基于 Node.js 的聲明式可監(jiān)控爬蟲(chóng)網(wǎng)絡(luò)
爬蟲(chóng)是數(shù)據(jù)抓取的重要手段之一,而以 Scrapy、Crawler4j、Nutch 為代表的開(kāi)源框架能夠幫我們快速構(gòu)建分布式爬蟲(chóng)系統(tǒng);就筆者淺見(jiàn),我們?cè)陂_(kāi)發(fā)大規(guī)模爬蟲(chóng)系統(tǒng)時(shí)可能會(huì)面臨以下挑戰(zhàn):
- 網(wǎng)頁(yè)抓取:最簡(jiǎn)單的抓取就是使用 HTTPClient 或者 fetch 或者 request 這樣的 HTTP 客戶端。現(xiàn)在隨著單頁(yè)應(yīng)用這樣富客戶端應(yīng)用的流行,我們可以使用 Selenium、PhantomJS 這樣的 Headless Brwoser 來(lái)動(dòng)態(tài)執(zhí)行腳本進(jìn)行渲染。
- 網(wǎng)頁(yè)解析:對(duì)于網(wǎng)頁(yè)內(nèi)容的抽取與解析是個(gè)很麻煩的問(wèn)題,DOM4j、Cherrio、beautifulsoup 這些為我們提供了基本的解析功能。筆者也嘗試過(guò)構(gòu)建全配置型的爬蟲(chóng),類似于 Web-Scraper,然而還是輸給了復(fù)雜多變,多層嵌套的 iFrame 頁(yè)面。這里筆者秉持代碼即配置的理念,對(duì)于使用配置來(lái)聲明的內(nèi)建復(fù)雜度比較低,但是對(duì)于那些業(yè)務(wù)復(fù)雜度較高的網(wǎng)頁(yè),整體復(fù)雜度會(huì)以幾何倍數(shù)增長(zhǎng)。而使用代碼來(lái)聲明其內(nèi)建復(fù)雜度與門檻相對(duì)較高,但是能較好地處理業(yè)務(wù)復(fù)雜度較高的網(wǎng)頁(yè)。筆者在構(gòu)思未來(lái)的交互式爬蟲(chóng)生成界面時(shí),也是希望借鑒 FaaS 的思路,直接使用代碼聲明整個(gè)解析流程,而不是使用配置。
- 反爬蟲(chóng)對(duì)抗:類似于淘寶這樣的主流網(wǎng)站基本上都有反爬蟲(chóng)機(jī)制,它們會(huì)對(duì)于請(qǐng)求頻次、請(qǐng)求地址、請(qǐng)求行為與目標(biāo)的連貫性等多個(gè)維度進(jìn)行分析,從而判斷請(qǐng)求者是爬蟲(chóng)還是真實(shí)用戶。我們常見(jiàn)的方式就是使用多 IP 或者多代理來(lái)避免同一源的頻繁請(qǐng)求,或者可以借鑒 GAN 或者增強(qiáng)學(xué)習(xí)的思路,讓爬蟲(chóng)自動(dòng)地針對(duì)目標(biāo)網(wǎng)站的反爬蟲(chóng)策略進(jìn)行自我升級(jí)與改造。另一個(gè)常見(jiàn)的反爬蟲(chóng)方式就是驗(yàn)證碼,從最初的混淆圖片到現(xiàn)在常見(jiàn)的拖動(dòng)式驗(yàn)證碼都是不小的障礙,我們可以使用圖片中文字提取、模擬用戶行為等方式來(lái)嘗試?yán)@過(guò)。
- 分布式調(diào)度:?jiǎn)螜C(jī)的吞吐量和性能總是有瓶頸的,而分布式爬蟲(chóng)與其他分布式系統(tǒng)一樣,需要考慮分布式治理、數(shù)據(jù)一致性、任務(wù)調(diào)度等多個(gè)方面的問(wèn)題。筆者個(gè)人的感覺(jué)是應(yīng)該將爬蟲(chóng)的工作節(jié)點(diǎn)盡可能地?zé)o狀態(tài)化,以 Redis 或者 Consul 這樣的能保證高可用性的中心存儲(chǔ)存放整個(gè)爬蟲(chóng)集群的狀態(tài)。
- 在線有價(jià)值頁(yè)面預(yù)判:Google 經(jīng)典的 PageRank 能夠基于網(wǎng)絡(luò)中的連接信息判斷某個(gè) URL 的有價(jià)值程度,從而優(yōu)先索引或者抓取有價(jià)值的頁(yè)面。而像 Anthelion 這樣的智能解析工具能夠基于之前的頁(yè)面提取內(nèi)容的有價(jià)值程度來(lái)預(yù)判某個(gè) URL 是否有抓取的必要。
- 頁(yè)面內(nèi)容提取與存儲(chǔ):對(duì)于網(wǎng)頁(yè)中的結(jié)構(gòu)化或者非結(jié)構(gòu)化的內(nèi)容實(shí)體提取是自然語(yǔ)言處理中的常見(jiàn)任務(wù)之一,而自動(dòng)從海量數(shù)據(jù)中提取出有意義的內(nèi)容也涉及到機(jī)器學(xué)習(xí)、大數(shù)據(jù)處理等多個(gè)領(lǐng)域的知識(shí)。我們可以使用 Hadoop MapReduce、Spark、Flink 等離線或者流式計(jì)算引擎來(lái)處理海量數(shù)據(jù),使用詞嵌入、主題模型、LSTM 等等機(jī)器學(xué)習(xí)技術(shù)來(lái)分析文本,可以使用 HBase、ElasticSearch 來(lái)存儲(chǔ)或者對(duì)文本建立索引。
