HBase更優實踐-用好你的操作系統
終于又切回HBase模式了,之前一段時間因為工作的原因了解接觸了一段時間大數據生態的很多其他組件(諸如Parquet、Carbondata、Hive、SparkSQL、TPC-DS/TPC-H等),雖然只是走馬觀花,但也受益良多。對視野、思維模式都有極其重要的作用,至少,擴展了大數據領域的對話圈。這里也斗膽建議朋友能在深入研究一門學問的同時博覽周邊學問,相信必然會大有裨益。
來說正題,操作系統這個話題其實很早就想拿出來和大家分享,拖到現在一方面是因為對其中各種理論理解并不十分透徹,怕講不好;另一方面是這個問題好像一直以來都很少有人關注,這里算是給這個話題開個頭。其實這幾個參數前前后后看過好些次,但卻一直沒有吃透,前段時間趁著休假又把這些理論翻出來過了一遍,有了進一步的理解,這里權當整理梳理。下圖是HBase官方文檔上對操作系統環境的幾點配置要求:

先不著急解釋每個配置的具體含義,在這之前需要重點研究一個概念:swap,對,就這個大家或多或少聽說過的名詞,負責任的說,上述幾個參數或多或少都與swap有些關聯。
swap是干嘛的?
在Linux下,SWAP的作用類似Windows系統下的“虛擬內存”。當物理內存不足時,拿出部分硬盤空間當SWAP分區(虛擬成內存)使用,從而解決內存容量不足的情況。
SWAP意思是交換,顧名思義,當某進程向OS請求內存發現不足時,OS會把內存中暫時不用的數據交換出去,放在SWAP分區中,這個過程稱為SWAP OUT。當某進程又需要這些數據且OS發現還有空閑物理內存時,又會把SWAP分區中的數據交換回物理內存中,這個過程稱為SWAP IN。
當然,swap大小是有上限的,一旦swap使用完,操作系統會觸發OOM-Killer機制,把消耗內存最多的進程kill掉以釋放內存。
數據庫系統為什么嫌棄swap?
顯然,swap機制的初衷是為了緩解物理內存用盡而選擇直接粗暴OOM進程的尷尬。但坦白講,幾乎所有數據庫對swap都不怎么待見,無論MySQL、Oracal、MongoDB抑或HBase,為什么?這主要和下面兩個方面有關:
1. 數據庫系統一般都對響應延遲比較敏感,如果使用swap代替內存,數據庫服務性能必然不可接受。對于響應延遲極其敏感的系統來講,延遲太大和服務不可用沒有任何區別,比服務不可用更嚴重的是,swap場景下進程就是不死,這就意味著系統一直不可用……再想想如果不使用swap直接oom,是不是一種更好的選擇,這樣很多高可用系統直接會主從切換掉,用戶基本無感知。
2. 另外對于諸如HBase這類分布式系統來說,其實并不擔心某個節點宕掉,而恰恰擔心某個節點夯住。一個節點宕掉,最多就是小部分請求短暫不可用,重試即可恢復。但是一個節點夯住會將所有分布式請求都夯住,服務器端線程資源被占用不放,導致整個集群請求阻塞,甚至集群被拖垮。
從這兩個角度考慮,所有數據庫都不喜歡swap還是很有道理的!
swap的工作機制
既然數據庫們對swap不待見,那是不是就要使用swapoff命令關閉磁盤緩存特性呢?非也,大家可以想想,關閉磁盤緩存意味著什么?實際生產環境沒有一個系統會如此激進,要知道這個世界永遠不是非0即1的,大家都會或多或少選擇走在中間,不過有些偏向0,有些偏向1而已。很顯然,在swap這個問題上,數據庫必然選擇偏向盡量少用。HBase官方文檔的幾點要求實際上就是落實這個方針:盡可能降低swap影響。知己知彼才能百戰不殆,要降低swap影響就必須弄清楚Linux內存回收是怎么工作的,這樣才能不遺漏任何可能的疑點。
先來看看swap是如何觸發的?
