典型數(shù)據(jù)庫架構設計與實踐
本文為了便于讀者理解,將以“用戶中心”數(shù)據(jù)庫為例,講解數(shù)據(jù)庫架構設計的常見玩法。
一、用戶中心
用戶中心是一個常見業(yè)務,主要提供用戶注冊、登錄、信息查詢與修改的服務,其核心元數(shù)據(jù)為:
- User(uid, uname, passwd, sex, age,nickname, …)
其中:
- uid為用戶ID,主鍵
- uname, passwd, sex, age, nickname, …等為用戶的屬性
數(shù)據(jù)庫設計上,一般來說在業(yè)務初期,單庫單表就能夠搞定這個需求。
二、圖示說明
為了方便大家理解,后文圖片說明較多,其中:
- “灰色”方框,表示service,服務
- “紫色”圓框,標識master,主庫
- “粉色”圓框,表示slave,從庫
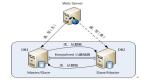
三、單庫架構

最常見的架構設計如上:
- user-service:用戶中心服務,對調(diào)用者提供友好的RPC接口
- user-db:一個庫進行數(shù)據(jù)存儲
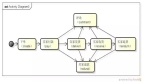
四、分組架構
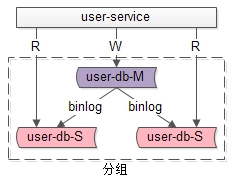
什么是分組?
答:分組架構是最常見的一主多從,主從同步,讀寫分離數(shù)據(jù)庫架構:
- user-service:依舊是用戶中心服務
- user-db-M(master):主庫,提供數(shù)據(jù)庫寫服務
- user-db-S(slave):從庫,提供數(shù)據(jù)庫讀服務
主和從構成的數(shù)據(jù)庫集群稱為“組”。
分組有什么特點?
答:同一個組里的數(shù)據(jù)庫集群:
- 主從之間通過binlog進行數(shù)據(jù)同步
- 多個實例數(shù)據(jù)庫結構完全相同
- 多個實例存儲的數(shù)據(jù)也完全相同,本質(zhì)上是將數(shù)據(jù)進行復制
分組架構究竟解決什么問題?
答:大部分互聯(lián)網(wǎng)業(yè)務讀多寫少,數(shù)據(jù)庫的讀往往***成為性能瓶頸,如果希望:
- 線性提升數(shù)據(jù)庫讀性能
- 通過消除讀寫鎖沖突提升數(shù)據(jù)庫寫性能
- 通過冗余從庫實現(xiàn)數(shù)據(jù)的“讀高可用”
此時可以使用分組架構,需要注意的是,分組架構中,數(shù)據(jù)庫的主庫依然是寫單點。
一句話總結,分組解決的是“數(shù)據(jù)庫讀寫高并發(fā)量高”問題,所實施的架構設計。
五、分片架構

什么是分片?
答:分片架構是大伙常說的水平切分(sharding)數(shù)據(jù)庫架構:
- user-service:依舊是用戶中心服務
- user-db1:水平切分成2份中的***份
- user-db2:水平切分成2份中的第二份
分片后,多個數(shù)據(jù)庫實例也會構成一個數(shù)據(jù)庫集群。
水平切分,到底是分庫還是分表?
答:強烈建議分庫,而不是分表,因為:
- 分表依然公用一個數(shù)據(jù)庫文件,仍然有磁盤IO的競爭
- 分庫能夠很容易的將數(shù)據(jù)遷移到不同數(shù)據(jù)庫實例,甚至數(shù)據(jù)庫機器上,擴展性更好
水平切分,用什么算法?
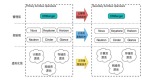
答:常見的水平切分算法有“范圍法”和“哈希法”:

范圍法如上圖:以用戶中心的業(yè)務主鍵uid為劃分依據(jù),將數(shù)據(jù)水平切分到兩個數(shù)據(jù)庫實例上去:
- user-db1:存儲0到1千萬的uid數(shù)據(jù)
- user-db2:存儲0到2千萬的uid數(shù)據(jù)