筆者本意并非想重新造個(gè)輪子,不過(guò)在改造我司某個(gè)簡(jiǎn)單的命令式爬蟲(chóng)的過(guò)程中發(fā)現(xiàn),很多的調(diào)度與監(jiān)控操作應(yīng)該交由框架完成。Node.js 在開(kāi)發(fā)大規(guī)模分布式應(yīng)用程序的一致性(JavaScript 的不規(guī)范)與性能可能不如 Java 或者 Go。但是正如筆者在上文中提及,JavaScript 的優(yōu)勢(shì)在于能夠通過(guò)同構(gòu)代碼同時(shí)運(yùn)行在客戶端與服務(wù)端,那么未來(lái)對(duì)于解析這一步完全可以在客戶端調(diào)試完畢然后直接將代碼運(yùn)行在服務(wù)端,這對(duì)于構(gòu)建靈活多變的解析可能有一定意義。
總而言之,我只是想有一個(gè)可擴(kuò)展、能監(jiān)控、簡(jiǎn)單易用的爬蟲(chóng)框架,所以我快速擼了一個(gè) declarative-crawler,目前只是處于原型階段,尚未發(fā)布到 npm 中;希望有興趣的大大不吝賜教,特別是發(fā)現(xiàn)了有同類型的框架可以吱一聲,我看看能不能拿來(lái)主義,多多學(xué)習(xí)。
設(shè)計(jì)思想與架構(gòu)概覽
當(dāng)筆者幾年前編寫(xiě)***個(gè)爬蟲(chóng)時(shí),整體思路是典型的命令式編程,即先抓取再解析,***持久化存儲(chǔ),就如下述代碼:
- await fetchListAndContentThenIndex(
- 'jsgc',
- section.name,
- section.menuCode,
- section.category
- ).then(() => {
- }).catch(error => {
- console.log(error);
- });
命令式編程相較于聲明式編程耦合度更高,可測(cè)試性與可控性更低;就好像從 jQuery 切換到 React、Angular、Vue.js 這樣的框架,我們應(yīng)該盡可能將業(yè)務(wù)之外的事情交由工具,交由框架去管理與解決,這樣也會(huì)方便我們進(jìn)行自定義地監(jiān)控。總結(jié)而言,筆者的設(shè)計(jì)思想主要包含以下幾點(diǎn):
- 關(guān)注點(diǎn)分離,整個(gè)架構(gòu)分為了爬蟲(chóng)調(diào)度 CrawlerScheduler、Crawler、Spider、dcEmitter、Store、KoaServer、MonitorUI 等幾個(gè)部分,盡可能地分離職責(zé)。
- 聲明式編程,每個(gè)蜘蛛的生命周期包含抓取、抽取、解析與持久化存儲(chǔ)這幾個(gè)部分;開(kāi)發(fā)者應(yīng)該獨(dú)立地聲明這幾個(gè)部分,而完整的調(diào)用與調(diào)度應(yīng)該由框架去完成。
- 分層獨(dú)立可測(cè)試,以爬蟲(chóng)的生命周期為例,抽取與解析應(yīng)當(dāng)聲明為純函數(shù),而抓取與持久化存儲(chǔ)更多的是面向業(yè)務(wù),可以進(jìn)行 Mock 或者包含副作用進(jìn)行測(cè)試。
整個(gè)爬蟲(chóng)網(wǎng)絡(luò)架構(gòu)如下所示,目前全部代碼參考這里。
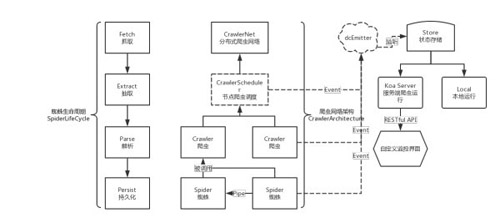
自定義蜘蛛與爬蟲(chóng)
我們以抓取某個(gè)在線列表與詳情頁(yè)為例,首先我們需要針對(duì)兩個(gè)頁(yè)面構(gòu)建蜘蛛,注意,每個(gè)蜘蛛負(fù)責(zé)針對(duì)某個(gè) URL 進(jìn)行抓取與解析,用戶應(yīng)該首先編寫(xiě)列表爬蟲(chóng),其需要聲明 model 屬性、復(fù)寫(xiě) before_extract、parse 與 persist 方法,各個(gè)方法會(huì)被串行調(diào)用。另一個(gè)需要注意的是,我們爬蟲(chóng)可能會(huì)外部傳入一些配置信息,統(tǒng)一的聲明在了 extra 屬性內(nèi),這樣在持久化時(shí)也能用到。
- type ExtraType = {
- module?: string,
- name?: string,
- menuCode?: string,
- category?: string
- };
- export default class UAListSpider extends Spider {
- displayName = "通用公告列表蜘蛛";
- extra: ExtraType = {};
- model = {
- $announcements: 'tr[height="25"]'
- };
- constructor(extra: ExtraType) {
- super();
- this.extra = extra;