簡單來說,Linux會在兩種場景下觸發內存回收,一種是在內存分配時發現沒有足夠空閑內存時會立刻觸發內存回收;一種是開啟了一個守護進程(swapd進程)周期性對系統內存進行檢查,在可用內存降低到特定閾值之后主動觸發內存回收。***種場景沒什么可說,來重點聊聊第二種場景,如下圖所示:
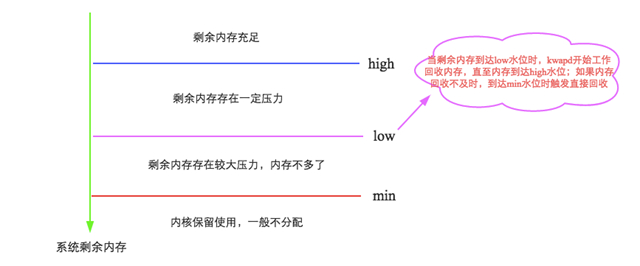
這里就要引出我們關注的***個參數:vm.min_free_kbytes,代表系統所保留空閑內存的***限watermark[min],并且影響watermark[low]和watermark[high]。簡單可以認為:
- watermark[min] = min_free_kbytes
- watermark[low] = watermark[min] * 5 / 4 = min_free_kbytes * 5 / 4
- watermark[high] = watermark[min] * 3 / 2 = min_free_kbytes * 3 / 2
- watermark[high] - watermark[low] = watermark[low] - watermark[min] = min_free_kbytes / 4
可見,LInux的這幾個水位線與參數min_free_kbytes密不可分。min_free_kbytes對于系統的重要性不言而喻,既不能太大,也不能太小。
min_free_kbytes如果太小,[min,low]之間水位的buffer就會很小,在kswapd回收的過程中一旦上層申請內存的速度太快(典型應用:數據庫),就會導致空閑內存極易降至watermark[min]以下,此時內核就會進行direct reclaim(直接回收),直接在應用程序的進程上下文中進行回收,再用回收上來的空閑頁滿足內存申請,因此實際會阻塞應用程序,帶來一定的響應延遲。當然,min_free_kbytes也不宜太大,太大一方面會導致應用程序進程內存減少,浪費系統內存資源,另一方面還會導致kswapd進程花費大量時間進行內存回收。再看看這個過程,是不是和Java垃圾回收機制中CMS算法中老生代回收觸發機制神似,想想參數-XX:CMSInitiatingOccupancyFraction,是不是?官方文檔中要求min_free_kbytes不能小于1G(在大內存系統中設置8G),就是不要輕易觸發直接回收。
至此,基本解釋了Linux的內存回收觸發機制以及我們關注的***個參數vm.min_free_kbytes。接下來簡單看看Linux內存回收都回收些什么。Linux內存回收對象主要分為兩種:
1. 文件緩存,這個容易理解,為了避免文件數據每次都要從硬盤讀取,系統會將熱點數據存儲在內存中,提高性能。如果僅僅將文件讀出來,內存回收只需要釋放這部分內存即可,下次再次讀取該文件數據直接從硬盤中讀取即可(類似HBase文件緩存)。那如果不僅將文件讀出來,而且對這些緩存的文件數據進行了修改(臟數據),回收內存就需要將這部分數據文件寫會硬盤再釋放(類似MySQL文件緩存)。
2. 匿名內存,這部分內存沒有實際載體,不像文件緩存有硬盤文件這樣一個載體,比如典型的堆、棧數據等。這部分內存在回收的時候不能直接釋放或者寫回類似文件的媒介中,這才搞出來swap這個機制,將這類內存換出到硬盤中,需要的時候再加載出來。
具體Linux使用什么算法來確認哪些文件緩存或者匿名內存需要被回收掉,這里并不關心,有興趣可以參考這里。但是有個問題需要我們思考:既然有兩類內存可以被回收,那么在這兩類內存都可以被回收的情況下,Linux到底是如何決定到底是回收哪類內存呢?還是兩者都會被回收?這里就牽出來了我們第二個關心的參數:swappiness,這個值用來定義內核使用swap的積極程度,值越高,內核就會積極地使用swap,值越低,就會降低對swap的使用積極性。該值取值范圍在0~100,默認是60。這個swappiness到底是怎么實現的呢?具體原理很復雜,簡單來講,swappiness通過控制內存回收時,回收的匿名頁更多一些還是回收的文件緩存更多一些來達到這個效果。swappiness等于100,表示匿名內存和文件緩存將用同樣的優先級進行回收,默認60表示文件緩存會優先被回收掉,至于為什么文件緩存要被優先回收掉,大家不妨想想(回收文件緩存通常情況下不會引起IO操作,對系統性能影響較小)。對于數據庫來講,swap是盡量需要避免的,所以需要將其設置為0。此處需要注意,設置為0并不代表不執行swap哦!
