大前端開發(fā)者需要了解的基礎編譯原理和語言知識
在我剛剛進入大學,從零開始學習 C 語言的時候,我就不斷的從學長的口中聽到一個又一個語言,比如 C++、Java、Python、JavaScript 這些大眾的,也有 Lisp、Perl、Ruby 這些相對小眾的。一般來說,當程序員討論一門語言的時候,默認的上下文經(jīng)常是:“用 xxx 語言來完成 xxx 任務”。所以一直困擾著的我的一個問題就是,為什么完成某個任務,一定要選擇特定的語言,比如安卓開發(fā)是 Java,前端要用 JavaScript,iOS 開發(fā)使用 Objective-C 或者 Swift。這些問題的答案非常復雜,有的是技術原因,有的是歷史原因,有的會考慮成本,很難得出統(tǒng)一的結論,只能 case-by-case 的分析。這篇文章并非專門解答上述問題,而是希望通過介紹一些通用的概念,幫助讀者掌握分析問題的能力,如果這個概念在實際編程中用得到,我也會舉一些具體的例子。
在閱讀本文前,不妨思考一下這幾個問題,如果沒有頭緒,建議看完文章以后再思考一遍。如果覺得答案顯而易見,恭喜你,這篇文章并非為你準備的:
- 什么是編譯器,它以什么為分界線,分為前端和后端?
- Java 是編譯型語言還是解釋型語言,Python 呢?
- C 語言的編譯器也是 C 語言,那它怎么被編譯的?
- 目標文件的格式是什么樣的,段表、符號表、重定位表有什么作用?
- Swift 是靜態(tài)語言,為什么還有運行時庫?
- 什么是 ABI,ABI 不穩(wěn)定有什么問題?
- 什么是 WebAssembly,為什么要推出這門技術,用 C++ 代替 JavaScript 可行么?
- JavaScript 和 DOM API 是什么關系,JavaScript 可以讀寫文件么?
- C++ 代碼可以自動轉換成 Java 代碼么,任意兩種語言是否可以互轉?
- 為什么說 Python 是膠水語言,它可以用來開發(fā) iOS/Android 么?
編譯原理
就像數(shù)學是一個公理體系,從簡單的公理就能推導出各種高階公式一樣,我們從最基本的 C 語言和編譯說起。
- int main(void) {
- int a = strlen("Hello world"); // 字符串的長度是 11
- return 0;
- }
相關的介紹編譯過程的文章很多,讀者應該都非常熟悉了,整個流程包括預處理、詞法分析、語法分析、生成中間代碼,生成目標代碼,匯編,鏈接 等。已有的文章大多分析了每一步的邏輯,但很少談實現(xiàn)思路,我會盡量用簡單的語言來描述每一步的實現(xiàn)思路,相信這樣有助于加深記憶。由于主要談的概念和思路,難免會有一些不夠準確的抽象,讀者學會抓重點就行。
預處理是一個獨立的模塊,它放在***介紹,我們先看詞法分析。
詞法分析
***登場的是編譯器,它負責前五個步驟,也就是說編譯器的輸入是源代碼,輸出是中間代碼。
編譯器不能像人一樣,一眼就看明白源代碼的內(nèi)容,它只能比較傻的逐個單詞分析。詞法分析要做的就是把源代碼分割開,形成若干個單詞。這個過程并不像想象的那么簡單。比如舉幾個例子:
- int t 表示一個整數(shù),而 intt 只是一個變量名。
- int a() 表示一個函數(shù)而非整數(shù) a,int a () 也是一個函數(shù)。
- a = 沒有具體價值,它可以是一個賦值語句,還可以是 a == 1 的前綴,表示一個判斷。
詞法分析的主要難點在于,前綴無法決定一個完整字符串的含義,通常需要看完整句以后才知道每個單詞的具體含義。同時,C 語言的語法也不簡單,各種關鍵字,括號,逗號,語法等等都會給詞法分析的實現(xiàn)增加難度。