- }
- before_extract(pageHTML: string) {
- return pageHTML.replace(/<TR height=\d*>/gim, "<tr height=25>");
- }
- parse(pageElements: Object) {
- let announcements = [];
- let announcementsLength = pageElements.$announcements.length;
- for (let i = 0; i < announcementsLength; i++) {
- let $announcement = $(pageElements.$announcements[i]);
- let $a = $announcement.find("a");
- let title = $a.text();
- let href = $a.attr("href");
- let date = $announcement.find('td[align="right"]').text();
- announcements.push({ title: title, date: date, href: href });
- }
- return announcements;
- }
- /**
- * @function 對(duì)采集到的數(shù)據(jù)進(jìn)行持久化更新
- * @param pageObject
- */
- async persist(announcements): Promise<boolean> {
- let flag = true;
- // 這里每個(gè) URL 對(duì)應(yīng)一個(gè)公告數(shù)組
- for (let announcement of announcements) {
- try {
- await insertOrUpdateAnnouncement({
- ...this.extra,
- ...announcement,
- infoID: href2infoID(announcement.href)
- });
- } catch (err) {
- flag = false;
- }
- }
- return flag;
- }
- }
我們可以針對(duì)這個(gè)蜘蛛進(jìn)行單獨(dú)測(cè)試,這里使用 Jest。注意,這里為了方便描述沒(méi)有對(duì)抽取、解析等進(jìn)行單元測(cè)試,在大型項(xiàng)目中我們是建議要加上這些純函數(shù)的測(cè)試用例。
- var expect = require("chai").expect;
- import UAListSpider from "../../src/universal_announcements/UAListSpider.js";
- let uaListSpider: UAListSpider = new UAListSpider({
- module: "jsgc",
- name: "房建市政招標(biāo)公告-服務(wù)類",
- menuCode: "001001/001001001/00100100100",
- category: "1"
- }).setRequest(
- "http://ggzy.njzwfw.gov.cn/njggzy/jsgc/001001/001001001/001001001001/?Paging=1",
- {}
- );
- test("抓取公共列表", async () => {
- let announcements = await uaListSpider.run(false);
- expect(announcements, "返回?cái)?shù)據(jù)為列表并且長(zhǎng)度大于10").to.have.length.above(2);
- });
- test("抓取公共列表 并且進(jìn)行持久化操作", async () => {
- let announcements = await uaListSpider.run(true);
- expect(announcements, "返回?cái)?shù)據(jù)為列表并且長(zhǎng)度大于10").to.have.length.above(2);
- });
同理,我們可以定義對(duì)于詳情頁(yè)的蜘蛛:
- export default class UAContentSpider extends Spider {
- displayName = "通用公告內(nèi)容蜘蛛";
- model = {
- // 標(biāo)題
- $title: "#tblInfo #tdTitle b",
- // 時(shí)間
- $time: "#tblInfo #tdTitle font",
- // 內(nèi)容
- $content: "#tblInfo #TDContent"
- };
- parse(pageElements: Object) {
- ...