至此,我們從Linux內存回收觸發機制、Linux內存回收對象一直聊到swap,將參數min_free_kbytes以及swappiness進行了解釋。接下來看看另一個與swap有關系的參數:zone_reclaim_mode,文檔說了設置這個參數為0可以關閉NUMA的zone reclaim,這又是怎么回事?提起NUMA,數據庫們又都不高興了,很多DBA都曾經被坑慘過。那這里簡單說明三個小問題:NUMA是什么?NUMA和swap有什么關系?zone_reclaim_mode的具體意義?
NUMA(Non-Uniform Memory Access)是相對UMA來說的,兩者都是CPU的設計架構,早期CPU設計為UMA結構,如下圖(圖片來自網絡)所示:
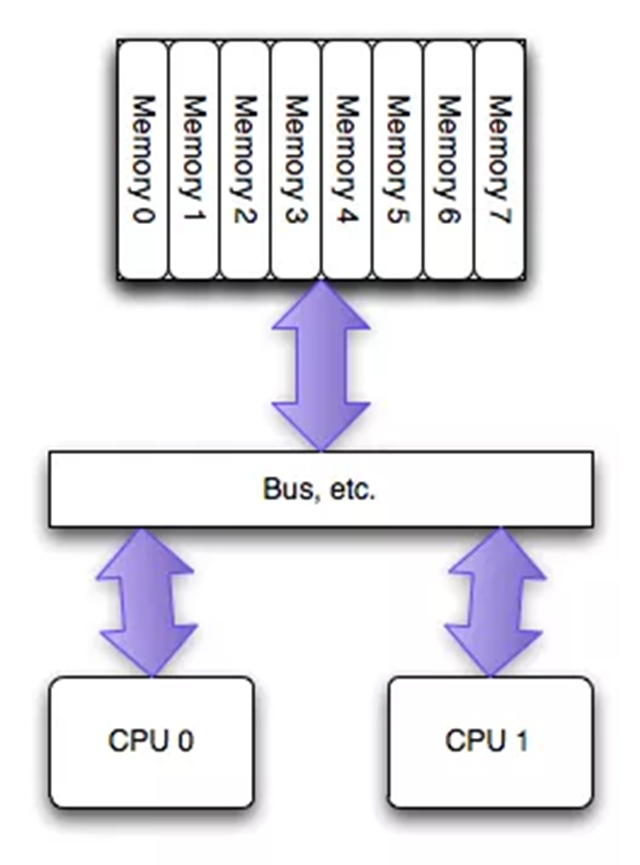
為了緩解多核CPU讀取同一塊內存所遇到的通道瓶頸問題,芯片工程師又設計了NUMA結構,如下圖(圖片來自網絡)所示:
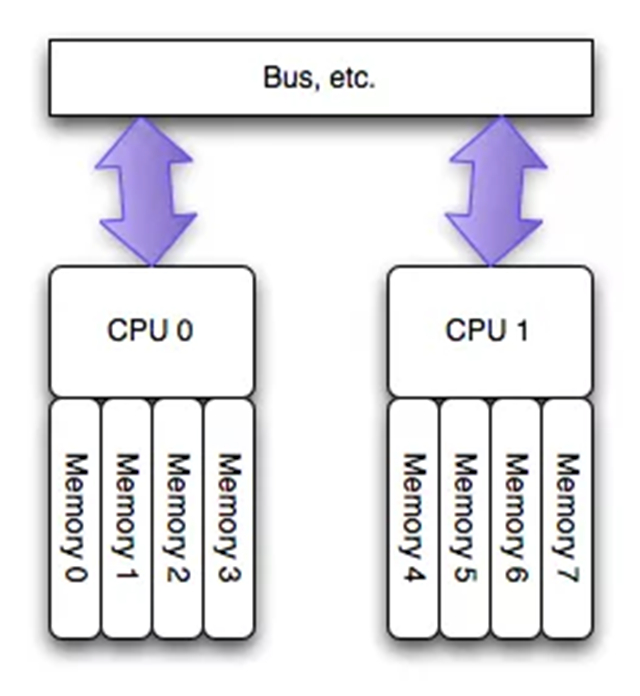
這種架構可以很好解決UMA的問題,即不同CPU有專屬內存區,為了實現CPU之間的”內存隔離”,還需要軟件層面兩點支持:
1. 內存分配需要在請求線程當前所處CPU的專屬內存區域進行分配。如果分配到其他CPU專屬內存區,勢必隔離性會受到一定影響,并且跨越總線的內存訪問性能必然會有一定程度降低。
2. 另外,一旦local內存(專屬內存)不夠用,優先淘汰local內存中的內存頁,而不是去查看遠程內存區是否會有空閑內存借用。
這樣實現,隔離性確實好了,但問題也來了:NUMA這種特性可能會導致CPU內存使用不均衡,部分CPU專屬內存不夠使用,頻繁需要回收,進而可能發生大量swap,系統響應延遲會嚴重抖動。而與此同時其他部分CPU專屬內存可能都很空閑。這就會產生一種怪現象:使用free命令查看當前系統還有部分空閑物理內存,系統卻不斷發生swap,導致某些應用性能急劇下降。見葉金榮老師的MySQL案例分析:《找到MySQL服務器發生SWAP罪魁禍首》。