詞法分析的主要實現(xiàn)原理是狀態(tài)機,它逐個讀取字符,然后根據(jù)讀到的字符的特點轉換狀態(tài)。比如這是 GCC 的詞法分析狀態(tài)機(引用自《編譯系統(tǒng)透視》):
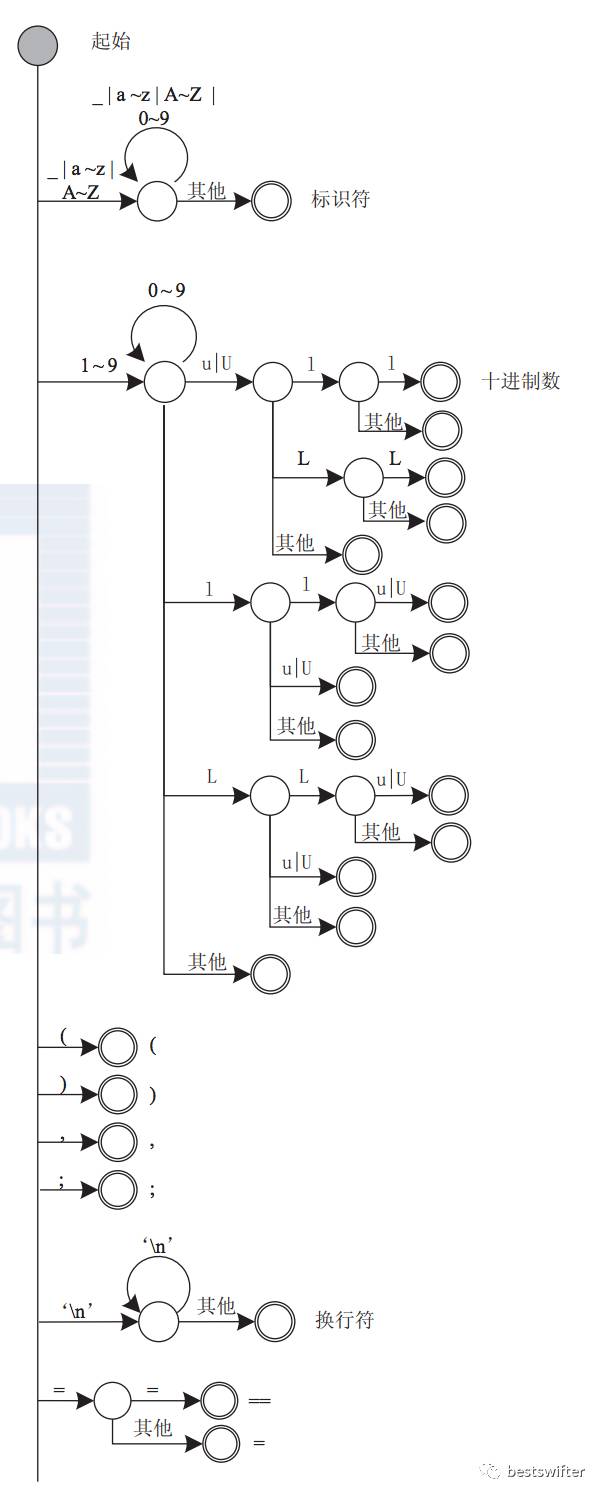
如果自己實現(xiàn)的話,思路也不難。外面包一個循環(huán),然后各種 switch...case 就完事了。詞法分析應該算是最簡單的一節(jié)。
語法分析
經(jīng)過詞法分析以后,編譯器已經(jīng)知道了每個單詞,但這些單詞組合起來表示的語法還不清楚。一個簡單的思路是模板匹配,比如有這樣的語句:
- int a = 10;
它其實表示了這么一種通用的語法格式:
類型 變量名 = 常量;
所以 int a = 10; 當然可以匹配上這種模式。同理,它不可能匹配 類型 函數(shù)名(參數(shù)); 這種函數(shù)定義模式,因為兩者結構不一致,等號無法被匹配。
語法分析比詞法分析更復雜,因為所有 C 語言支持的語法特性都必須被語法分析器正確的匹配,這個難度比純新手學習 C 語言語法難上很多倍。不過這個屬于業(yè)務復雜性,無論采用哪種解決方案都不可避免,因為語法規(guī)則的數(shù)量就是這么多。
在匹配模式的時候,另一個問題在于上述的名詞,比如 類型、參數(shù),很難界定。比如int 是類型,long long 也是類型,unsigned long long 也是類型。(int a) 可以是參數(shù),(int a, int b) 也是參數(shù),(unsigned long long a, long long double b, int *p) 看起來能把人逼瘋。
下面舉一個簡單的例子來解釋 int a = 10 是如何被解析的,總的思路是歸納與分解。我們把一個復雜的式子分割成若干部分,然后分析各個部分,這樣可以簡化復雜度。對于 int a = 10 來說,他是一個聲明,聲明由兩部分組成,分別是聲明說明符和初始聲明符列表。
| 聲明 | 聲明說明符 | 初始聲明符列表 |
|---|---|---|
| int a = 10 | int | a = 10 |
| int fun(int a) | int | fun(int a) |
| int array[5] | int | array[5] |
聲明說明符比較簡單,它其實是若干個類型的串聯(lián):
聲明說明符 = 類型 + 類型的數(shù)組(長度可以為 0)
而且我們知道若干個類型連在一起又變成了聲明說明符,所以上述等式等價于:
聲明說明符 = 類型 + 聲明說明符(可選)
再嚴謹一些,聲明說明符還可以包括 const 這樣的限定說明符,inline 這樣的函數(shù)說明符,和 _Alignas 這樣的對齊說明符。借用書中的公式,它的完整表達如下:
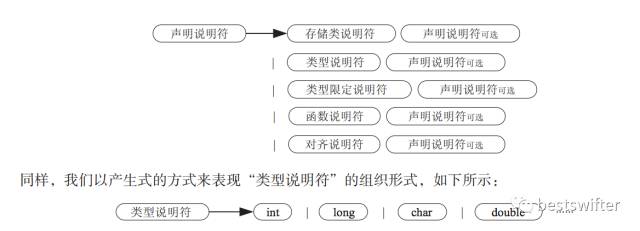
這才僅僅是聲明語句中最簡單的聲明說明符,僅僅是幾個類型和關鍵字的組合而已。后面的初始聲明符列表的解析更復雜。如果有能力做完這些解析,恭喜你,成功的解析了聲明語句。你會發(fā)現(xiàn)什么定義語句啦,調(diào)用語句啦,正嫵媚的向你招手╮(╯▽╰)╭。
成功解析語法以后,我們會得到抽象語法樹(AST: Abstract Syntax Tree)。以這段代碼為例:
- int fun(int a, int b) {
- int c = 0;
- c = a + b;
- return c;
- }
它的語法樹如下:
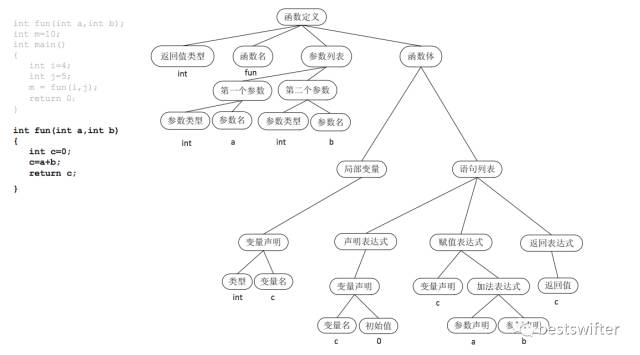
語法樹將字符串格式的源代碼轉化為樹狀的數(shù)據(jù)結構,更容易被計算機理解和處理。但它距離中間代碼還有一定的距離。
生成中間代碼
以 GCC 為例,生成中間代碼可以分為三個步驟:
- 語法樹轉高端 gimple
- 高端 gimple 轉低端 gimple
- 低端 gimple 經(jīng)過 cfa 轉 ssa 再轉中間代碼
簡單的介紹一下每一步都做了什么。
語法樹轉高端 gimple
這一步主要是處理寄存器和棧,比如 c = a + b 并沒有直接的匯編代碼和它對應,一般來說需要把 a + b 的結果保存到寄存器中,然后再把寄存器賦值給 c。所以這一步如果用 C 語言來表示其實是:
- int temp = a + b; // temp 其實是寄存器
- c = temp;
另外,調(diào)用一個新的函數(shù)時會進入到函數(shù)自己的棧,建棧的操作也需要在 gimple 中聲明。
高端 gimple 轉低端 gimple
這一步主要是把變量定義,語句執(zhí)行和返回語句區(qū)分存儲。比如:
- int a = 1;
- a++;
- int b = 1;
會被處理成:
- int a = 1;
- int b = 1;
- a++;
這樣做的好處是很容易計算一個函數(shù)到底需要多少棧空間。
此外,return 語句會被統(tǒng)一處理,放在函數(shù)的末尾,比如:
- if (1 > 0) {
- return 1;
- }
- else {
- return 0;
- }
會被處理成:
- if (1 > 0) {
- goto a;
- }
- else {
- goto b;
- }
- a:
- return 1;
- b:
- return 0;
低端 gimple 經(jīng)過 cfa 轉 ssa 再轉中間代碼
這一步主要是進行各種優(yōu)化,添加版本號等,我不太了解,對于普通開發(fā)者來說也沒有學習的必要。
中間代碼的意義
其實中間代碼可以被省略,抽象語法樹可以直接轉化為目標代碼(匯編代碼)。然而,不同的 CPU 的匯編語法并不一致,比如 AT&T與Intel匯編風格比較 這篇文章所提到的,Intel 架構和 AT&T 架構的匯編碼中,源操作數(shù)和目標操作數(shù)位置恰好相反。Intel 架構下操作數(shù)和立即數(shù)沒有前綴但 AT&T 有。因此一種比較高效的做法是先生成語言無關,CPU 也無關的中間代碼,然后再生成對應各個 CPU 的匯編代碼。
生成中間代碼是非常重要的一步,一方面它和語言無關,也和 CPU 與具體實現(xiàn)無關。可以理解為中間代碼是一種非常抽象,又非常普適的代碼。它客觀中立的描述了代碼要做的事情,如果用中文、英文來分別表示 C 和 Java 的話,中間碼某種意義上可以被理解為世界語。
另一方面,中間代碼是編譯器前端和后端的分界線。編譯器前端負責把源碼轉換成中間代碼,編譯器后端負責把中間代碼轉換成匯編代碼。
LLVM IR 是一種中間代碼,它長成這樣:
- define i32 @square_unsigned(i32 %a) {
- %1 = mul i32 %a, %a
- ret i32 %1
- }
生成目標代碼
目標代碼也可以叫做匯編代碼。由于中間代碼已經(jīng)非常接近于實際的匯編代碼,它幾乎可以直接被轉化。主要的工作量在于兼容各種 CPU 以及填寫模板。在最終生成的匯編代碼中,不僅有匯編命令,也有一些對文件的說明。比如:
- .file "test.c" # 文件名稱
- .global m # 全局變量 m
- .data # 數(shù)據(jù)段聲明
- .align 4 # 4 字節(jié)對齊
- .type m, @objc
- .size m, 4
- m:
- .long 10 # m 的值是 10
- .text
- .global main
- .type main, @function
- main:
- pushl %ebp
- movl %esp, %ebp
- ...
