虛擬機、Docker和Hyper技術比較
操作系統我們知道:
- 完整的操作系統=內核+apps
內核負責管理底層硬件資源,包括CPU、內存、磁盤等等,并向上為apps提供系統調用接口,上層apps應用必須通過系統調用方式使用硬件資源,通常并不能直接訪問資源。apps就是用戶直接接觸的應用,比如命令行工具、圖形界面工具等(linux的圖形界面也是作為可選應用之一,而不像windows是集成到內核中的)。同一個內核加上不同的apps,就構成了不同的操作系統發行版,比如ubuntu、rethat、android(當然內核通常針對不同的發行版會有修改)等等。因此我們可以認為,不同的操作系統發行版本其實就是由應用apps構成的環境的差別(比如默認安裝的軟件以及鏈接庫、軟件包管理、圖形界面應用等等)。我們把所有這些apps環境打成一個包,就可以稱之為鏡像。問題來了,假如我們同時有多個apps環境,能否在同一個內核上運行呢?因為操作系統只負責提供服務,而并不管為誰服務,因此同一個內核之上可以同時運行多個apps環境。比如假設我們現在有ubuntu和fedora的apps環境,即兩個發行版鏡像,分別位于/home/int32bit/ubuntu和/home/int32bit/fedora,我們最簡單的方式,采用chroot工具即可快速切換到指定的應用環境中,相當于同時有多個apps環境在運行。
容器技術
我們以上通過chroot方式,好像就已經實現了容器的功能,但其實容器并沒有那么簡單,工作其實還差得遠。首先要作為云資源管理還必須滿足:
1.資源隔離
因為云計算本質就是集中資源再分配(社會主義),再分配過程就是資源的邏輯劃分,提供資源抽象的實現方式比如我們熟悉的虛擬機等,我們把資源抽象一次劃分稱為單元。單元必須滿足隔離性,包括用戶隔離(或者說權限隔離)進程隔離、網絡隔離、文件系統隔離等,即單元內部只能感知其內部的資源,而不能感知單元以外的資源(包括宿主資源以及其他單元的資源)。
2.資源控制
即為單元分配資源量,能控制單元的資源***使用量。單元不能使用超過分配的資源量。當然還包括其他很多條件,本文主要基于這兩個基本條件進行研究。 顯然滿足以上兩個條件,虛擬機是一種實現方式,這是因為:
- 隔離毋容置疑,因為不同的虛擬機運行在不同的內核,虛擬機內部是一個獨立的隔離環境
- hypervisor能夠對虛擬機分配指定的資源
基于虛擬機快速構建應用環境比如vagrant等。但是虛擬機也帶來很多問題,比如:
- 鏡像臃腫龐大,不僅包括apps,還必須包括一個龐大的內核
- 創建和啟動時間開銷大,不利于快速構建重組
- 額外資源開銷大,部署密度小
- 性能損耗
- …
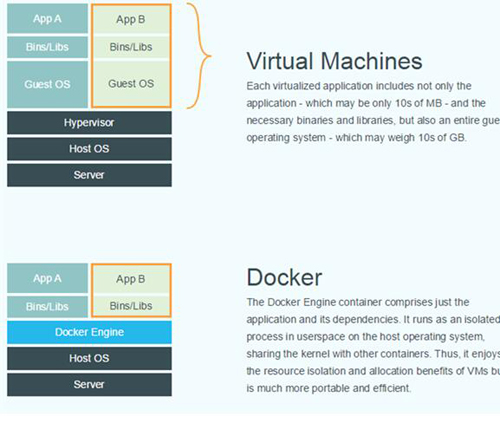
有沒有其他實現方式能符合以上兩個條件呢?容器技術便是另一種實現方式。表面上和我們使用chroot方式相似,即所有的容器實例內部的應用是直接運行在宿主機中,所有實例共享宿主機的內核,而虛擬機實例內部的進程是運行在GuestOS中。由以上原理可知,容器相對于虛擬機有以上好處:
- 鏡像體積更小,只包括應用以及所依賴的環境,沒有內核。
- 創建和啟動快,不需要啟動GuestOS,應用啟動開銷基本就是應用本身啟動的時間開銷。
- 無GuestOS,無hypervisor,無額外資源開銷,資源控制粒度更小,部署密度大。
- 使用的是真實物理資源,因此不存在性能損耗。
- 輕量級
- …
但如何實現資源隔離和控制呢?
