機器學習從入門到精通

前言
回憶起來,AndrewNg 在coursera上開設的機器學習課程受益匪淺,課程覆蓋了機器學習的基礎內容,深入淺出,把很多概念解釋得很到位。現在將其課件和內容進行總結和梳理,主要是因為課程確實非常好,再者也是對學習過程的一個回顧總結,其中也會加入本人的一些思考。如果有興趣,最好是可以對課程進行系統的學習將對應的習題和小測都做一遍,收獲會更大。由于課程的代碼不能公開,因此本文不會對實踐部分進行多加闡述,如果有可能,本人會加入一些公開的實踐樣例。
Introduction
本部門主要對機器學習的基本概念以及相關的方法分類進行一個概要的介紹。進行的拓展主要在于總結和科普,沒有進行詳細詳細的展開,后續會進一步進行展開或總結。
1. 機器學習的定義
ArthurSamuel(1959).MachineLearning:Fieldof study that gives computers the ability to learn without being explicitly programmed.
TomMitchell(1998)Well-posedLearning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
以上兩個定義中,普遍使用的后者。在進行機器學習的建模過程中,我們首要的任務是確定好三個基本要素,即經驗(experience,E)、任務(task, T)和效果(performance, P)。學習是基于歷史經驗(E)的,直觀的表現為采集的歷史數據,學習的過程要針對特定的任務(T),即目的(比如說需要對郵件進行分類),候選的能夠擬合給定歷史數據的模型假設有很多,如何挑選出好的假設,就需要定義好評估的標準(P)。
舉個例子,對郵件進行分類,假設分成兩類,即正常郵件和垃圾郵件,那么:
E: 事先采集好的一系列郵件
T: 將郵件分成兩類:正常郵件和垃圾郵件
P: 正常分類的百分比
2. 機器學習方法分類
機器學習方法可以大致分為:監督學習(supervised learning)和非監督學習(unsupervised learning),其最主要的區別在于我們是否可以實現獲取到所學目標的分類。
2.1.監督學習:
對于任意樣本,我們知道其目標值,通常也稱為類標,當目標值是離散的,則是分類問題,當目標值是連續的,那么就是回歸問題。
對于任意實例 (x,y),x為向量,通常稱為特征向量,每一個維度表示目標的一個屬性,y為目標值,即實例的類標,當y為離散值時是分類問題,y為連續值是回歸問題。
分類問題,如圖1所示。假設樣本實例為一些列的患者,我們希望給予兩個屬性,即x1(腫瘤大小)和x2(腫瘤個數),來對患者是否患有癌癥進行預測。每一個患者用表示為圖中一點,![]() 表示一類(非癌癥患者),
表示一類(非癌癥患者),![]() 表示一類(癌癥患者)。有監督的學習過程是基于有類標的數據(通常稱為訓練集)將出一個分類面,通常稱為假設h(x)=y,此處y=1(癌癥患者)或y=0(非癌癥患者),將訓練集劃分成兩類。當新數據到來時,根據學習的假設h(x)可以對患者是否患癌癥作出預測。
