













Caffe的深度學習訓練全過程
今天的目標是使用Caffe完成深度學習訓練的全過程。Caffe是一款十分知名的深度學習框架,由加州大學伯克利分校的賈揚清博士于2013年在Github上發布。自那時起,Caffe在研究界和工業界都受到了極大的關注。Caffe的使用比較簡單,代碼易于擴展,運行速度得到了工業界的認可,同時還有十分成熟的社區。
對于剛開始學習深度學習的同學來說,Caffe是一款十分十分適合的開源框架。可其他同類型的框架,它又一個最大的特點,就是代碼和框架比較簡單,適合深入了解分析。今天將要介紹的內容都是Caffe中成型很久的內容,如今絕大多數版本的Caffe都包含這些功能。關于Caffe下載和安裝的內容請各位根據官方網站指導進行下載和安裝,這里就不再贅述了。
一個常規的監督學習任務主要包含訓練與預測兩個大的步驟,這里還是以Caffe中自帶的例子——MNIST數據集手寫數字識別為例,來介紹一下它具體的使用方法。
如果把上面提到的深度學習訓練步驟分解得更細致一些,那么這個常規流程將分成這幾個子步驟:
- 數據預處理(建立數據庫)
- 網絡結構與模型訓練的配置
- 訓練與在訓練
- 訓練日志分析
- 預測檢驗與分析
- 性能測試
下面就來一一介紹。
1. 數據預處理
首先是訓練數據和預測數據的預處理。這里的工作一般是把待分析識別的圖像進行簡單的預處理,然后保存到數據庫中。為什么要完成這一步而不是直接從圖像文件中讀取數據呢?因為實際任務中訓練數據的數量可能非常大,從圖像文件中讀取數據并進行初始化的效率是非常低的,所以很有必要把數據預先保存在數據庫中,來加快訓練的節奏。
以下的操作將全部在終端完成。第一步是將數據下載到本地,好在MNIST的數據量不算大,如果大家的網絡環境好,這一步的速度會非常快。首先來到caffe的安裝根目錄——CAFFE_HOME,然后執行下面的命令:
- cd data/mnist
- ./get_mnist.sh
程序執行完成后,文件夾下應該會多出來四個文件,這四個文件就是我們下載的數據文件。第二步我們需要調用example中的數據庫創建程序:
- cd $CAFFE_HOME
- ./examples/mnist/create_mnist.sh
程序執行完成后,examples/mnist文件夾下面就會多出兩個文件夾,分別保存了MNIST的訓練和測試數據。值得一提的是,數據庫的格式可以通過修改腳本的BACKEND變量來更換。目前數據庫有兩種主流選擇:
- LevelDB
- LmDB
這兩種數據庫在存儲數據和操縱上有一些不同,首先是它們的數據組織方式不同,這是LevelDB的內容:
這是LMDB的內容:

從結構可以看出LevelDB的文件比較多,LMDB的文件更為緊湊。
其次是它們的讀取數據的接口,某些場景需要遍歷數據庫完成一些原始圖像的分析處理,因此了解它們的數據讀取方法也十分有必要。首先是LMDB讀取數據的代碼: 
其次是LevelDB讀取的代碼:
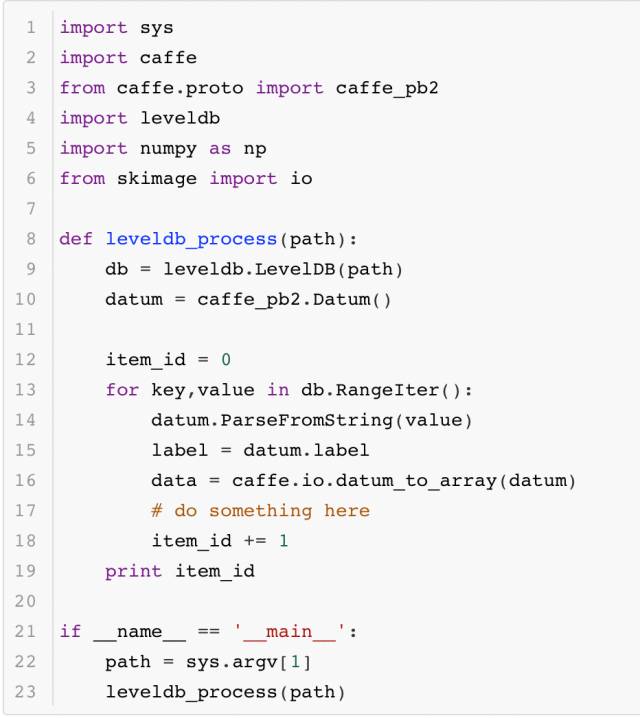
最后回到本小節的問題:為什么要采用數據庫的方式存儲數據而不是直接讀取圖像?這里可以簡單測試一下用MNIST數據構建的這兩個數據庫按序讀取的速度,這里用系統函數time進行計時,結果如下:
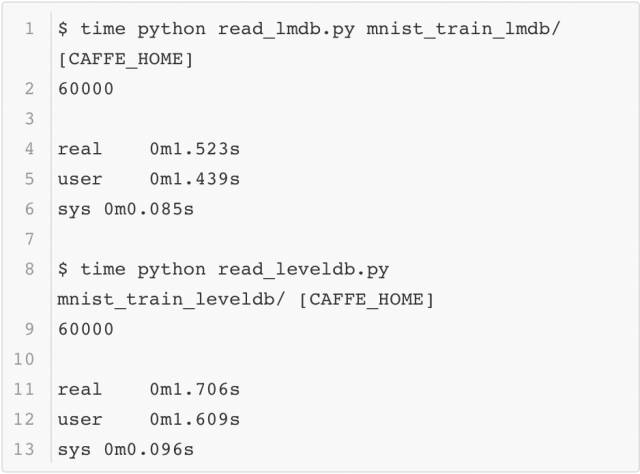
為了比較原始圖像讀入的速度,這里將MNIST的數據以jpeg的格式保存成圖像,并測試它的讀取效率(以Caffe python使用的scikit image為例),代碼如下所示:
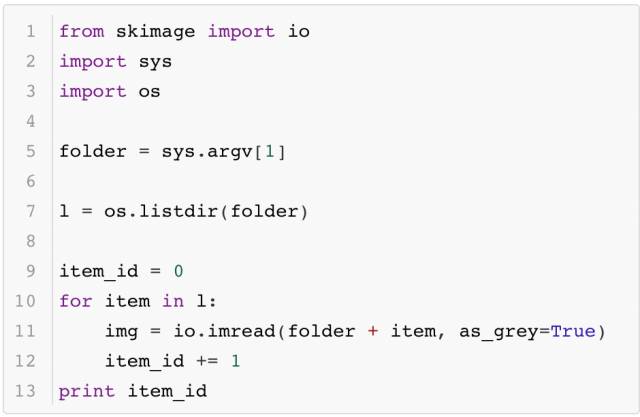
最終的時間如下所示:

由此可以看出,原始圖像和數據庫相比,讀取數據的效率差距還是蠻大的。雖然在Caffe訓練中數據讀入是異步完成的,但是它還是不能夠太慢,所以這也是在訓練時選擇數據庫的原因。
至于這兩個數據庫之間的比較,這里就不再多做了。感興趣的各位可以在一些大型的數據集上做一些實驗,那樣更容易看出兩個數據集之間的區別。
2. 網絡結構與模型訓練的配置
上一節完成了數據庫的創建,下面就要為訓練模型做準備了。一般來說Caffe采用讀入配置文件的方式進行訓練。Caffe的配置文件一般由兩部分組成:solver.prototxt和net.prototxt(有時會有多個net.prototxt)。它們實際上對應了Caffe系統架構中兩個十分關鍵的實體——網絡結構Net和求解器Solver。先來看看一般來說相對簡短的solver.prototxt的內容,為了方便大家理解,所有配置信息都已經加入了注釋:

為了方便大家理解,這里將examples/mnist/lenet_solver.prototxt中的內容進行重新排序,整個配置文件相當于回答了下面幾個問題:
- 網絡結構的文件在哪?
- 用什么計算資源訓練?CPU還是GPU?
- 訓練多久?訓練和測試的比例是如何安排的,什么時候輸出些給我們瞧瞧?
- 優化的學習率怎么設定?還有其他的優化參數——如動量和正則呢?
- 要時刻記得存檔啊,不然大俠得從頭來過了……
接下來就是net.prototxt了,這里忽略了每個網絡層的參數配置,只把表示網絡的基本結構和類型配置展示出來:
- name: "LeNet"
- layer {
- name: "mnist"
- type: "Data"
- top: "data"
- top: "label"
- }
- layer {
- name: "conv1"
- type: "Convolution"
- bottom: "data"
- top: "conv1"
- }
- layer {
- name: "pool1"
- type: "Pooling"
- bottom: "conv1"
- top: "pool1"
- }
- layer {
- name: "conv2"
- type: "Convolution"
- bottom: "pool1"
- top: "conv2"
- }
- layer {
- name: "pool2"
- type: "Pooling"
- bottom: "conv2"
- top: "pool2"
- }
- layer {
- name: "ip1"
- type: "InnerProduct"
- bottom: "pool2"
- top: "ip1"
- }
- layer {
- name: "relu1"
- type: "ReLU"
- bottom: "ip1"
- top: "ip1"
- }
- layer {
- name: "ip2"
- type: "InnerProduct"
- bottom: "ip1"
- top: "ip2"
- }
- layer {
- name: "loss"
- type: "SoftmaxWithLoss"
- bottom: "ip2"
- bottom: "label"
- top: "loss"
- }
這里只展示了網絡結構的基礎配置,也占用了大量的篇幅。一般來說,這個文件中的內容超過100行都是再常見不過的事。而像大名鼎鼎的ResNet網絡,它的文件長度通常在千行以上,更是讓人難以閱讀。那么問題來了,那么大的網絡文件都是靠人直接編輯出來的么?不一定。有的人會比較有耐心地一點點寫完,而有的人則不會愿意做這樣的苦力活。實際上Caffe提供了一套接口,大家可以通過寫代碼的形式生成這個文件。這樣一來,編寫模型配置的工作也變得簡單不少。下面展示了一段生成LeNet網絡結構的代碼:

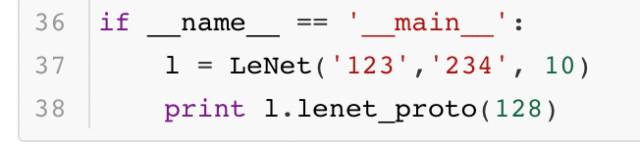
最終生成的結果大家都熟知,這里就不給出了。
- layer {
- name: "data"
- type: "Data"
- top: "data"
- top: "label"
- transform_param {
- scale: 0.00390625
- mirror: false
- }
- data_param {
- source: "123"
- batch_size: 128
- backend: LMDB
- }
- }
- layer {
- name: "conv1"
- type: "Convolution"
- bottom: "data"
- top: "conv1"
- convolution_param {
- num_output: 20
- kernel_size: 5
- stride: 1
- weight_filler {
- type: "xavier"
- }
- bias_filler {
- type: "constant"
- }
- }
- }
- layer {
- name: "pool1"
- type: "Pooling"
- bottom: "conv1"
- top: "pool1"
- pooling_param {
- pool: MAX
- kernel_size: 2
- stride: 2
- }
- }
- layer {
- name: "conv2"
- type: "Convolution"
- bottom: "pool1"
- top: "conv2"
- convolution_param {
- num_output: 50
- kernel_size: 5
- stride: 1
- weight_filler {
- type: "xavier"
- }
- bias_filler {
- type: "constant"
- }
- }
- }
- layer {
- name: "pool2"
- type: "Pooling"
- bottom: "conv2"
- top: "pool2"
- pooling_param {
- pool: MAX
- kernel_size: 2
- stride: 2
- }
- }
- layer {
- name: "ip1"
- type: "InnerProduct"
- bottom: "pool2"
- top: "ip1"
- inner_product_param {
- num_output: 500
- weight_filler {
- type: "xavier"
- }
- bias_filler {
- type: "constant"
- }
- }
- }
- layer {
- name: "relu1"
- type: "ReLU"
- bottom: "ip1"
- top: "ip1"
- }
- layer {
- name: "ip2"
- type: "InnerProduct"
- bottom: "ip1"
- top: "ip2"
- inner_product_param {
- num_output: 10
- weight_filler {
- type: "xavier"
- }
- bias_filler {
- type: "constant"
- }
- }
- }
- layer {
- name: "loss"
- type: "SoftmaxWithLoss"
- bottom: "ip2"
- bottom: "label"
- top: "loss"
- }
大家可能覺得上面的代碼并沒有節省太多篇幅,實際上如果將上面的代碼模塊化做得更好些,它就會變得非常簡潔。這里就不做演示了,歡迎大家自行嘗試。
3. 訓練與再訓練
準備好了數據,也確定了訓練相關的配置,下面正式開始訓練。訓練需要啟動這個腳本:

然后經過一段時間的訓練,命令行產生了大量日志,訓練過程也宣告完成。這時訓練好的模型目錄多出了這幾個文件:

很顯然,這幾個文件保存了訓練過程中的一些內容,那么它們都是做什么的呢?*caffemodel*文件保存了caffe模型中的參數,*solverstate*文件保存了訓練過程中的一些中間結果。保存參數這件事情很容易想象,但是保存訓練中的中間結果就有些抽象了。solverstate里面究竟保存了什么?回答這個問題就需要找到solverstate的內容定義,這個定義來自src/caffe/proto/caffe.proto文件:

從定義中可以很清楚的看出其內容的含義。其中history是一個比較有意思的信息,他存儲了歷史的參數優化信息。這個信息有什么作用呢?由于很多算法都依賴歷史更新信息,如果有一個模型訓練了一半停止了下來,現在想基于之前訓練的成果繼續訓練,那么需要歷史的優化信息幫助繼續訓練。如果模型訓練突然中斷訓練而歷史信息又丟失了,那么模型只能從頭訓練。這樣的深度學習框架就不具備“斷點訓練”的功能了,只有"重頭再來"的功能。現在的大型深度學習模型都需要很長的時間訓練,有的需要訓練好幾天,如果框架不提供斷點訓練的功能,一旦機器出現問題導致程序崩潰,模型就不得不重頭開始訓練,這會對工程師的身心造成巨大打擊……所以這個存檔機制極大地提高了模型訓練的可靠性。
從另一個方面考慮,如果模型訓練徹底結束,這些歷史信息就變得無用了。caffemodel文件需要保存下來,而solverstate這個文件可以被直接丟棄。因此這種分離存儲的方式特別方便操作。
從剛才提到的“斷點訓練”可以看出,深度學習其實包含了“再訓練”這個概念。一般來說“再訓練”包含兩種模式,其中一種就是上面提到的“斷點訓練”。從前面的配置文件中可以看出,訓練的總迭代輪數是10000輪,每訓練5000輪,模型就會被保存一次。如果模型在訓練的過程中被一些不可抗力打斷了(比方說機器斷電了),那么大家可以從5000輪迭代時保存的模型和歷史更新參數恢復出來,命令如下所示:

這里不妨再深入一點分析。雖然模型的歷史更新信息被保存了下來,但當時的訓練場景真的被完全恢復了么?似乎沒有,還有一個影響訓練的關鍵因素沒有恢復——數據,這個是不容易被訓練過程精確控制的。也就是說,首次訓練時第5001輪迭代訓練的數據和現在“斷點訓練”的數據是不一樣的。但是一般來說,只要保證每個訓練批次(batch)內數據的分布相近,不會有太大的差異,兩種訓練都可以朝著正確的方向前進,其中存在的微小差距可以忽略不計。
第二種“再訓練”的方式則是有理論基礎支撐的訓練模式。這個模式會在之前訓練的基礎上,對模型結構做一定的修改,然后應用到其他的模型中。這種學習方式被稱作遷移學習(Transfer Learning)。這里舉一個簡單的例子,在當前模型訓練完成之后,模型參數將被直接賦值到一個新的模型上,然后讓這個新模型重頭開始訓練。這個操作可以通過下面這個命令完成:

執行命令后Caffe會像往常一樣開始訓練并輸出大量日志,但是在完成初始化之后,它會輸出這樣一條日志:
![]()
這條日志就是在告訴我們,當前的訓練是在這個路徑下的模型上進行"Finetune"。
4. 訓練日志分析
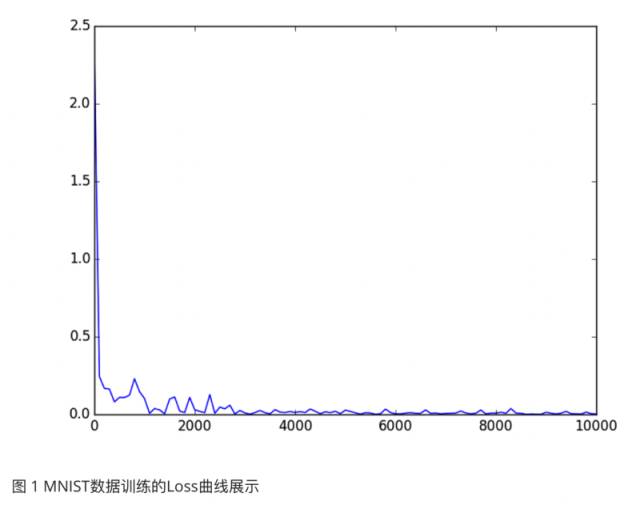
訓練過程中Caffe產生了大量的日志,這些日志包含很多訓練過程的信息,非常很值得分析。分析的內容有很多,其中之一就是分析訓練過程中目標函數loss的變化曲線。在這個例子中,可以分析隨著迭代輪數不斷增加,Softmax Loss的變化情況。首先將訓練過程的日志信息保存下來,比方說日志信息被保存到mnist.log文件中,然后用下面的命令可以將Iteration和Loss的信息提取并保存下來:

提取后的信息可以用另一個腳本完成Loss曲線的繪圖工作:
- import matplotlib.pyplot as plt
- x = []
- y = []
- with open('loss_data') as f:
- for line in f:
- sps = line[:-1].split()
- x.append(int(sps[0]))
- y.append(float(sps[1]))
- plt.plot(x,y)
- plt.show()
結果如圖1所示,可見Loss很快就降到了很低的地方,模型的訓練速度很快。這個優異的表現可以說明很多問題,但這里就不做過多地分析了。
除此之外,日志中輸出的其他信息也可以被觀察分析,比方說測試環節的精確度等,它們也可以通過上面的方法解析出來。由于采用的方法基本相同,這里有不去贅述了,各位可以自行嘗試。
正常訓練過程中,日志里只會顯示每一組迭代后模型訓練的整體信息,如果想要了解更多詳細的信息,就要將solver.prototxt中的調試信息打開,這樣就可以獲得更多有用的信息供大家分析:
- debug_info:true
調試信息打開后,每一組迭代后每一層網絡的前向后向計算過程中的詳細信息都可以被觀測到。這里截取其中一組迭代后的日志信息展示出來:
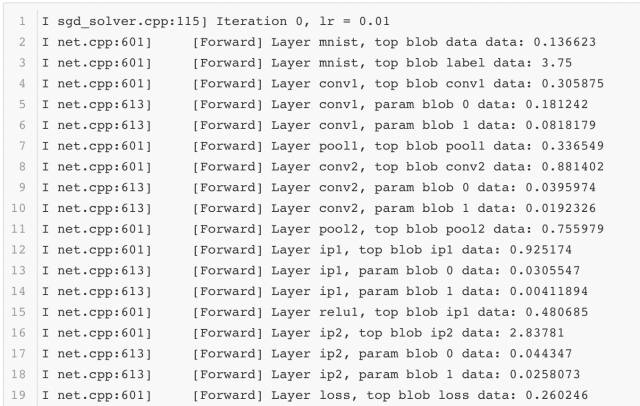

