封裝為可以獨立維護的庫;
- 將接口層按照業務來拆分,將代碼依賴調整為庫依賴。
- 為各個獨立的庫和項目建立各自的代碼庫。
- 層之間通過接口來交互,基礎層通過單元測試來保證質量,
這種分層的優勢在于能夠很好地解決學習周期的問題。每個層的技術相對獨立,開發人員可以快速上手。
- DAO層相對簡單,因而對于團隊中的新手,可以從這個層入手,熟悉系統架構和軟件過程;
- 業務邏輯層是整個系統的核心,由老員工來負責,對上可以協助顯示層的開發,對下可以指導DAO層的新同學。
- 顯示層需要對HTML,CSS等技術要有所了解。
這種分工,適合10人以內的、一同辦公的團隊。團隊之間是緊耦合的合作關系。對于大型項目,首先需要對項目按照業務進行切分,每個子項目分配到10人以內的團隊來完成,之后對每個團隊,采用分層的分工。但采用這種合作方式,存在的問題是:
- 要求有很好的系統架構設計。需要在編碼啟動前,將各層的接口、數據庫結構確定下來。而這對輕架構的互聯網應用開發來說幾乎是不現實的。不少互聯網公司甚至都沒有架構師的角色,有架構師的公司,還有不少是形同虛設的。
- 團隊內部溝通成本高。層與層之間是緊耦合的關系,對接口的修改必須通知到所有使用方。這要求開發人員之間建立穩定的合作關系,通過約定俗成的規則,降低溝通成本。
- 上述各種問題仍然存在。基礎庫的變更,都需要對線上的系統更新庫之后重新上線。
六、微服務
在開始支付項目改造之前,我們剛剛完成了公司數據倉庫項目的微服務架構改進。這個項目實施詳細過程,在dockone社區做了分享,詳情參見這里。 我們認為調整為微服務架構可以解決上述問題。
1. 性能問題
對于性能要求高的接口,可以通過建立數據緩存的方式進行優化。
2. 學習周期
一個項目僅包含少數緊耦合的接口,接口的業務邏輯單一,開發人員1-2小時通讀代碼,即可快速上手。
3. 合作成本
每個項目相對獨立,項目之間僅通過接口來交互。確定完接口后,開發、測試、上線,都是獨立進行的,從而降低了溝通成本。
4. 版本控制
由于項目之間是接口依賴而不是代碼依賴,每個項目都可以建立獨立的代碼庫。同時項目切分的比較細,每個項目開發時,僅會有一個開發人員對其做修改。這基本就不存在代碼合并工作,也避免了代碼合并過程中的各種問題。實際上,基于微服務架構的開發,我們并沒有采用分支策略,而是直接用主干開發。
5. 測試難度
每個項目獨立部署、獨立測試。由于消除了代碼分支,沒有代碼合并的隱患,重復測試的工作量減少了。
6. 上線風險
每個項目獨立上線,就算出現問題了,也僅影響到少數接口。
7. 新技術
在微服務改造進行一個季度后,各種新技術被引入到系統中,開發不再局限于SSH架構。Spark, Hadoop, Hbase等大數據處理相關的技術,Couchbase, Redis等緩存系統,都開始在項目中使用,并有效地解決的業務上存在的問題。
當然,有利必有弊,微服務帶來的問題,也不少,包括項目多、出問題時排查難等,在實施過程中,也積累了不少的經驗。這些問題,將在后續的分享中逐步做介紹。
【本文為51CTO專欄作者“鳳凰牌老熊”的原創稿件,轉載請通過微信公眾號“鳳凰牌老熊”聯系作者本人】