表示一類(癌癥患者)。有監督的學習過程是基于有類標的數據(通常稱為訓練集)將出一個分類面,通常稱為假設h(x)=y,此處y=1(癌癥患者)或y=0(非癌癥患者),將訓練集劃分成兩類。當新數據到來時,根據學習的假設h(x)可以對患者是否患癌癥作出預測。
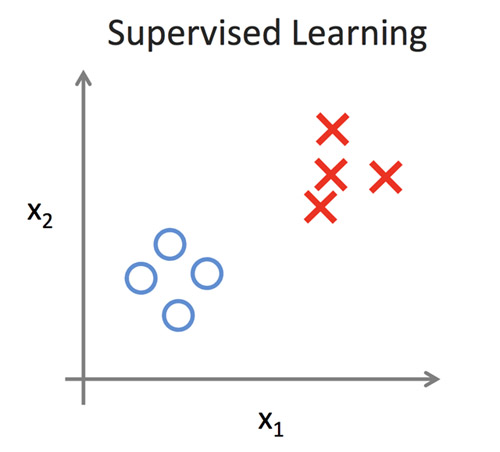
圖1
回歸問題,如圖2所示,假設我們希望對房子的價錢進行預測。圖中我們已經采集了一系列樣本,每個![]() 表示一個樣本,我們希望能夠學習出房子大小和價錢的關系,h(x)=y,此處特征向量只有一個值,即房子的大小,而目標值為房子的價錢。可以看到,能夠擬合樣本的曲線不止一條(藍色曲線和紅色曲線),這就涉及到判斷哪個假設更好的問題,通常稱為模型選擇。
表示一個樣本,我們希望能夠學習出房子大小和價錢的關系,h(x)=y,此處特征向量只有一個值,即房子的大小,而目標值為房子的價錢。可以看到,能夠擬合樣本的曲線不止一條(藍色曲線和紅色曲線),這就涉及到判斷哪個假設更好的問題,通常稱為模型選擇。
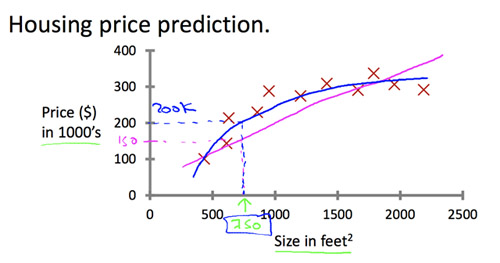
圖2
2.2.非監督學習
非監督學習中,我們無法事先獲取到樣本的類標,即如圖3所示,每個![]() 表示一個樣本,很明顯樣本可以劃分成兩個蔟,這兩個蔟之間相距很遠,但蔟內各樣本點之間很近。聚類是非監督學習的典型,而關鍵在于距離函數的定義,即如何衡量樣本之間的相近程度,一般我們認為距離相近的兩個樣本點屬于一個蔟。常用的聚類算法有k-mean,dbscan等。
表示一個樣本,很明顯樣本可以劃分成兩個蔟,這兩個蔟之間相距很遠,但蔟內各樣本點之間很近。聚類是非監督學習的典型,而關鍵在于距離函數的定義,即如何衡量樣本之間的相近程度,一般我們認為距離相近的兩個樣本點屬于一個蔟。常用的聚類算法有k-mean,dbscan等。
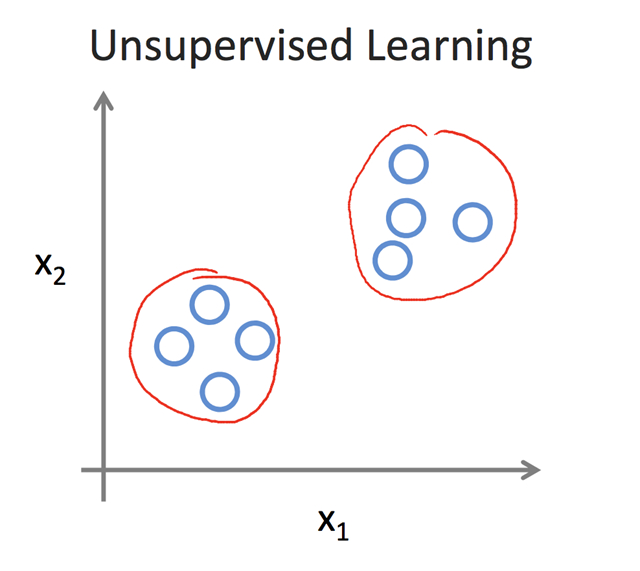
圖3
3.其他概念
這里稍微概括的介紹一下機器學習中的一些重要概念。
[1] 半監督學習
半監督學習介于監督學習和非監督學習之間。監督學習的訓練集是打了類標的,即我們事先知道樣本中的郵件是否為垃圾郵件,基于這一經驗來對模型進行訓練;而非監督學習的訓練集是不知道類標的,我們只能基于某種相似性或是結構特征將樣本分成不同的蔟。現實生活中我們很難獲取到大量的標記數據,通過人工大類標也是費時費力的,因此就有了半監督學習方法的提出,其核心思想是,我們先通過少量的標記數據來訓練模型,然后基于某種方法將未標記的數據也用上,對模型進行自動的進一步的優化。
[2] 主動學習
主動學習與半監督學習有點相似,半監督學習期望自動的利用未標記數據進行學習,而主動學習則可以看成是半自動的利用未標記的數據。其核心思想是,利用少量的標記數據訓練模型,基于當前模型嘗試對未標記的數據進行標記,如果模型對當前標記的結果把握不大,則可以對人發起幫助請求,詢問當前樣例的類標,通過人的反饋對模型進行優化,而對于把握大的結果則不發出詢問。