哈希法如上圖:也是以用戶中心的業(yè)務主鍵uid為劃分依據(jù),將數(shù)據(jù)水平切分到兩個數(shù)據(jù)庫實例上去:
- user-db1:存儲uid取模得1的uid數(shù)據(jù)
- user-db2:存儲uid取模得0的uid數(shù)據(jù)
這兩種方法在互聯(lián)網(wǎng)都有使用,其中哈希法使用較為廣泛。
分片有什么特點?
答:同一個分片里的數(shù)據(jù)庫集群:
- 多個實例之間本身不直接產(chǎn)生聯(lián)系,不像主從間有binlog同步
- 多個實例數(shù)據(jù)庫結構,也完全相同
- 多個實例存儲的數(shù)據(jù)之間沒有交集,所有實例間數(shù)據(jù)并集構成全局數(shù)據(jù)
分片架構究竟解決什么問題?
答:大部分互聯(lián)網(wǎng)業(yè)務數(shù)據(jù)量很大,單庫容量容易成為瓶頸,此時通過分片可以:
- 線性提升數(shù)據(jù)庫寫性能,需要注意的是,分組架構是不能線性提升數(shù)據(jù)庫寫性能的
- 降低單庫數(shù)據(jù)容量
一句話總結,分片解決的是“數(shù)據(jù)庫數(shù)據(jù)量大”問題,所實施的架構設計。
六、分組+分片架構
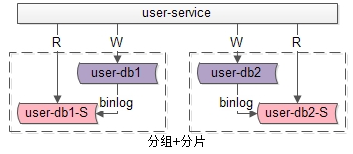
如果業(yè)務讀寫并發(fā)量很高,數(shù)據(jù)量也很大,通常需要實施分組+分片的數(shù)據(jù)庫架構:
- 通過分片來降低單庫的數(shù)據(jù)量,線性提升數(shù)據(jù)庫的寫性能
- 通過分組來線性提升數(shù)據(jù)庫的讀性能,保證讀庫的高可用
七、垂直切分
除了水平切分,垂直切分也是一類常見的數(shù)據(jù)庫架構設計,垂直切分一般和業(yè)務結合比較緊密。
據(jù)庫架構設計")
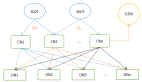
還是以用戶中心為例,可以這么進行垂直切分:
- User(uid, uname, passwd, sex, age, …)
- User_EX(uid, intro, sign, …)
- 垂直切分開的表,主鍵都是uid
- 登錄名,密碼,性別,年齡等屬性放在一個垂直表(庫)里
- 自我介紹,個人簽名等屬性放在另一個垂直表(庫)里
如何進行垂直切分?
答:根據(jù)業(yè)務對數(shù)據(jù)進行垂直切分時,一般要考慮屬性的“長度”和“訪問頻度”兩個因素:
- 長度較短,訪問頻率較高的放在一起
- 長度較長,訪問頻度較低的放在一起
這是因為,數(shù)據(jù)庫會以行(row)為單位,將數(shù)load到內(nèi)存(buffer)里,在內(nèi)存容量有限的情況下,長度短且訪問頻度高的屬性,內(nèi)存能夠load更多的數(shù)據(jù),***率會更高,磁盤IO會減少,數(shù)據(jù)庫的性能會提升。
垂直切分有什么特點?
答:垂直切分和水平切有相似的地方,又不太相同:
- 多個實例之間也不直接產(chǎn)生聯(lián)系,即沒有binlog同步
- 多個實例數(shù)據(jù)庫結構,都不一樣
- 多個實例存儲的數(shù)據(jù)之間至少有一列交集,一般來說是業(yè)務主鍵,所有實例間數(shù)據(jù)并集構成全局數(shù)據(jù)
垂直切分解決什么問題?
答:垂直切分即可以降低單庫的數(shù)據(jù)量,還可以降低磁盤IO從而提升吞吐量,但它與業(yè)務結合比較緊密,并不是所有業(yè)務都能夠進行垂直切分的。
八、總結
文章較長,希望至少記住這么幾點:
- 業(yè)務初期用單庫
- 讀壓力大,讀高可用,用分組
- 數(shù)據(jù)量大,寫線性擴容,用分片
- 屬性短,訪問頻度高的屬性,垂直拆分到一起
【本文為51CTO專欄作者“58沈劍”原創(chuàng)稿件,轉(zhuǎn)載請聯(lián)系原作者】