匯編
匯編器會接收匯編代碼,將它轉換成二進制的機器碼,生成目標文件(后綴是 .o),機器碼可以直接被 CPU 識別并執(zhí)行。從目標代碼可以猜出來,最終的目標文件(機器碼)也是分段的,這主要有以下三個原因:
- 分段可以將數(shù)據(jù)和代碼區(qū)分開。其中代碼只讀,數(shù)據(jù)可寫,方便權限管理,避免指令被改寫,提高安全性。
- 現(xiàn)代 CPU 一般有自己的數(shù)據(jù)緩存和指令緩存,區(qū)分存儲有助于提高緩存***率。
- 當多個進程同時運行時,他們的指令可以被共享,這樣能節(jié)省內(nèi)存。
段分離我們并不遙遠,比如命令行中的 objcopy 可以自行添加自定義的段名,C 語言的 __attribute((section(段名)))__ 可以把變量定義在某個特定名稱的段中。
對于一個目標文件來說,文件的最開頭(也叫作 ELF 頭)記錄了目標文件的基本信息,程序入口地址,以及段表的位置,相當于是對文件的整體描述。接下來的重點是段表,它記錄了每個段的段名,長度,偏移量。比較常用的段有:
- .strtab 段: 字符串長度不定,分開存放浪費空間(因為需要內(nèi)存對齊),因此可以統(tǒng)一放到字符串表(也就是 .strtab 段)中進行管理。字符串之間用\0 分割,所以凡是引用字符串的地方用一個數(shù)字就可以代表。
- .symtab: 表示符號表。符號表統(tǒng)一管理所有符號,比如變量名,函數(shù)名。符號表可以理解為一個表格,每行都有符號名(數(shù)字)、符號類型和符號值(存儲地址)
- .rel 段: 它表示一系列重定位表。這個表主要在鏈接時用到,下面會詳細解釋。
鏈接
在一個目標文件中,不可能所有變量和函數(shù)都定義在文件內(nèi)部。比如 strlen 函數(shù)就是一個被調(diào)用的外部函數(shù),此時就需要把 main.o 這個目標文件和包含了 strlen函數(shù)實現(xiàn)的目標文件鏈接起來。我們知道函數(shù)調(diào)用對應到匯編其實是 jump 指令,后面寫上被調(diào)用函數(shù)的地址,但在生成 main.o 的過程中,strlen() 函數(shù)的地址并不知道,所以只能先用 0 來代替,直到***鏈接時,才會修改成真實的地址。
鏈接器就是靠著重定位表來知道哪些地方需要被重定位的。每個可能存在重定位的段都會有對應的重定位表。在鏈接階段,鏈接器會根據(jù)重定位表中,需要重定位的內(nèi)容,去別的目標文件中找到地址并進行重定位。
有時候我們還會聽到動態(tài)鏈接這個名詞,它表示重定位發(fā)生在運行時而非編譯后。動態(tài)鏈接可以節(jié)省內(nèi)存,但也會帶來加載的性能問題,這里不詳細解釋,感興趣的讀者可以閱讀《程序員的自我修養(yǎng)》這本書。
預處理
***簡單描述一下預處理。預處理主要是處理一些宏定義,比如#define、#include、#if 等。預處理的實現(xiàn)有很多種,有的編譯器會在詞法分析前先進行預處理,替換掉所有 # 開頭的宏,而有的編譯器則是在詞法分析的過程中進行預處理。當分析到 # 開頭的單詞時才進行替換。雖然先預處理再詞法分析比較符合直覺,但在實際使用中,GCC 使用的卻是一邊詞法分析,一邊預處理的方案。
編譯 VS 解釋
總結一下,對于 C 語言來說,從源碼到運行結果大致上需要經(jīng)歷編譯、匯編和鏈接三個步驟。編譯器接收源代碼,輸出目標代碼(也就是匯編代碼),匯編器接收匯編代碼,輸出由機器碼組成的目標文件(二進制格式,.o 后綴),***鏈接器將各個目標文件鏈接起來,執(zhí)行重定位,最終生成可執(zhí)行文件。
編譯器以中間代碼為界限,又可以分前端和后端。比如 clang 就是一個前端工具,而 LLVM 則負責后端處理。另一個知名工具 GCC(GNU Compile Collection)則是一個套裝,包攬了前后端的所有任務。前端主要負責預處理、詞法分析、語法分析,最終生成語言無關的中間代碼。后端主要負責目標代碼的生成和優(yōu)化。
關于編譯原理的基礎知識雖然枯燥,但掌握這些知識有助于我們理解一些有用的,但不太容易理解的概念。接下來,我們簡單看一下別的語言是如何運行的。