[3] 增強學習 (reinforcement learning)
增強學習是一個交互學習的過程,通常用馬爾可夫決策過程來描述,其核心在于打分機制。以下棋為例子進行說明,每個棋局表示一個狀態,在當前狀態有不同的下法,即下一個棋子應該如何走,每一種策略都會將當前狀態轉換到下一狀態,假設為x1,x2,…,xn,對于每一個轉換造成的后果我們給予一個分數,分數表明了贏的可能性,那么在下棋過程以貪心的策略選擇分數最高的策略。
[4] 集成學習 (ensemble learning)
集成學習的核心思想是將多個弱的分類器集合成一個強的分類器。打個比方,小明要去看病,看是否發燒,為了更準確,小明看了5個大夫,其中有4個大夫說小明沒有發燒,只有1個大夫說小明發燒了,綜合來看,如果每個大夫各有一票,最后少數服從多數,小明應該是沒有發燒。
在機器學習中也是如此,我們通常希望將多個分類器集合起來,綜合各個分類器的結果作出最后的預測。最簡單的就是投標機制,少數服從多數。假設訓練有k個分類器,對于任意實例,同時輸入到k個分類器中,獲取k個預測結果,依據少數服從多數的原則對實例進行分類。
[5] 模型選擇 (model selection)
在機器學習中,能夠反映歷史經驗的模型有很多,如圖2所示,能擬合數據的有兩條曲線,那么如何從眾多候選中選出好的模型是一個很重要的話題。我們希望一個好的模型,不但在訓練集(見過的數據)上具有很好的效果,我們還希望其對未見過的數據也具有很好的預測效果,即具有好的泛化能力。此處涉及到兩個重要名詞,即過擬合和欠擬合。欠擬合是指模型在所有數據上(見過的和未見過的)數據上表現都很差,沒有能夠很好的抽象模型。過擬合是指模型在見過的數據上表現很好,但對未見過的數據上表現很差,也就是模型通過擬合極端的數據來獲取好的效果,學習的模型太過于具體,以至于對未見過的數據沒有預測能力。我們通常會使用精確度來衡量預測的結果的好壞。保證預測精度還不夠,同等條件下我們更偏向于簡單的模型,這就是著名的奧卡姆剃刀原則(Occam’s Razor),”An explanation of the data should be mad as simple as possible,but no simpler”。
綜上所述,模型選擇過程中考慮的方向主要有兩個:預測結果的好壞(比如準確率)和模型的復雜程度。
[6] 特征選擇 (feature selection)
如圖1的例子,患者是否患有癌癥的分類問題,我們考慮腫瘤的大小和腫瘤數量兩個特征;如圖2例子,房價的預測我們考慮房子大小的特征。特征的好壞,以及與目標的相關程度都在很大程度上影響了模型學習的效果。如果特征不足,或者與目標相關不大,學習出的模型很容易欠擬合。如果無關的特征過多會引起維度災難,影響學習過程的效率。深度學習的效果好,是因為其隱藏層對特征具有很好的抽象作用。因此在進行模型學習的過程中,特征的選擇也是很重要的課題。常用的特征選擇方法有PCA,即主成分分析。