- }
- async persist(announcement: Object) {
- ...
- }
- }
在定義完蜘蛛之后,我們可以定義負(fù)責(zé)爬取整個(gè)系列任務(wù)的 Crawler,注意,Spider 僅負(fù)責(zé)爬取單個(gè)頁(yè)面,而分頁(yè)等操作是由 Crawler 進(jìn)行:
- /**
- * @function 通用的爬蟲(chóng)
- */
- export default class UACrawler extends Crawler {
- displayName = "通用公告爬蟲(chóng)";
- /**
- * @構(gòu)造函數(shù)
- * @param config
- * @param extra
- */
- constructor(extra: ExtraType) {
- super();
- extra && (this.extra = extra);
- }
- initialize() {
- // 構(gòu)建所有的爬蟲(chóng)
- let requests = [];
- for (let i = startPage; i < endPage + 1; i++) {
- requests.push(
- buildRequest({
- ...this.extra,
- page: i
- })
- );
- }
- this.setRequests(requests)
- .setSpider(new UAListSpider(this.extra))
- .transform(announcements => {
- if (!Array.isArray(announcements)) {
- throw new Error("爬蟲(chóng)連接失敗!");
- }
- return announcements.map(announcement => ({
- url: `http://ggzy.njzwfw.gov.cn/${announcement.href}`
- }));
- })
- .setSpider(new UAContentSpider(this.extra));
- }
- }
一個(gè) Crawler 最關(guān)鍵的就是 initialize 函數(shù),需要在其中完成爬蟲(chóng)的初始化。首先我們需要構(gòu)造所有的種子鏈接,這里既是多個(gè)列表頁(yè);然后通過(guò) setSpider 方法加入對(duì)應(yīng)的蜘蛛。不同蜘蛛之間通過(guò)自定義的 Transformer 函數(shù)來(lái)從上一個(gè)結(jié)果中抽取出所需要的鏈接傳入到下一個(gè)蜘蛛中。至此我們爬蟲(chóng)網(wǎng)絡(luò)的關(guān)鍵組件定義完畢。
本地運(yùn)行
定義完 Crawler 之后,我們可以通過(guò)將爬蟲(chóng)注冊(cè)到 CrawlerScheduler 來(lái)運(yùn)行爬蟲(chóng):
- const crawlerScheduler: CrawlerScheduler = new CrawlerScheduler();
- let uaCrawler = new UACrawler({
- module: "jsgc",
- name: "房建市政招標(biāo)公告-服務(wù)類",
- menuCode: "001001/001001001/00100100100",
- category: "1"
- });
- crawlerScheduler.register(uaCrawler);
- dcEmitter.on("StoreChange", () => {
- console.log("-----------" + new Date() + "-----------");
- console.log(store.crawlerStatisticsMap);
- });
- crawlerScheduler.run().then(() => {});
這里的 dcEmitter 是整個(gè)狀態(tài)的中轉(zhuǎn)站,如果選擇使用本地運(yùn)行,可以自己監(jiān)聽(tīng) dcEmitter 中的事件:
- -----------Wed Apr 19 2017 22:12:54 GMT+0800 (CST)-----------
- { UACrawler:
- CrawlerStatistics {
- isRunning: true,
- spiderStatisticsList: { UAListSpider: [Object], UAContentSpider: [Object] },
- instance:
- UACrawler {
- name: 'UACrawler',
- displayName: '通用公告爬蟲(chóng)',
- spiders: [Object],
- transforms: [Object],
- requests: [Object],
- isRunning: true,
- extra: [Object] },
- lastStartTime: 2017-04-19T14:12:51.373Z } }
服務(wù)端運(yùn)行
我們也可以以服務(wù)的方式運(yùn)行爬蟲(chóng):
- const crawlerScheduler: CrawlerScheduler = new CrawlerScheduler();
- let uaCrawler = new UACrawler({
