創(chuàng)業(yè)公司做數(shù)據(jù)分析(五)微信分享追蹤系統(tǒng)
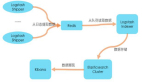
作為系列文章的第五篇,本文重點探討數(shù)據(jù)采集層中的微信分享追蹤系統(tǒng)。微信分享,早已成為移動互聯(lián)網(wǎng)運營的主要方向之一,以Web H5頁面(下面稱之為微信海報)為載體,利用微信龐大的好友關(guān)系進(jìn)行傳播,實現(xiàn)宣傳、拉新等營銷目的。以下圖為例,假設(shè)有一個海報被分享到了微信中,用戶A與B首先看到了這個海報,瀏覽后又分享給了自己的好友,用戶C看到了A分享的海報,瀏覽后繼續(xù)分享給了自己的好友。這便形成了一個簡單的傳播鏈,其中蘊含了兩種數(shù)據(jù):
業(yè)公司做數(shù)據(jù)分析(五)微信分享追蹤系統(tǒng)")
- 行為,指的是用戶對微信海報的操作,比如打開、分享。
- 關(guān)系,指的是在海報傳播過程中,用戶之間形成的傳播關(guān)系,比如用戶A將海報傳播給C。
業(yè)公司做數(shù)據(jù)分析(五)微信分享追蹤系統(tǒng)")
這樣的數(shù)據(jù)的意義在于:***,統(tǒng)計分析各個渠道的海報的傳播效果;第二,對傳播貢獻(xiàn)較大的用戶發(fā)放微信紅包獎勵,提高用戶的分享積極性。微信分享追蹤系統(tǒng),便是完成對這兩種數(shù)據(jù)的采集和存儲。在過去的一年里,受到公司業(yè)務(wù)和運營推廣方向的影響,這部分?jǐn)?shù)據(jù)驅(qū)動了近一半的推廣業(yè)務(wù)。
熟悉微信開發(fā)的朋友應(yīng)該知道,***,每個微信用戶在某個公眾號下都擁有一個唯一的open_id,打開微信海報時,可以通過OAuth2靜默授權(quán)在用戶無感知的情況下拿到其open_id;第二,通過微信JS-SDK,我們可以捕捉到用戶對海報頁面的分享事件;第三,拿到用戶在公眾號下的open_id后,便可以對該用戶發(fā)放微信紅包了。基于這三點,我們便可以實現(xiàn)相關(guān)的數(shù)據(jù)追蹤和分享獎勵了,本文主要是總結(jié)我們在微信分享追蹤上的方案演進(jìn)。
首先要說一點的是,其實微信分享追蹤系統(tǒng)本身并不復(fù)雜,但是與復(fù)雜的產(chǎn)品業(yè)務(wù)結(jié)合到一起,就變得越來越復(fù)雜了。如何做到將數(shù)據(jù)邏輯與產(chǎn)品業(yè)務(wù)邏輯剝離開,以不變應(yīng)萬變,就是這里要說的方案演進(jìn)了。
1. 早期服務(wù)
早期的微信分享追蹤系統(tǒng),筆者曾經(jīng)在淺談微信公眾號營銷背后的技術(shù)一文中介紹過,其時序圖如下所示。基本流程是:***,用戶打開海報時,通過OAuth2授權(quán),將open_id加入到頁面鏈接中;第二,前端上報瀏覽事件,需要帶上open_id和傳播鏈信息;第三,用戶分享時,需要在分享出去的鏈接中加上傳播鏈信息,所謂傳播鏈信息,就是每個分享過的用戶的open_id組合,比如“open_id_1;open_id_2”;第四,上報用戶的分享事件,需要帶上open_id和傳播鏈信息。后端收到上報數(shù)據(jù)后,根據(jù)不同的功能需求,將數(shù)據(jù)保存到不同的數(shù)據(jù)表中,用于后期消費。隨著業(yè)務(wù)的發(fā)展,這個系統(tǒng)暴露出一些問題:
隨著推廣活動的調(diào)整,統(tǒng)計和獎勵政策也隨之變化,比如有的依據(jù)一度分享者的分享次數(shù)進(jìn)行獎勵,有的依據(jù)一度、二度分享者帶來的瀏覽量進(jìn)行獎勵等等,還有需要根據(jù)上報的參數(shù)不同做不同的處理。所有邏輯都在上報的API請求中處理,來一個需求加一段邏輯,導(dǎo)致該請求的功能不斷膨脹,而且一些推廣活動已經(jīng)下線了,相關(guān)的邏輯也沒有清理掉。
參數(shù)比較混亂,頁面URL中攜帶了不同的參數(shù),包括微信相關(guān)參數(shù)、產(chǎn)品相關(guān)參數(shù),前端上報時需要攜帶不同的參數(shù),而前端頁面太多,經(jīng)常搞錯。
業(yè)公司做數(shù)據(jù)分析(五)微信分享追蹤系統(tǒng)")
2. neo4j的嘗試
于是,我們思考,有沒有可能在后端直接構(gòu)建完整的傳播信息,后期使用時直接根據(jù)條件就可以查詢出所需的數(shù)據(jù),前端上報時也不用攜帶傳播鏈信息,我們想到了圖形數(shù)據(jù)庫存儲技術(shù)。
