利用WireShark深入調試網絡請求
背景
最近發現我們產品在打開廣告鏈接(Webview)時有一定概率會非常慢,白屏時間超過 10s,追查廣告的過程中遇到不少有意思的事情,感覺頗有收獲。在這里分享一下,主要想聊一聊追查 bug 時的那些方法論,當然也不能太虛,還是要帶一點干貨,比如 WireShark 的使用。
Bug 復現
遇到 bug 后的***件事當然是復現。經過一番測試我發現 bug 幾乎只會主要出現在 iPhone6 這種老舊機型上,而筆者的 7Plus 則基本沒有問題。4G 和 Wifi 下都有一定概率出現,Wifi 似乎更加頻繁。
其實有點經驗的開發者看到這里心里應該有點譜了,這應該不是客戶端的 bug,更可能是由于廣告主網頁質量太低或者網絡環境不穩定導致。但作為一個靠譜的程序員,怎么能把這種毫無根據的猜測向上級匯報呢?
關注點分離
我們知道加載網頁可以由兩部分時間組成,一個是本地的處理時間,另一個是網絡加載的時間。兩者的分水嶺應該在 UIWebview 的 shouldStartLoadWithRequest 方法上。這個方法調用之前是本地處理耗時,調用之后是網絡加載的請求。所以我們可以把事情分成兩部分來看:
從 cell 接受點擊事件的 didSelectedRowAtIndexPath 起到 UIWebview 的 shouldStartLoadWithRequest 為止。
從 shouldStartLoadWithRequest 起到 UIWebview 的 webViewDidFinishLoad 為止。
由于 Bug 是偶現,所以不可能長時間用 Xcode 調試,所以還要注意寫一個簡單的工具,將每次的 Log 日志持久化存下來,保留每一步的函數調用、耗時、具體參數等。這樣一旦復現出來,可以連上電腦讀取手機中的日志。
本地處理
本地處理的耗時相對較短,但邏輯一點都不簡單。在我個人看來,從展示 UITableview 到處理點擊事件的流程,足以反映出一個團隊的技術實力。毫不夸張的說,能把這個小業務做到***的團隊***,其中必然涉及到 MVC/MVVM 等架構的選型設計與具體實現、網絡層與持久化層的封裝、項目模塊化的拆分等核心知識點。我會盡快抽空專門一些篇文章來聊聊這些,這里就不再贅述。
花了一番功夫整理好業務流程、做好統計以后還真有一些收獲。客戶端的邏輯是 pushViewController 動畫執行完后才發送請求,白白浪費了大約 0.5s 的動畫時間,這些時間原本可以用來加載網頁。
網絡請求
借助日志我還發現,本地處理雖然浪費了時間,但這個時間相對穩定,大約在 1s 左右。更大的耗時來自于網絡請求部分。一般情況下,打開網頁會有短暫的白屏時間,這段時間內系統會加載 HTML 等資源并進行渲染,同時界面上有菊花在轉動。
白屏什么時候消失取決于系統什么時候加載完網頁,我們無法控制。但菊花消失的時間是已知的,我們的邏輯是寫在 webViewDidFinishLoad 中。這么做不一定準確,因為網頁重定向時也會調用 webViewDidFinishLoad 方法導致客戶端誤以為已經加載完成。更加準確的做法可以參考: 如何準確判斷 WebView 加載完成,當然這也也僅僅是更準確一些,就 UIWebview 而言,想準確的判斷網絡是否加載完成幾乎是不可能的(感謝 @JackAlan 的實踐)。
所以說網絡加載還可以細分為兩部分,一個是純白屏時間,另一部分則是出現了網頁但還在轉動菊花的時間。這是因為一個 Frame(可以是 HTML 也可以是 iFrame) 全部加載完成(包括 CSS/JS 等)后才會調用 webViewDidFinishLoad 方法,所以存在網頁已經渲染但還在執行 JS 請求的情況,反映在用戶端,就是能看到網頁但菊花還在轉動。這種情況如果持續時間過久會導致用戶不耐煩,但相比于純粹的白屏時間來說更能被接受一些。
同時我們也可以確定,如果網頁已經加載,但 JS 請求還在繼續,這就是廣告主的網頁質量太差導致的。損失應該由他們承擔,我們無能為力。而長時間的白屏則是我們應該重點考慮的問題。
小結
其實分析到這里已經可以向領導匯報了。網絡加載的耗時一共是三段,***段是本地處理時間,存在性能浪費但時間比較穩定,第二段是網頁白屏時間,這段時間內系統的 UIWebView 在請求資源并渲染,第三段是加載網頁后的菊花轉動時間,一般耗時較少,我們也無法控制。
我們還知道 UIWebView 提供的 API 很少,從開始請求到網頁加載結束完全是黑盒模式,幾乎無從下手。但作為一名有追求,有理想,有抱負,有技術的四有程序員,怎么能輕言放棄呢?
