關于JavaScript的數組隨機排序
JavaScript 開發中有時會遇到要將一個數組隨機排序(shuffle)的需求,一個常見的寫法是這樣:
- function shuffle(arr) {
- arr.sort(function () {
- return Math.random() - 0.5;
- });
- }
或者使用更簡潔的 ES6 的寫法:
- function shuffle(arr) {
- arr.sort(() => Math.random() - 0.5);
- }
我也曾經經常使用這種寫法,不久前才意識到,這種寫法是有問題的,它并不能真正地隨機打亂數組。
問題
看下面的代碼,我們生成一個長度為 10 的數組['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'],使用上面的方法將數組亂序,執行多次后,會發現每個元素仍然有很大機率在它原來的位置附近出現。
- let n = 10000;
- let count = (new Array(10)).fill(0);
- for (let i = 0; i < n; i ++) {
- let arr = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'];
- arr.sort(() => Math.random() - 0.5);
- count[arr.indexOf('a')]++;
- }
- console.log(count);
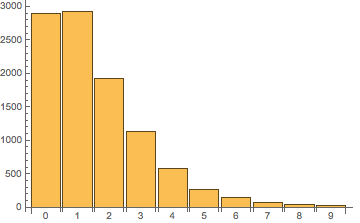
在 Node.JS 6 中執行,輸出[ 2891, 2928, 1927, 1125, 579, 270, 151, 76, 34, 19 ](帶有一定隨機性,每次結果都不同,但大致分布應該一致),即進行 10000 次排序后,字母'a'(數組中的***個元素)有約 2891 次出現在***個位置、2928 次出現在第二個位置,與之對應的只有 19 次出現在***一個位置。如果把這個分布繪制成圖像,會是下面這樣:
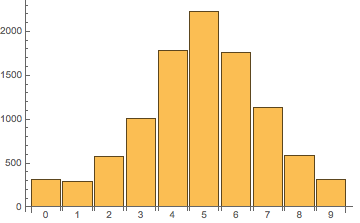
類似地,我們可以算出字母'f'(數組中的第六個元素)在各個位置出現的分布為[ 312, 294, 579, 1012, 1781, 2232, 1758, 1129, 586, 317 ],圖像如下:
如果排序真的是隨機的,那么每個元素在每個位置出現的概率都應該一樣,實驗結果各個位置的數字應該很接近,而不應像現在這樣明顯地集中在原來位置附近。因此,我們可以認為,使用形如arr.sort(() => Math.random() - 0.5)這樣的方法得到的并不是真正的隨機排序。
另外,需要注意的是上面的分布僅適用于數組長度不超過 10 的情況,如果數組更長,比如長度為 11,則會是另一種分布。比如:
- let a = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k']; // 長度為11
- let n = 10000;
- let count = (new Array(a.length)).fill(0);
- for (let i = 0; i < n; i ++) {
- let arr = [].concat(a);
- arr.sort(() => Math.random() - 0.5);
- count[arr.indexOf('a')]++;
- }
- console.log(count);
在 Node.JS 6 中執行,結果為[ 785, 819, 594, 679, 941, 1067, 932, 697, 624, 986, 1876 ],其中***個元素'a'的分布圖如下:
sort_03
分布不同的原因是 v8 引擎中針對短數組和長數組使用了不同的排序方法(下面會講)。可以看到,兩種算法的結果雖然不同,但都明顯不夠均勻。
國外有人寫了一個Shuffle算法可視化的頁面,在上面可以更直觀地看到使用arr.sort(() => Math.random() - 0.5)的確是很不隨機的。
探索
看了一下ECMAScript中關于Array.prototype.sort(comparefn)的標準,其中并沒有規定具體的實現算法,但是提到一點:
Calling comparefn(a,b) always returns the same value v when given a specific pair of values a and b as its two arguments.
也就是說,對同一組a、b的值,comparefn(a, b)需要總是返回相同的值。而上面的() => Math.random() - 0.5(即(a, b) => Math.random() - 0.5)顯然不滿足這個條件。
翻看v8引擎數組部分的源碼,注意到它出于對性能的考慮,對短數組使用的是插入排序,對長數組則使用了快速排序,至此,也就能理解為什么() => Math.random() - 0.5并不能真正隨機打亂數組排序了。(有一個沒明白的地方:源碼中說的是對長度小于等于 22 的使用插入排序,大于 22 的使用快排,但實際測試結果顯示分界長度是 10。)
解決方案
知道問題所在,解決方案也就比較簡單了。
方案一
既然(a, b) => Math.random() - 0.5的問題是不能保證針對同一組a、b每次返回的值相同,那么我們不妨將數組元素改造一下,比如將每個元素i改造為:
- let new_i = {
- v: i,
- r: Math.random()
- };
即將它改造為一個對象,原來的值存儲在鍵v中,同時給它增加一個鍵r,值為一個隨機數,然后排序時比較這個隨機數:
- arr.sort((a, b) => a.r - b.r);
完整代碼如下:
- function shuffle(arr) {
- let new_arr = arr.map(i => ({v: i, r: Math.random()}));
- new_arr.sort((a, b) => a.r - b.r);
- arr.splice(0, arr.length, ...new_arr.map(i => i.v));
- }
- let a = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'];
- let n = 10000;
- let count = (new Array(a.length)).fill(0);
- for (let i = 0; i < n; i ++) {
- shuffle(a);
- count[a.indexOf('a')]++;
- }
- console.log(count);
一次執行結果為:[ 1023, 991, 1007, 967, 990, 1032, 968, 1061, 990, 971 ]。多次驗證,同時在這兒查看shuffle(arr)函數結果的可視化分布,可以看到,這個方法可以認為足夠隨機了。
方案二(Fisher–Yates shuffle)
需要注意的是,上面的方法雖然滿足隨機性要求了,但在性能上并不是很好,需要遍歷幾次數組,還要對數組進行splice等操作。
考察Lodash 庫中的 shuffle 算法,注意到它使用的實際上是Fisher–Yates 洗牌算法,這個算法由 Ronald Fisher 和 Frank Yates 于 1938 年提出,然后在 1964 年由 Richard Durstenfeld 改編為適用于電腦編程的版本。用偽代碼描述如下:
- -- To shuffle an array a of n elements (indices 0..n-1):
- for i from n−1 downto 1 do
- j ← random integer such that 0 ≤ j ≤ i
- exchange a[j] and a[i]
一個實現如下(ES6):
- function shuffle(arr) {
- let i = arr.length;
- while (i) {
- let j = Math.floor(Math.random() * i--);
- [arr[j], arr[i]] = [arr[i], arr[j]];
- }
- }
或者對應的 ES5 版本:
- function shuffle(arr) {
- var i = arr.length, t, j;
- while (i) {
- j = Math.floor(Math.random() * i--);
- t = arr[i];
- arr[i] = arr[j];
- arr[j] = t;
- }
- }
小結
如果要將數組隨機排序,千萬不要再用(a, b) => Math.random() - 0.5這樣的方法。目前而言,Fisher–Yates shuffle 算法應該是***的選擇。