Java
在 Java 代碼的執(zhí)行過程中,可以簡單分為編譯和執(zhí)行兩步。Java 的編譯器首先會把 .java 格式的源碼編譯成 .class 格式的字節(jié)碼。字節(jié)碼對應到 C 語言的編譯體系中就是中間碼,Java 虛擬機執(zhí)行這些中間碼得到最終結果。
回憶一下上文對中間碼的解釋,一方面它與語言無關,僅僅描述客觀事實。另一方面它和目標代碼的差距并不大,已經(jīng)包括了對寄存器和棧的處理,僅僅是抽象了 CPU 架構而已,只要把它具體化成各個平臺下的目標代碼,就可以交給匯編器了。
解釋型語言
一般來說我們也把解釋型語言叫做腳本語言,比如 Python、Ruby、JavaScript 等等。這類語言的特點是,不需要編譯,直接由解釋器執(zhí)行。換言之,運行流程變成了:
源代碼 -> 解釋器 -> 運行結果
需要注意的是,這里的解釋器只是一個黑盒,它的實現(xiàn)方式可以是多種多樣的。舉個例子,它的實現(xiàn)可以非常類似于 Java 的執(zhí)行過程。解釋器里面可以包含一個編譯器和虛擬機,編譯器把源碼轉化成 AST 或者字節(jié)碼(中間代碼)然后交給虛擬機執(zhí)行,比如 Ruby 1.9 以后版本的官方實現(xiàn)就是這個思路。
至于虛擬機,它并不是什么黑科技,它的內(nèi)部可以編譯執(zhí)行,也可以解釋執(zhí)行。如果是編譯執(zhí)行,那么它會把字節(jié)碼編譯成當前 CPU 下的機器碼然后統(tǒng)一執(zhí)行。如果是解釋執(zhí)行,它會逐條翻譯字節(jié)碼。
有意思的是,如果虛擬機是編譯執(zhí)行的,那么這套流程和 C 語言幾乎一樣,都滿足下面這個流程:
源代碼 -> 中間代碼 -> 目標代碼 -> 運行結果
下面是重點!!!
下面是重點!!!
下面是重點!!!
因此,解釋型語言和編譯型語言的根本區(qū)別在于,對于用戶來說,到底是直接從源碼開始執(zhí)行,還是從中間代碼開始執(zhí)行。以 C 語言為例,所有的可執(zhí)行程序都是二進制文件。而對于傳統(tǒng)意義的 Python 或者 JavaScript,用戶并沒有拿到中間代碼,他們直接從源碼開始執(zhí)行。從這個角度來看, Java 不可能是解釋型語言,雖然 Java 虛擬機會解釋字節(jié)碼,但是對于用戶來說,他們是從編譯好的 .class 文件開始執(zhí)行,而非源代碼。
實際上,在 x86 這種復雜架構下,二進制的機器碼也不能被硬件直接執(zhí)行,CPU 會把它翻譯成更底層的指令。從這個角度來說,我們眼中的硬件其實也是一個虛擬機,執(zhí)行了一些“抽象”指令,但我相信不會有人認為 C 語言是解釋型語言。因此,有沒有虛擬機,虛擬機是不是解釋執(zhí)行,會不會生成中間代碼,這些都不重要,重要的是如果從中間代碼開始執(zhí)行,而且 AST 已經(jīng)事先生成好,那就是編譯型的語言。
如果更本質一點看問題,根本就不存在解釋型語言或者編譯型語言這種說法。已經(jīng)有人證明,如果一門語言是可以解釋的,必然可以開發(fā)出這門語言的編譯器。反過來說,如果一門語言是可編譯的,我只要把它的編譯器放到解釋器里,把編譯推遲到運行時,這么語言就可以是解釋型的。事實上,早有人開發(fā)出了 C 語言的解釋器:
C 源代碼 -> C 語言解釋器(運行時編譯、匯編、鏈接) -> 運行結果
我相信這一點很容易理解,規(guī)范和實現(xiàn)是兩套分離的體系。我們平常說的 C 語言的語法,實際上是一套規(guī)范。理論上來說每個人都可以寫出自己的編譯器來實現(xiàn) C 語言,只要你的編譯器能夠正確運行,最終的輸出結果正確即可。而編譯型和解釋型說的其實是語言的實現(xiàn)方案,是提前編譯以獲得***的性能提高,還是運行時去解析以獲得靈活性,往往取決于語言的應用場景。所以說一門語言是編譯型還是解釋型的,這會非常可笑。一個標準怎么可能會有固定的實現(xiàn)呢?之所以給大家留下了 C 語言是編譯型語言,Python 是解釋型語言的印象,往往是因為這門語言的應用場景決定了它是主流實現(xiàn)是編譯型還是解釋型。
