Serverless架構實踐初探
隨著云計算技術的進步,軟件系統的架構方式也因此發生著一些變化,其中Serverless架構就是這里的一個典型的例子。
一、什么是Serverless架構
目前關于Serverless架構的準確定義,業界并沒有一個統一的標準。那么我們從字面上來分析,所謂Serverless架構,翻譯過來也就是無服務器架構。那么似乎可以涵蓋以下兩個方面:
- BaaS(Backend as a Service)即后臺即服務。后臺即服務出現有很長一段的時間了,例如Parse,Firebase都是典型的代表。具體來說就是服務器端的邏輯和狀態是完全依賴于云平臺進行管理的。
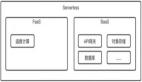
- FaaS(Function as a Service)即函數即服務。函數即服務,意味著這些函數中的后臺邏輯是由我們開發者自己實現的。但是這些函數是執行在一個無狀態的計算容器中的,函數的執行是基于事件驅動的,關于這些函數的部署、執行、觸發是由云平臺來管理的。其最典型的例子就是AWS Lambda。
我們這篇文章中的所討論的Serverless,是指的第二種,也就是FaaS。在我們Thoughtworks***一期的技術雷達中,Serverless架構位于試驗象限,下文就介紹下我們在Serverless架構下的一些實踐經驗。
二、數據處理業務的Serverless架構演進
所謂的數據處理業務,是指我們的系統需要每天定時獲取一些外部數據與我們自身的數據結合,生成一些數據報表。那么最初我們是怎么設計技術方案的呢?
1. 傳統架構方式

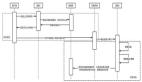
我們將業務拆分為3個獨立的服務,2個Data Collector,1個Data Loader,都分別部署在AWS服務器上,將中間數據存儲在一個外部S3(AWS的數據存儲)上。***將數據保存在數據庫中,在數據庫之上使用專門的BI工具來制作報表。
我們***個數據服務就是按照這樣的架構進行設計和實踐的。當系統上線服務以后,我們發現了里邊的一些問題。
在這套系統中,Data Collector 2每天的執行時間較長,需要1個小時左右的時間,而Data Collector 1每天的執行時間較短,通常執行時間不會超過1分鐘,但是由于外部數據源的更新時間是不確定的,所以雖然我們服務實際有效時間只有僅僅一到兩分鐘,但是也不得不讓服務器全天運行。
可以看到,這個系統每天的有效時間只有一個小時,其他23個小時實際上是在浪費資源,如何改善這樣的情況呢?首先想到了讓服務定點運行的方法。由于我們外服數據源的更新特點,雖然它的更新時間是不確定的,但是它在某個特定的時間點前是一定會更新的。基于這樣的前提,我們將服務運行時間改為定點運行,這樣是不是就能解決問題了呢?
然而現實并不總是那么美好,因為我們服務間是有依賴關系的,Data Loader是依賴于我們Data Collector的處理結果的,當我們把運行方式改為定點運行后,帶來的問題是,一旦Data Collector的運行狀態出現了問題,例如運行時間過長,運行中出現錯誤,那么Data Loader必然出錯。同時改為定點運行后,我們的數據更新必然有延遲。
那么如何解決這些問題呢?
2. Serverless的系統架構

我們引入了Lambda,將Data Collector 和 Data Loader用Lambda進行了替換,帶來了下面這些好處:
由于Lambda是由事件驅動的,S3上一個數據的變化可以觸發一個事件,SNS的一條消息可以觸發一個時間等等,在使用Lambda后,我們就可以講原來基于時間的數據處理流程,轉變為基于事件的數據處理流程,這樣一方面可以保證我們數據更新的實時性,另一方面可以大大節省資源,由于Lambda是按照觸發次數收費的,所以在我們的這個用例下,可以大大減少花費。
可能細心的讀者想問為什么我們Data Collector 2沒有使用Lambda進行替換呢?這是因為它的業務邏輯比較復雜,每次運行的時間較長,而Lambda的最長執行時間是5分鐘,所以在這種情況下,就不適合使用Lambda進行替換了。
3. 實時數據處理下的Serverless架構
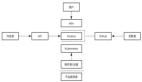
在初識Serverless架構的好處之后,我們開始在其他方面的應用嘗試,比較典型的一個例子就是在實時數據處理業務下的Serverless架構。在我們業務下,我們需要實時跟蹤一個外部的數據源API,根據它的數據變化來實時更新我們的數據。

在我們的架構設計中,我們使用一個Lambda來跟蹤外部數據源的數據變化,并將其推到AWS Kinesis Stream里,AWS Kinesis會觸發第二個Lambda進行相應的數據處理,并把數據存儲到數據庫中,值得注意的是由于Lambda是可以根據需求自動伸縮的,所以Lambda會根據Kinesis的需求來自動擴展。這就體現了Serverless架構下的另一個好處,可以相對簡單的,自動進行伸縮擴展。
4. Web系統的Serverless架構
對于Web系統這種我們最為熟悉和常見的IT系統來說,它能不能用Serverless的架構來實現呢?我們來看下邊的例子。我們先來看看傳統的例子。

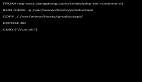
在傳統實現中,我們會利用Load Blancer來做負載均衡,然后后續的應用會部署在AutoScaling Group中,根據流量來做自動伸縮,這種模式已經是十分成熟了。那么在Serverless的架構下該如何設計呢?

在Serverless架構下,一般我們的前端應用的資源文件包括Html,JS,CSS,都是部署在S3(AWS的文件存儲)上的。前端應用通過AJAX請求向后臺請求數據。后臺通過API GateWay定義對外的Endpoint,同時每個Endpoint會觸發一個Lambda進行數據操作,例如圖中的GET,和POST請求會觸發兩個不同Lambda。這樣的Serverless架構可以讓開發者不必擔心水平擴展的問題。
三、Serverless架構的未來
目前AWS Lambda似乎已經成為了Serverless的代名詞,為了幫助開發者更好的構建Serverless應用,市場上出現了一些工具和框架,例如Serverless Framework。但是同樣我們還可以看到一些其他的云平臺和開源框架也在提供類似的服務,例如webtask,OpenWhisk,以及其在IBM Bluemix上的實現。
Serverless架構作為一種新的架構方式,還在不斷的發展中。希望本文能給您帶來一些思考。
【本文是51CTO專欄作者“ThoughtWorks”的原創稿件,微信公眾號:思特沃克,轉載請聯系原作者】