所以,對于小內存應用來講,NUMA所帶來的這種問題并不突出,相反,local內存所帶來的性能提升相當可觀。但是對于數據庫這類內存大戶來說,NUMA默認策略所帶來的穩定性隱患是不可接受的。因此數據庫們都強烈要求對NUMA的默認策略進行改進,有兩個方面可以進行改進:
1. 將內存分配策略由默認的親和模式改為interleave模式,即會將內存page打散分配到不同的CPU zone中。通過這種方式解決內存可能分布不均的問題,一定程度上緩解上述案例中的詭異問題。對于MongoDB來說,在啟動的時候就會提示使用interleave內存分配策略:
- WARNING: You are running on a NUMA machine.
- We suggest launching mongod like this to avoid performance problems:
- numactl –interleave=all mongod [other options]
2. 改進內存回收策略:此處終于請出今天的第三個主角參數zone_reclaim_mode,這個參數定義了NUMA架構下不同的內存回收策略,可以取值0/1/3/4,其中0表示在local內存不夠用的情況下可以去其他的內存區域分配內存;1表示在local內存不夠用的情況下本地先回收再分配;3表示本地回收盡可能先回收文件緩存對象;4表示本地回收優先使用swap回收匿名內存。可見,HBase推薦配置zone_reclaim_mode=0一定程度上降低了swap發生的概率。
不都是swap的事
至此,我們探討了三個與swap相關的系統參數,并且圍繞Linux系統內存分配、swap以及NUMA等知識點對這三個參數進行了深入解讀。除此之外,對于數據庫系統來說,還有兩個非常重要的參數需要特別關注:
1. IO調度策略:這個話題網上有很多解釋,在此并不打算詳述,只給出結果。通常對于sata盤的OLTP數據庫來說,deadline算法調度策略是***的選擇。
2. THP(transparent huge pages)特性關閉。THP特性筆者曾經疑惑過很久,主要疑惑點有兩點,其一是THP和HugePage是不是一回事,其二是HBase為什么要求關閉THP。經過前前后后多次查閱相關文檔,終于找到一些蛛絲馬跡。這里分四個小點來解釋THP特性:
(1)什么是HugePage?