自舉
不知道有沒有人思考過,C 語言的編譯器是如何實現(xiàn)的?實際上它還是用 C 語言實現(xiàn)的。這種自己能編譯自己的神奇能力被稱為自舉(Bootstrap)。
乍一看,自舉是不可能的。因為 C 語言編譯器,比如 GCC,要想運行起來,必定需要 GCC 的編譯器將它編譯成二進制的機器碼。然而 GCC 的編譯器又如何編譯呢……
解決問題的關鍵在于打破這個循環(huán),我們可以先用一個比 C 語言低級的語言來實現(xiàn)一個 C 語言編譯器。這件事是可能做到的,因為這個低級語言必然會比 C 語言簡單,比如我們可以直接用匯編代碼來寫 C 語言的編譯器。由于越低級的語言越簡單,但表達能力越弱,所以用匯編來寫可能太復雜。這種情況下我們可以先用一個比 C 語言低級但比匯編高級的語言來實現(xiàn) C 語言的編譯器,同時用匯編來實現(xiàn)這門語言的編譯器。總之就是不斷用低級語言來寫高級語言的編譯器,雖然語言越低級,它的表達能力越弱,但是它要解析的語言也在不斷變簡單,所以這件事是可以做到的。
有了低級語言寫好的 C 語言編譯器以后,這個編譯器是二進制格式的。此時就可以刪掉所有的低級語言,只留一個二進制格式的 C 語言編譯器,接下來我們就可以用 C 語言寫編譯器,再用這個二進制格式的編譯器去編譯 C 語言實現(xiàn)的 C 語言編譯器了,于是完成了自舉。
以上邏輯描述起來比較繞,但我想多讀幾遍應該可以理解。如果實在不理解也沒關系,我們只要明白 C 語言可以自舉是因為它可以編譯成二進制機器碼,只要用低級語言生成這個機器碼,就不再需要低級語言了,因為機器碼可以直接被 CPU 執(zhí)行。
從這個角度來看,解釋型語言是不可能自舉的。以 Python 為例,自舉要求它能用 Python 語言寫出來 Python 的解釋器,然而這個解釋器如何運行呢,最終還是需要一個解釋器。而解釋器體系下, Python 都是從源碼經(jīng)過解釋器執(zhí)行,又不能留下什么可以直接被硬件執(zhí)行的二進制形式的解釋器文件,自然是沒辦法自舉的。然而,就像前面說的,Python 完全可以實現(xiàn)一個編譯器,這種情況下它就是可以自舉的。
所以一門語言能不能自舉,主要取決于它的實現(xiàn)形式能否被編譯并留下二進制格式的可執(zhí)行文件。
運行時
本文的讀者如果是使用 Objective-C 的 iOS 開發(fā)者,想必都有過在面試時被 runtime 支配的恐懼。然而,runtime 并非是 Objective-C 的專利,絕大多數(shù)語言都有這個概念。所以有人說 Objective-C 具有動態(tài)性是因為它有 runtime,這種說法并不準確,我覺得要把 Objective-C 的 runtime 和一般意義的運行時庫區(qū)分開,認識到它僅僅是運行時庫的一個組成部分,同時還是要深入到方法調(diào)用的層面來談。
運行時庫的基本概念
以 C 語言為例,有非常多的操作最終都依賴于 glibc 這個動態(tài)鏈接庫。包括但不限于字符串處理(strlen、strcpy)、信號處理、socket、線程、IO、動態(tài)內(nèi)存分屏(malloc)等等。這一點很好理解,如果回憶一下之前編譯器的工作原理,我們會發(fā)現(xiàn)它僅僅是處理了語言的語法,比如變量定義,函數(shù)聲明和調(diào)用等等。至于語言的功能, 比如內(nèi)存管理,內(nèi)建的類型,一些必要功能的實現(xiàn)等等。如果要對運行時庫進行分類,大概有兩類。一種是語言自身功能的實現(xiàn),比如一些內(nèi)建類型,內(nèi)置的函數(shù);另一種則是語言無關的基礎功能,比如文件 IO,socket 等等。
由于每個程序都依賴于運行時庫,這些庫一般都是動態(tài)鏈接的,比如 C 語言的 (g)libc。這樣一來,運行時庫可以存儲在操作系統(tǒng)中,節(jié)省內(nèi)存占用空間和應用程序大小。
對于 Java 語言來說,它的垃圾回收功能,文件 IO 等都是在虛擬機中實現(xiàn),并提供給 Java 層調(diào)用。從這個角度來看,虛擬機/解釋器也可以被看做語言的運行時環(huán)境(庫)。