- module: "jsgc",
- name: "房建市政招標(biāo)公告-服務(wù)類",
- menuCode: "001001/001001001/00100100100",
- category: "1"
- });
- crawlerScheduler.register(uaCrawler);
- new CrawlerServer(crawlerScheduler).run().then(()=>{},(error)=>{console.log(error)});
此時(shí)會(huì)啟動(dòng)框架內(nèi)置的 Koa 服務(wù)器,允許用戶通過(guò) RESTful 接口來(lái)控制爬蟲(chóng)網(wǎng)絡(luò)與獲取當(dāng)前狀態(tài)。
接口說(shuō)明
關(guān)鍵字段
- 爬蟲(chóng)
- // 判斷爬蟲(chóng)是否正在運(yùn)行
- isRunning: boolean = false;
- // 爬蟲(chóng)***一次激活時(shí)間
- lastStartTime: Date;
- // 爬蟲(chóng)***一次運(yùn)行結(jié)束時(shí)間
- lastFinishTime: Date;
- // 爬蟲(chóng)***的異常信息
- lastError: Error;
- 蜘蛛
- // ***一次運(yùn)行時(shí)間
- lastActiveTime: Date;
- // 平均總執(zhí)行時(shí)間 / ms
- executeDuration: number = 0;
- // 爬蟲(chóng)次數(shù)統(tǒng)計(jì)
- count: number = 0;
- // 異常次數(shù)統(tǒng)計(jì)
- errorCount: number = 0;
- countByTime: { [number]: number } = {};
localhost:3001/ 獲取當(dāng)前爬蟲(chóng)運(yùn)行狀態(tài)
- 尚未啟動(dòng)
- [
- {
- name: "UACrawler",
- displayName: "通用公告爬蟲(chóng)",
- isRunning: false,
- }
- ]
- 正常返回
- [
- {
- name: "UACrawler",
- displayName: "通用公告爬蟲(chóng)",
- isRunning: true,
- lastStartTime: "2017-04-19T06:41:55.407Z"
- }
- ]
- 出現(xiàn)錯(cuò)誤
- [
- {
- name: "UACrawler",
- displayName: "通用公告爬蟲(chóng)",
- isRunning: true,
- lastStartTime: "2017-04-19T06:46:05.410Z",
- lastError: {
- spiderName: "UAListSpider",
- message: "抓取超時(shí)",
- url: "http://ggzy.njzwfw.gov.cn/njggzy/jsgc/001001/001001001/001001001001?Paging=1",
- time: "2017-04-19T06:47:05.414Z"
- }
- }
- ]
localhost:3001/start 啟動(dòng)爬蟲(chóng)
- {
- message:"OK"
- }
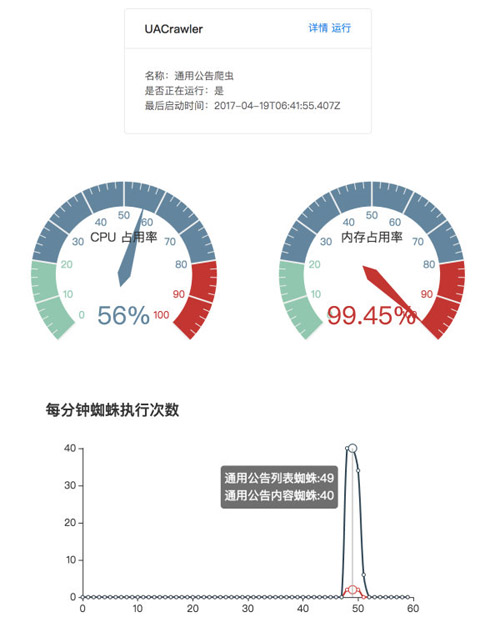
localhost:3001/status 返回當(dāng)前系統(tǒng)狀態(tài)
- {
- "cpu":0,
- "memory":0.9945211410522461
- }
localhost:3001/UACrawler 根據(jù)爬蟲(chóng)名查看爬蟲(chóng)運(yùn)行狀態(tài)
- [
- {
- "name":"UAListSpider",
- "displayName":"通用公告列表蜘蛛",
- "count":6,
- "countByTime":{
- "0":0,
- "1":0,
- "2":0,
- "3":0,
- ...
- "58":0,
- "59":0
- },
- "lastActiveTime":"2017-04-19T06:50:06.935Z",
- "executeDuration":1207.4375,
- "errorCount":0
- },
- {
- "name":"UAContentSpider",
- "displayName":"通用公告內(nèi)容蜘蛛",
- "count":120,
- "countByTime":{
- "0":0,
- ...
- "59":0
- },
- "lastActiveTime":"2017-04-19T06:51:11.072Z",
- "executeDuration":1000.1596102359835,
- "errorCount":0
- }
- ]
自定義監(jiān)控界面
CrawlerServer 提供了 RESTful API 來(lái)返回當(dāng)前爬蟲(chóng)的狀態(tài)信息,我們可以利用 React 或者其他框架來(lái)快速搭建監(jiān)控界面。
【本文是51CTO專欄作者“張梓雄 ”的原創(chuàng)文章,如需轉(zhuǎn)載請(qǐng)通過(guò)51CTO與作者聯(lián)系】