圖形數(shù)據(jù)庫是一種非關(guān)系型數(shù)據(jù)庫,它應(yīng)用圖形理論存儲實體之間的關(guān)系信息。在文章開頭的那張傳播圖中,用戶的行為數(shù)據(jù)其實可以歸結(jié)為用戶與海報之間的關(guān)系數(shù)據(jù),這樣,這個系統(tǒng)其實就包含兩種實體:用戶、海報,三種關(guān)系:用戶打開海報、用戶分享海報、用戶之間的傳播。在諸多圖形數(shù)據(jù)庫中,我們決定選擇比較成熟、文檔相對豐富的neo4j來做DEMO。采用neo4j的查詢語法,很簡單的就可以查詢出所需數(shù)據(jù),簡單示例一下。
業(yè)公司做數(shù)據(jù)分析(五)微信分享追蹤系統(tǒng)")
下圖呈現(xiàn)基于neo4j存儲的新系統(tǒng)時序圖,在OAuth2授權(quán)的重定向過程中,建立User和Poster節(jié)點信息,以及二者之間的OPEN關(guān)系信息,并且對頁面URL計算hash值(去除無用參數(shù)信息),然后將用戶open_id和URL的hash值加到頁面URL中返回給前端。用戶分享時,把該用戶的open_id作為parent字段值,加到分享鏈接中,新用戶打開該鏈接時,會根據(jù)該值來建立User與User節(jié)點之間的SPREAD關(guān)系信息。在用戶分享的事件中,做一次數(shù)據(jù)上報,攜帶open_id和頁面URL的hash值即可,后端拿到信息后,便可以建立User與Poster之間的FORWARD關(guān)系信息。如此,便可以建立完整的微信分享追蹤數(shù)據(jù)了。
業(yè)公司做數(shù)據(jù)分析(五)微信分享追蹤系統(tǒng)")
然而,一切并非預(yù)期的那么***,在DEMO過程中,我們發(fā)現(xiàn)有兩點問題不能很好的滿足我們的需求:
無法根據(jù)時間條件快速查詢信息,比如查詢出昨天的一度分享者。
在查詢用戶間的關(guān)系時,會發(fā)生誤判。比如在下圖所示的傳播關(guān)系中,UserA和UserC的傳播關(guān)系是發(fā)生在海報PosterA上的,在PosterB上并沒有,但是當(dāng)我們嘗試查詢二度分享者時,會將UserA->UserC->PosterB誤判為二度分享。
業(yè)公司做數(shù)據(jù)分析(五)微信分享追蹤系統(tǒng)")
雖然這些問題可以想辦法繞過去,比如根據(jù)時間建立不同的實體節(jié)點等等,但是這樣會把數(shù)據(jù)存儲做復(fù)雜化,經(jīng)過權(quán)衡,我們暫時擱置了這個方案。
3. 基于用戶行為數(shù)據(jù)采集系統(tǒng)的方案
在創(chuàng)業(yè)公司做數(shù)據(jù)分析(三)用戶行為數(shù)據(jù)采集系統(tǒng)一文中,曾經(jīng)提到早期的數(shù)據(jù)采集服務(wù)是分散在各個業(yè)務(wù)功能中的,后來我們重新構(gòu)建了統(tǒng)一的用戶行為數(shù)據(jù)采集系統(tǒng)。在完成這個系統(tǒng)后,我們開始考慮將上述的微信分享追蹤系統(tǒng)并入其中,主要工作有:
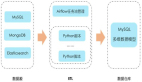
數(shù)據(jù)上報的流程與早期的系統(tǒng)一致,但是更換原有的上報方式,采用用戶行為數(shù)據(jù)采集系統(tǒng)的方案統(tǒng)一上報微信分享的數(shù)據(jù);
數(shù)據(jù)接入Kafka后,一方面直接將原始數(shù)據(jù)存儲到Elasticsearch,另一方面,以worker的形式來消費數(shù)據(jù),根據(jù)相應(yīng)的業(yè)務(wù)需求提取出所需的數(shù)據(jù)存入格式化數(shù)據(jù)表中,用于統(tǒng)計和獎勵活動。當(dāng)某個推廣活動結(jié)束后,將其所屬的worker停掉即可。
業(yè)公司做數(shù)據(jù)分析(五)微信分享追蹤系統(tǒng)")
通過這樣的改進(jìn),我們暫時解決了前端上報混亂和后端業(yè)務(wù)邏輯膨脹的問題,將數(shù)據(jù)上報和業(yè)務(wù)需求隔離開。數(shù)據(jù)方面,實時數(shù)據(jù)流在Kafka中,歷史數(shù)據(jù)也在Elasticsearch中有存儲;業(yè)務(wù)需求方面,來了一個新的需求后,我們只需添加一個新的worker來實現(xiàn)消費邏輯,活動結(jié)束后停掉worker。
點擊查看:
創(chuàng)業(yè)公司做數(shù)據(jù)分析(一)開篇
創(chuàng)業(yè)公司做數(shù)據(jù)分析(二)運營數(shù)據(jù)系統(tǒng)
創(chuàng)業(yè)公司做數(shù)據(jù)分析(三)用戶行為數(shù)據(jù)采集系統(tǒng)
創(chuàng)業(yè)公司做數(shù)據(jù)分析(四)ELK日志系統(tǒng)
創(chuàng)業(yè)公司做數(shù)據(jù)分析(六)數(shù)據(jù)倉庫的建設(shè)