WireShark
客戶端在調試網絡時最常用的工具要數 Charles,但它只能調試 HTTP/HTTPS 請求,對 TCP 層就無能為力了。要想了解 HTTP 請求過程中的細節,我們必須要使用威力更大(肯定也更復雜)的武器,也就是本文的主角 WireShark。
一般來說越牛X 的工具長得就越丑,WireShark 也毫不例外的有著一副讓人懵逼的外表。
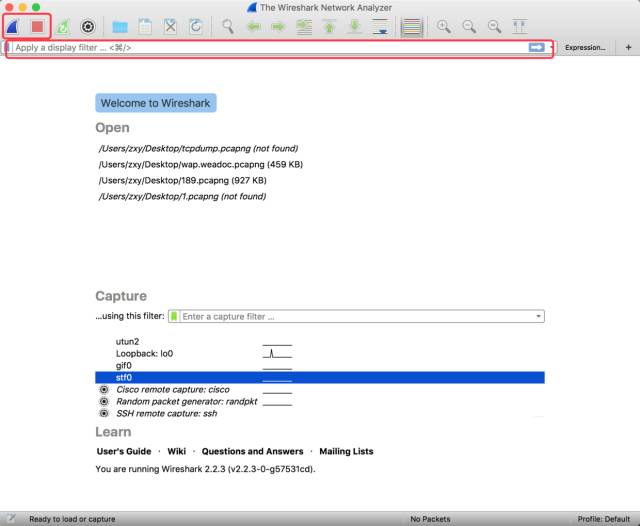
不過不用太急,我們要用到的東西不多,頂部紅框里的藍色鯊魚標志表示開始監聽網絡數據,紅色按鈕一看也能猜出來是停止錄制。與 Charles 只監聽 HTTP 請求不同的是,WireShark 可以調試到 IP 層甚至更細節,所以它的數據包也更多,幾秒鐘的時間就會被上千個請求淹沒,所以我建議用戶略微控制一下監聽的時長,或者我們可以在第二個紅框中輸入過濾條件來減少干擾,這個下文會詳細介紹。
WireShark 可以監聽本機的網卡,也可以監聽手機的網絡。使用 WireShark 調試真機時不用連接代理,只需要通過 USB 連接到電腦就行,否則就無法調試 4G 網絡了。我們可以用 rvictl -s 設備 UDID 命令來創建一個虛擬的網卡:
rvictl -s 902a6a449af014086dxxxxxx346490aaa0a8739
當然,看手機 UDID 還是挺麻煩的,作為一個懶人,怎么能不用命令行來完成呢?
instruments -s | awk '{print $NR}' | sed -n 3p | awk '{print substr($0,2,length($0)-2)}' | xargs rvictl -s
這樣只要連上手機,就可以直接獲取到 UDID 了。
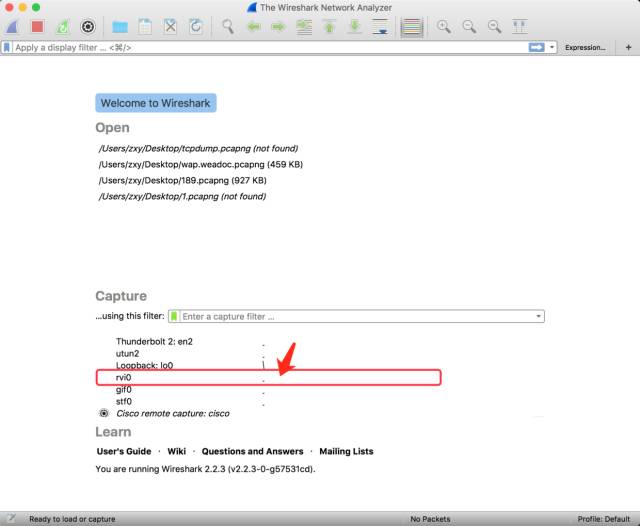
![]()
運行命令后會看到成功創建 rvi0 虛擬網卡的提示,雙擊 rvi0 那一行即可。
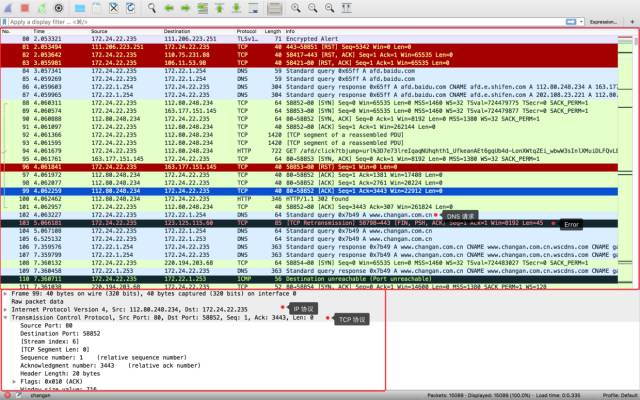
抓包界面
我們主要關注兩個內容,上面的大紅框里面是數據流,包含了 TCP、DNS、ICMP、HTTP 等協議,顏色花花綠綠,絢麗多彩。一般來說黑色的內容表示遇到錯誤,需要重點關注,其他內容則輔助理解。反復調試幾次以后也就能基本記住各種顏色對應的含義了。
下面的小紅框里面主要是某一個包的數據詳解,會根據不同的協議層來劃分,比如我選中的 99 號包時一個 TCP 包,可以很清楚的看到它的 IP 頭部、TCP 頭部和 TCP Payload。這些數據必要時可以做更詳細的分析,但一般也不用關注。