1. 隔離性
主要通過內核提供namespace技術實現隔離性,以下參考酷殼:
Linux Namespace是Linux提供的一種內核級別環境隔離的方法。不知道你是否還記得很早以前的Unix有一個叫chroot的系統調用(通過修改根目錄把用戶jail到一個特定目錄下),chroot提供了一種簡單的隔離模式:chroot內部的文件系統無法訪問外部的內容。Linux Namespace在此基礎上,提供了對UTS、IPC、mount、PID、network、User等的隔離機制。
Linux Namespace 有如下種類,官方文檔在這里《Namespace in Operation》
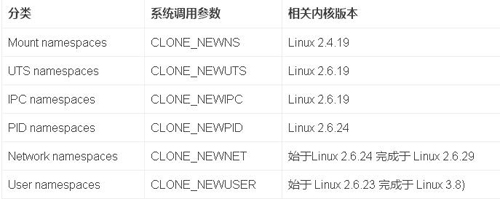
由上表可知,通過Namespaces技術可以實現隔離性,比如網絡隔離,我們可以通過sudo ip netns ls查看網絡命名空間,通過ip netns add NAME增加網絡命名等。
2.資源控制
內核實現了對進程組的資源控制,即Linux Control Group,簡稱cgoup,它能為系統中運行進程組根據用戶自定義組分配資源。簡單來說,可以實現把多個進程合成一個組,然后對這個組的資源進行控制,比如CPU使用時間,內存大小、網絡帶寬、磁盤讀寫等,linux把cgroup抽象成一個虛擬文件系統,可以掛載到指定的目錄下,ubuntu14.04默認自動掛載在/sys/fs/cgroup下,用戶也可以手動掛載,比如掛載memory子系統(子系統一類資源的控制,比如cpu、memory,blkio等)到/mnt下:
- sudo mount -t cgroup -o memory memory /mnt
掛載后就能像查看文件一樣方便瀏覽進程組以及資源控制情況,控制組并不是孤立的,而是組織成樹狀結構構成進程組樹,控制組的子節點會繼承父節點。下面以memory子系統為例,
- ls /sys/fs/cgroup/memory/
輸出:
- cgroup.clone_children memory.kmem.failcnt memory.kmem.tcp.usage_in_bytes memory.memsw.usage_in_bytes memory.swappiness
- cgroup.event_control memory.kmem.limit_in_bytes memory.kmem.usage_in_bytes memory.move_charge_at_immigrate memory.usage_in_bytes
- cgroup.procs memory.kmem.max_usage_in_bytes memory.limit_in_bytes memory.numa_stat memory.use_hierarchy
- cgroup.sane_behavior memory.kmem.slabinfo memory.max_usage_in_bytes memory.oom_control notify_on_release
- docker memory.kmem.tcp.failcnt memory.memsw.failcnt memory.pressure_level release_agent
- memory.failcnt memory.kmem.tcp.limit_in_bytes memory.memsw.limit_in_bytes memory.soft_limit_in_bytes tasks
- memory.force_empty memory.kmem.tcp.max_usage_in_bytes memory.memsw.max_usage_in_bytes memory.stat user
以上是根控制組的資源限制情況,我們以創建控制內存為4MB的Docker容器為例:
- docker run -m 4MB -d busybox ping localhost
返回id為0532d4f4af67,自動會創建以docker實例id為為名的控制組,位于/sys/fs/cgroup/memory/docker/0532d4f4af67...,我們查看該目錄下的memory.limit_in_bytes文件內容為:
- cat memory.limit_in_bytes
- 4194304
即***的可使用的內存為4MB,正好是我們啟動Docker所設定的。
由以上可知,容器實現了資源的隔離性以及控制性。容器的具體實現如LXC、LXD等。
Docker技術
Docker是PaaS提供商dotCloud開源的一個基于LXC的高級容器引擎,簡單說Docker提供了一個能夠方便管理容器的工具。使用Docker能夠:
- 快速構建基于容器的分布式應用
- 具有容器的所有優點
- 提供原生的資源監控
- …
Docker與虛擬機原理對比:
由于容器技術很早就有,Docker最核心的創新在于它的鏡像管理,因此有人說:
- Docker = 容器 + Docker鏡像
Docker鏡像的創新之處在于使用了類似層次的文件系統AUFS,簡單說就是一個鏡像是由多個鏡像層層疊加的,從一個base鏡像中通過加入一些軟件構成一個新層的鏡像,依次構成***的鏡像,如圖
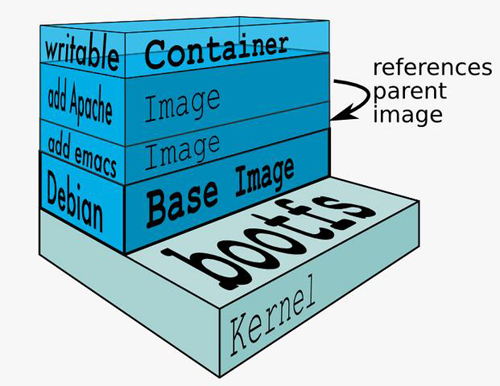
docker的幾點疑問:
Image的分層,可以想象成photoshop中不同的layer。每一層中包含特定的文件,當container運行時,這些疊加在一起的層就構成了container的運行環境(包括相應的文件,運行庫等,不包括內核)。Image通過依賴的關系,來確定整個鏡像內到底包含那些文件。之后的版本的docker,會推出squash的功能,把不同的層壓縮成為一個,和Photoshop中合并層的感覺差不多。 作者:Honglin Feng 鏈接:https://www.zhihu.com/question/25394149/answer/30671258 來源:知乎 著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
這樣的好處是:
- 節省存儲空間 - 多個鏡像共享base image存儲
- 節省網絡帶寬 - 拉取鏡像時,只需要拉取本地沒有的鏡像層,本地已經存在的可以共享,避免多次傳輸拷貝
- 節省內存空間 - 多個實例可共享base image, 多個實例的進程***緩存內容的幾率大大增加。如果基于某個鏡像啟動一個虛擬機需要資源k,則啟動n個同一個鏡像的虛擬機需要占用資源kn,但如果基于某個鏡像啟動一個Docker容器需要資源k,無論啟動多少個實例,資源都是k。
- 維護升級方便 - 相比于 copy-on-write 類型的FS,base-image也是可以掛載為可writeable的,可以通過更新base image而一次性更新其之上的container
- 允許在不更改base-image的同時修改其目錄中的文件 - 所有寫操作都發生在最上層的writeable層中,這樣可以大大增加base image能共享的文件內容。
使用容器技術,帶來了很多優點,但同時也存在一些問題:
- 隔離性相對虛擬機弱-由于和宿主機共享內核,帶來很大的安全隱患,容易發生逃逸。
- 如果某些應用需要特定的內核特性,使用容器不得不更換宿主機內核。
- …
Hyper
上文提到容器也存在問題,并且Docker的核心創新在于鏡像管理,即:
- Docker = 容器 + Docker鏡像
有人提出把容器替換成最初的hypervisor,即接下來介紹的Hyper,官方定義:
- Hyper - a Hypervisor-based Containerization solution
即
- Hyper = Hypervisor + Docker鏡像
Hyper是一個基于虛擬化技術(hypervisor)的Docker引擎。
雖然Hyper同樣通過VM來運行Docker應用,但HyperVM里并沒有GuestOS,相反的,一個HyperVM內部只有一個極簡的HyperKernel,以及要運行的Docker鏡像。這種Kernel+Image的”固態”組合使得HyperVM和Docker容器一樣,實現了Immutable Infrastructure的效果。借助VM天然的隔離性,Hyper能夠完全避免LXC共享內核的安全隱患.
創建一個基于Hyper的ubuntu:
- sudo hyper run -t ubuntu:latest bash
創建時間小于1秒,確實達到啟動容器的效率。 查看內核版本:
- root@ubuntu-latest-7939453236:/# uname -a
- Linux ubuntu-latest-7939453236 4.4.0-hyper+ #0 SMP Mon Jan 25 01:10:46 CST 2016 x86_64 x86_64 x86_64 GNU/Linux
宿主機內核版本:
- $ uname -a
- Linux lenovo 3.13.0-77-generic #121-Ubuntu SMP Wed Jan 20 10:50:42 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
啟動基于Docker的ubuntu并查看內核版本:
- $ docker run -t -i ubuntu:14.04 uname -a
- Linux 73a88ca16d94 3.13.0-77-generic #121-Ubuntu SMP Wed Jan 20 10:50:42 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
我們發現Docker和宿主機的內核版本是一樣的,即3.13.0-77-generic,而Hyper內核不一樣,版本為4.4.0-hyper。 以下為官方數據:
Hyper combines the best from both world: VM and Container.
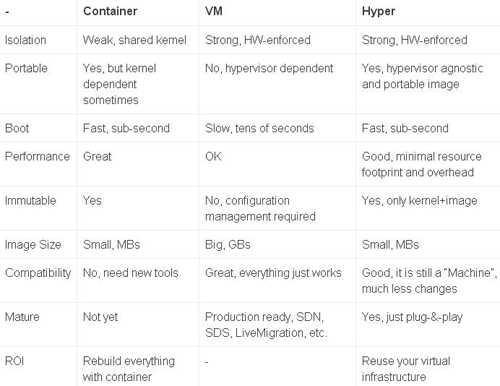
Hyper確實是容器和虛擬機的一種很好的折衷技術,未來可能前景廣大,但需要進一步觀察,我個人主要存在以下疑問:
- 使用極簡的內核,會不會導致某些功能丟失?
- 是不是需要為每一個應用維護一個微內核?
- 有些應用需要特定內核,這些應用實際多么?可以通過其他方式避免么?
- Hyper引擎能否提供和Docker引擎一樣的api,能否在生態圈中相互替代?
- 隔離性加強的同時也犧牲了部分性能,這如何權衡?
總結
本文首先介紹了操作系統,然后引出容器技術以及虛擬機技術,***介紹了Docker和Hyper技術。通過本文可以清楚地對三者有了感性認識。 近年來容器技術以及微服務架構非常火熱,CaaS有取代傳統IaaS的勢頭,未來云計算市場誰成為主流值得期待。
【本文是51CTO專欄作者“付廣平”的原創文章,如需轉載請通過51CTO獲得聯系】