swift 運行時庫
經(jīng)過這樣的解釋,相信 swift 的運行時庫就很容易理解了。一方面,swift 是絕對的靜態(tài)語言,另一方面,swift 毫無疑問的帶有自己的運行時庫。舉個最簡單的例子,如果閱讀 swift 源碼就會發(fā)現(xiàn)某些類型,比如字符串(String),或者數(shù)組,再或者某些函數(shù)(print)都是用 swift 實現(xiàn)的,這些都是 swift 運行時庫的一部分。按理說,運行時庫應該內(nèi)置于操作系統(tǒng)中并且和應用程序動態(tài)鏈接,然而坑爹的 Swift 在本文寫作之時依然沒有穩(wěn)定 ABI,導致每個程序都必須自帶運行時庫,這也就是為什么目前 swift 開發(fā)的 app 普遍會增加幾 Mb 包大小的原因。
說到 ABI,它其實就是一個編譯后的 API。簡單來說,API 是描述了在應用程序級別,模塊之間的調(diào)用約定。比如某個模塊想要調(diào)用另一個模塊的功能,就必須根據(jù)被調(diào)用模塊提供的 API 來調(diào)用,因為 API 中規(guī)定了方法名、參數(shù)和返回結果的類型。而當源碼被編譯成二進制文件后,它們之間的調(diào)用也存在一些規(guī)則和約定。
比如模塊 A 有兩個整數(shù) a 和 b,它們的內(nèi)存布局如下:
| 模塊 A |
|---|
| 初始地址 |
| a |
| b |
這時候別的模塊調(diào)用 A 模塊的 b 變量,可以通過初始地址加偏移量的方式進行。
如果后來模塊 A 新增了一個整數(shù) c,它的內(nèi)存布局可能會變成:
| 模塊 A |
|---|
| 初始地址 |
| c |
| a |
| b |
如果調(diào)用方還是使用相同的偏移量,可以想見,這次拿到的就是變量 a 了。因此,每當模塊 A 有更新,所有依賴于模塊 A 的模塊都必須重新編譯才能正確工作。如果這里的模塊 A 是 swift 的運行時庫,它內(nèi)置于操作系統(tǒng)并與其他模塊(應用程序)動態(tài)鏈接會怎么樣呢?結果就是每次更新系統(tǒng)后,所有的 app 都無法打開。顯然這是無法接受的。
當然,ABI 穩(wěn)定還包括其他的一些要求,比如調(diào)用和被調(diào)用者遵守相同的調(diào)用約定(參數(shù)和返回值如何傳遞)等。
JavaScript 那些事
我們繼續(xù)剛才有關運行時的話題,先從 JavaScript 的運行時聊起,再介紹 JavaScript 的相關知識。
JavaScript 是如何運行的
JavaScript 和其他語言,無論是 C 語言,還是 Python 這樣的腳本語言,***的區(qū)別在于 JavaScript 的宿主環(huán)境比較奇怪,一般來說是瀏覽器。
無論是 C 還是 Python,他們都有一個編譯器/解釋器運行在操作系統(tǒng)上,直接把源碼轉換成機器碼。而 JavaScript 的解釋器一般內(nèi)置在瀏覽器中,比如 Chrome 就有一個 V8 引擎可以解析并執(zhí)行 JavaScript 代碼。因此 JavaScript 的能力實際上會受到宿主環(huán)境的影響,有一些限制和加強。
首先來看看 DOM 操作,相關的 API 并沒有定義在 ECMAScript 標準中,因此我們常用的 window.xxx 還有 window.document.xxx 并非是 JavaScript 自帶的功能,這通常是由宿主平臺通過 C/C++ 等語言實現(xiàn),然后提供給 JavaScript 的接口。同樣的,由于瀏覽器中的 JavaScript 只是一個輕量的語言,沒有必要讀寫操作系統(tǒng)的文件,因此瀏覽器引擎一般不會向 JavaScript 提供文件讀寫的運行時組件,它也就不具備 IO 的能力。從這個角度來看,整個瀏覽器都可以看做 JavaScript 的虛擬機或者運行時環(huán)境。
因此,當我們換一個宿主環(huán)境,比如 Node.js,JavaScript 的能力就會發(fā)生變化。它不再具有 DOM API,但多了讀寫文件等能力。這時候,Node.js 就更像是一個標準的 JavaScript 解析器了。這也是為什么 Node.js 讓 JavaScript 可以編寫后端應用的原因。