一般來說一次請求的數據包會非常大,可能會有上千個,如何找到自己感興趣的請求呢,我們可以使用之前提到的過濾功能。WireShark 的過濾使用了一套自己定義的語法,不熟悉的話需要上網查一查或者借助自動補全功能來“望文生義”。
由于是要查看 HTTP 請求的具體細節,我們先得找到請求的網址,然后利用 ping 命令得到它對應的 IP 地址。這種做法一般沒問題,但也不排除有的域名會做一些優化,比如不同的 IP 請求 DNS 解析時返回不同的 IP 地址來保證***速度。也就是說手機上 DNS 解析的結果并不總是和電腦上的解析結果一致。這種情況下我們可以通過查看 DNS 數據包來確定。
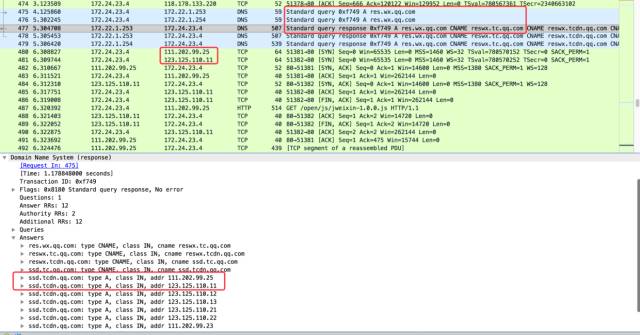
比如從圖中可以看到 res.wx.qq.com 這個域名解析出了一大堆 IP 地址,而真正使用的僅有前兩個。
解析出地址后,我們就可以做簡單的過濾了,輸入ip.addr == 220.194.203.68:

這樣就只顯示和 220.194.203.68 主機之間的通信了。注意紅框中的 SourcePort,這是客戶端端口。我們知道 HTTP 支持并發請求,不同的并發請求肯定是占用不同的端口。所以在圖中看到的上下兩個數據包,并非一定是請求與響應的關系,他們可能屬于兩個不同的端口,彼此之間毫無關系,只是恰好在時間上最接近而已。
如果只想顯示某個端口的數據,可以使用:ip.addr == 220.194.203.68 and tcp.dstport == 58854。
如果只想看 HTTP 協議的 GET 請求與響應,可以使用 ip.addr == 220.194.203.68 and (http.request.method == "GET" || http.response.code == 200) 來過濾。
如果想看丟包方面的數據,可以用 ip.addr == 220.194.203.68 and (tcp.analysis.fast_retransmission || tcp.analysis.retransmission)
以上是筆者在調試過程中用到比較多的命令,僅供參考。有興趣的讀者可以自行抓包實驗,就不挨個貼圖了。
Case1: DNS解析
經過多次抓包后我開始分析那些長時間白屏的網頁對應的數據包,果然發現不少問題,比如這里:
可以很明顯的看到在一大串黑色錯誤信息,但如果你去調試這些數據包,那么就掉進陷阱了。DNS 是基于 UDP 的協議,不會有 TCP 重傳,所以這些黑色的數據包必定是之前的丟包重傳,不用關心。如果只看藍色的 DNS 請求,就會發現連續發送了幾個請求但都沒有響應,直到第 12s 才得到解析后的IP 地址。
從 DNS 請求的接收方的地址以 172.24 開頭可以看出,這是內網 DNS 服務器,不知道為什么卡了很久。