網上對HugePage的解釋有很多,大家可以檢索閱讀。簡單來說,計算機內存是通過表映射(內存索引表)的方式進行內存尋址,目前系統內存以4KB為一個頁,作為內存尋址的最小單元。隨著內存不斷增大,內存索引表的大小將會不斷增大。一臺256G內存的機器,如果使用4KB小頁, 僅索引表大小就要4G左右。要知道這個索引表是必須裝在內存的,而且是在CPU內存,太大就會發生大量miss,內存尋址性能就會下降。
HugePage就是為了解決這個問題,HugePage使用2MB大小的大頁代替傳統小頁來管理內存,這樣內存索引表大小就可以控制的很小,進而全部裝在CPU內存,防止出現miss。
(2)什么是THP(Transparent Huge Pages)?
HugePage是一種大頁理論,那具體怎么使用HugePage特性呢?目前系統提供了兩種使用方式,其一稱為Static Huge Pages,另一種就是Transparent Huge Pages。前者根據名稱就可以知道是一種靜態管理策略,需要用戶自己根據系統內存大小手動配置大頁個數,這樣在系統啟動的時候就會生成對應個數的大頁,后續將不再改變。而Transparent Huge Pages是一種動態管理策略,它會在運行期動態分配大頁給應用,并對這些大頁進行管理,對用戶來說完全透明,不需要進行任何配置。另外,目前THP只針對匿名內存區域。
(3)HBase(數據庫)為什么要求關閉THP特性?
THP是一種動態管理策略,會在運行期分配管理大頁,因此會有一定程度的分配延時,這對追求響應延時的數據庫系統來說不可接受。除此之外,THP還有很多其他弊端,可以參考這篇文章《why-tokudb-hates-transparent-hugepages》
(4)THP關閉/開啟對HBase讀寫性能影響有多大?
為了驗證THP開啟關閉對HBase性能的影響到底有多大,本人在測試環境做了一個簡單的測試:測試集群僅一個RegionServer,測試負載為讀寫比1:1。THP在部分系統中為always以及never兩個選項,在部分系統中多了一個稱為madvise的選項。可以使用命令 echo never/always > /sys/kernel/mm/transparent_hugepage/enabled 來關閉/開啟THP。測試結果如下圖所示:
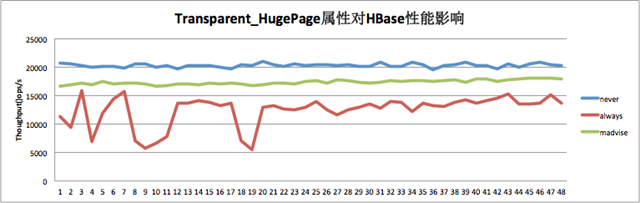
如上圖,TPH關閉場景下(never)HBase性能***,比較穩定。而THP開啟的場景(always),性能相比關閉的場景有30%左右的下降,而且曲線抖動很大。可見,HBase線上切記要關閉THP。
總結
任何數據庫系統的性能表現都與諸多因素相關,這里面有數據庫本身的各種因素,比如數據庫配置、客戶端使用、容量規劃、表scheme設計等,除此之外,基礎系統對其的影響也至關重要,比如操作系統、JVM等。很多時候數據庫遇到一些性能問題,左查右查都定位不了具體原因,這個時候就要看看操作系統的配置是否都合理了。本文從HBase官方文檔要求的幾個參數出發,詳細說明了這些參數的具體意義。