如果想要對網絡的表現做更多地了解,那么分析這些內容必不可少。
5. 預測檢驗與分析
模型完成訓練后,就要對它的訓練表現做驗證,看看它在其他測試數據集上的正確性。Caffe提供了另外一個功能用于輸出測試的結果。以下就是它的腳本:
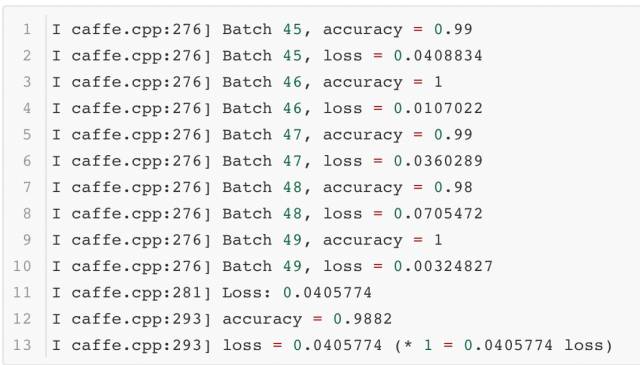
腳本的輸出結果如下所示:
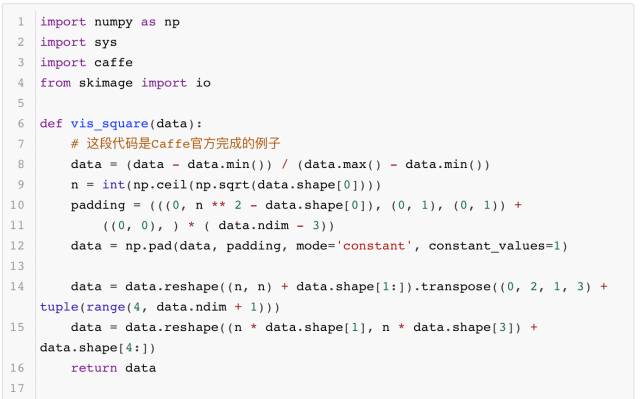
除了完成測試的驗證,有時大家還需要知道模型更多的運算細節,這就需要深入模型內部去觀察模型產生的中間結果。使用Caffe提供的借口,每一層網絡輸出的中間結果都可以用可視化的方法顯示出來,供大家觀測、分析模型每一層的作用。其中的代碼如下所示:


執行上面的代碼就可以生成如圖2到圖5這幾張圖像,它們各代表一個模型層的輸出圖像:



這一組圖展示了卷積神經網絡是如何把一個數字轉變成特征編碼的。這樣的方法雖然可以很好地看到模型內部的表現,比方說conv1的結果圖中有的提取了數字的邊界,有的明確了前景像素所在的位置,這個現象和第3章中舉例的卷積效果有幾分相似。但是到了conv2的結果圖中,模型的輸出就變得讓人有些看不懂了。實際上想要真正看懂這些圖像想表達的內容確實有些困難的。
6. 性能測試
除了在測試數據上的準確率,模型的運行時間也非常值得關心。如果模型的運行時間太長,甚至到了不可用的程度,那么即使它精度很高也沒有實際意義。測試時間的腳本如下所示:
![]()
Caffe會正常的完成前向后向的計算,并記錄其中的時間。以下是使一次測試結果的時間記錄:
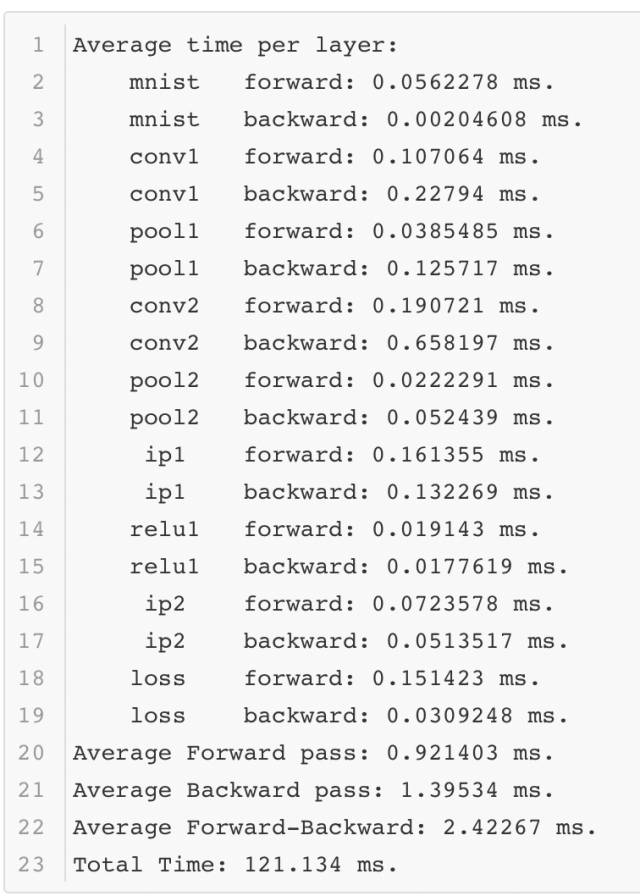
可以看出在性能測試的過程中,Lenet模型只需要不到1毫秒的時間就可以完成前向計算,這個速度還是很快的。當然這是在一個相對不錯的GPU上運行的,那么如果在一個條件差的GPU上運行,結果如何呢?
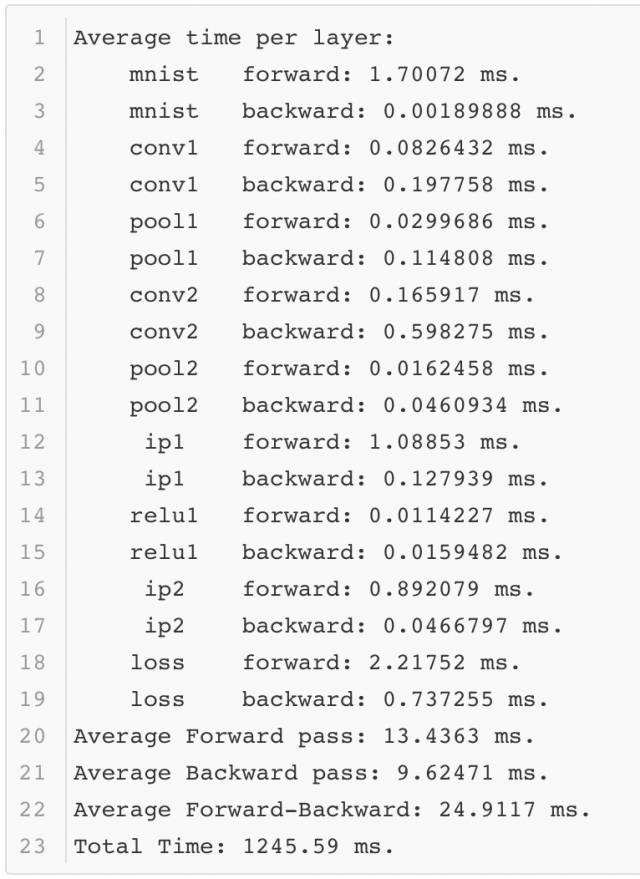
可以看到不同的環境對于模型運行的時間影響很大。
以上就是模型訓練的一個完整過程。現在相信大家對深度學習模型的訓練和使用有了基本的了解。實際上看到這里大家甚至可以扔下書去親自實踐不同模型的效果,開始深度學習的實戰之旅。
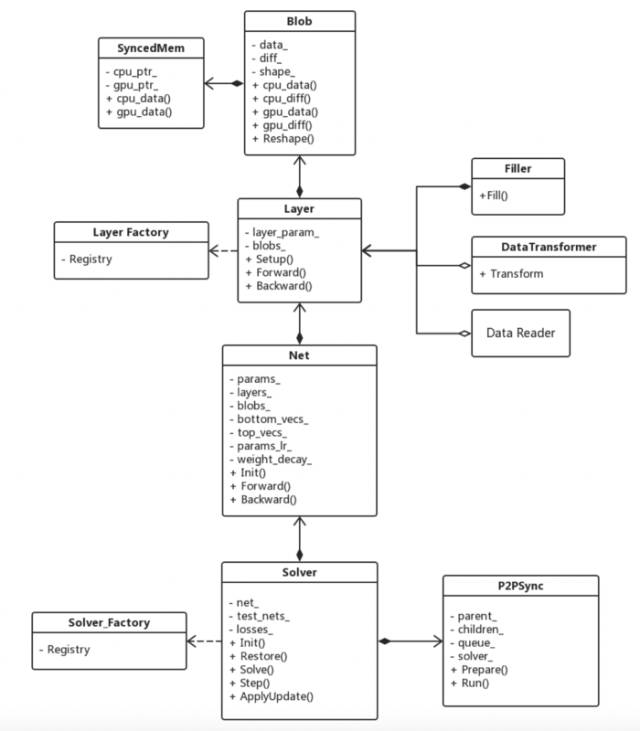
最后放一張Caffe源代碼的架構圖,以方便大家研究Caffe源碼。
作者介紹馮超,畢業于中國科學院大學,現就職于猿輔導公司,從事視覺與深度學習的應用研究工作。自2016年起在知乎開設了自己的專欄——《無痛的機器學習》(https://zhuanlan.zhihu.com/hsmyy),發表一些機器學習和深度學習的文章,收到了不錯的反響。