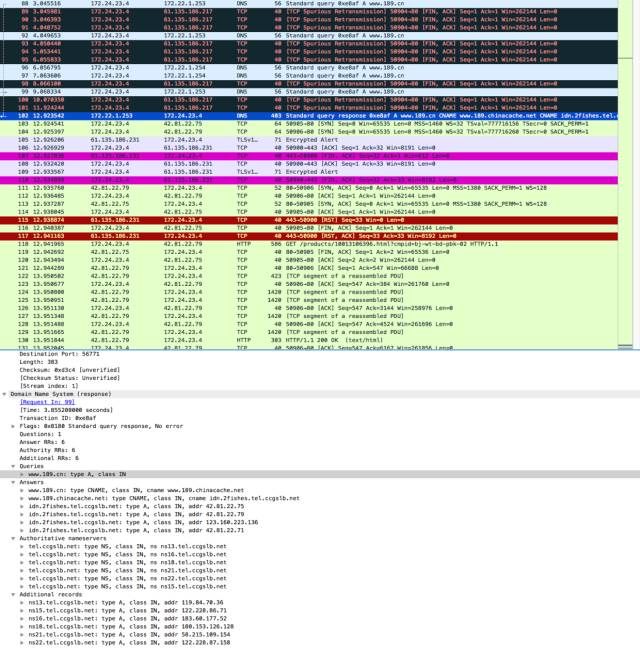
Case2: 握手響應延遲
下圖是一次典型的 TCP 握手時的場景。同時也可以看到***張圖中的 SYN 握手包發出后,過了一秒鐘才接受到 ACK。當然了,原因也不清楚,只能解釋為網絡抖動。
![]()
隨后我又在 4G 網絡下抓了一次包:

這次事情就更離譜了,第二秒發出的 SYN 握手包反復丟失(也有可能是服務端沒有響應、或者是 ACK 丟失),總之客戶端不斷重傳 SYN 包。
更有意思的是,觀察 TSval,它表示包發出時的時間戳。我們觀察這幾個值會發現,前幾次的間隔時間是 1s,后來變成了 2s,4s 和 8s。這不禁讓我想起了 RTO 的概念。
我們知道 RTT 表示的是網絡請求從發起到接收響應的時間,它是一個隨著網絡環境而動態改變的值。TCP 有窗口的概念,對于窗口的***個數據包,如果它無法發送,窗口就不能向后滑動。客戶端以接收到 ACK 作為數據包成功發送的標志,那么如果 ACK 收不到呢?客戶端當然不會一直等下去,它會設置一個超時時間,一旦超過這個時間就認為數據包丟失,從而重傳。
這個超時時間就被稱為 RTO,顯然它必須略大于 RTT,否則就會誤報數據包丟失。但也不能過大,否則會浪費時間。因此合理的 RTO 必須跟隨 RTT 動態調整,始終保證大于 RTT 但也不至于太大。觀察上面的截圖可以發現,某些情況下 RTT 會非常小,小到只有幾毫秒。如果 RTO 也設置為幾毫秒就會顯得不太合理,這會加大客戶端和沿途各路由器的壓力。因此 RTO 還會設置下限,不同的操作系統可能有不同的實現,比如 Linux 上是 200ms。同時,RTO 也會設置上限,具體的算法可以參考這篇文章 和這篇文章。
需要注意的是,RTO 隨著 RTT 動態變化,但如果達到了 RTO 導致了超時重傳,以后的 RTO 就不再隨著 RTT 變化了(此時的 RTT 無法計算),會指數增長。也就是上面截圖中的間隔時間從 2s 變成 4s 再變成 8s 的原因。
同樣的,我們發現了握手花費了 20s 這一現象,但無法給出準確原因,只能解釋為網絡抖動。
總結
通過 TCP 層面的抓包,我們不僅僅學習了 WireShark 的使用,也復習了 TCP 協議的相關知識,對問題的分析也更加深入。從最初的網絡問題開始細化挖掘,得出了白屏時間過長、網頁加載太慢的結論,最終又具體的計算出了有多少個 HTTP 請求,DNS 解析、TCP 握手、TCP 數據傳輸等各個階段的耗時。由此看來,網頁加載慢的罪魁禍首并非廣告主網頁的質量問題,而是網絡的不穩定問題。雖然最終也沒有得到有效的解決方案,但至少明確了問題的發生原因,給出了令人信服的解釋。