JIT 優(yōu)化
解釋執(zhí)行效率低的主要原因之一在于,相同的語句被反復解釋,因此優(yōu)化的思路是動態(tài)的觀察哪些代碼是經(jīng)常被調(diào)用的。對于那些被高頻率調(diào)用的代碼,可以用編譯器把它編譯成機器碼并且緩存下來,下次執(zhí)行的時候就不用重新解釋,從而提升速度。這就是 JIT(Just-In-Time) 的技術原理。
但凡基于緩存的優(yōu)化,一定會涉及到緩存***率的問題。在 JavaScript 中,即使是同一段代碼,在不同上下文中生成的機器碼也不一定相同。比如這個函數(shù):
- function add(a, b) {
- return a + b;
- }
如果這里的 a 和 b 都是整數(shù),可以想見最終的代碼一定是匯編中的 add 命令。如果類似的加法運算調(diào)用了很多次,解釋器可能會認為它值得被優(yōu)化,于是編譯了這段代碼。但如果下一次調(diào)用的是 add("hello", "world"),之前的優(yōu)化就無效了,因為字符串加法的實現(xiàn)和整數(shù)加法的實現(xiàn)完全不同。
于是優(yōu)化后的代碼(二進制格式)還得被還原成原先的形式(字符串格式),這樣的過程被稱為去優(yōu)化。反復的優(yōu)化 -> 去優(yōu)化 -> 優(yōu)化 …… 非常耗時,大大降低了引入 JIT 帶來的性能提升。
JIT 理論上給傳統(tǒng)的 JavaScript 帶了了 20-40 倍的性能提升,但由于上述去優(yōu)化的存在,在實際運行的過程中遠遠達不到這個理論上的性能天花板。
WebAssembly
前文說過,JavaScript 實際上是由瀏覽器引擎負責解析并提供一些功能的。瀏覽器引擎可能是由 C++ 這樣高效的語言實現(xiàn)的,那么為什么不用 C++ 來寫網(wǎng)頁呢?實際上我認為從技術角度來說并不存在問題,直接下發(fā) C++ 代碼,然后交給 C++ 解釋器去執(zhí)行,再調(diào)用瀏覽器的 C++ 組件,似乎更加符合直覺一些。
之所以選擇 JavaScript 而不是 C++,除了主流瀏覽器目前都只支持 JavaScript 而不支持 C++ 這個歷史原因以外,更重要的一點是一門語言的高性能和簡單性不可兼得。JavaScript 在運行速度方面做出了犧牲,但也具備了簡單易開發(fā)的優(yōu)點。作為通用編程語言,JavaScript 和 C++ 主要的性能差距就在于缺少類型標注,導致無法進行有效的提前編譯。之前說過 JIT 這種基于緩存去猜測類型的方式存在瓶頸,那么最精確的方式肯定還是直接加上類型標注,這樣就可以直接編譯了,代表性的作品有 Mozilla 的Asm.js。
Asm.js 是 JavaScript 的一個子集,任何 JavaScript 解釋器都可以解釋它:
- function add(a, b) {
- a = a | 0 // 任何整數(shù)和自己做按位或運算的結果都是自己
- b = b | 0 // 所以這個標記不改變運算結果,但是可以提示編譯器 a、b 都是整數(shù)
- return a + b | 0
- }
如果有 Asm.js 特定的解釋器,完全可以把它提前編譯出來。即使沒有也沒關系,因為它完全是 JavaScript 語法的子集,普通的解釋器也可以解釋。
然而,回顧一下我們最初對解釋器的定義: 解釋器是一個黑盒,輸入源碼,輸出運行結果。Asm.js 其實是黑盒內(nèi)部的一個優(yōu)化,不同的黑盒(瀏覽器)無法共享這一優(yōu)化。換句話說 Asm.js 寫成的代碼放到 Chrome 上面和普通的 JavaScript 毫無區(qū)別。
于是,包括微軟、谷歌和蘋果在內(nèi)的各大公司覺得,是時候搞個標準了,這個標準就是 WebAssembly 格式。它是介于中間代碼和目標代碼之間的一種二進制格式,借用WebAssembly 系列(四)WebAssembly 工作原理 一文的插圖來表示:
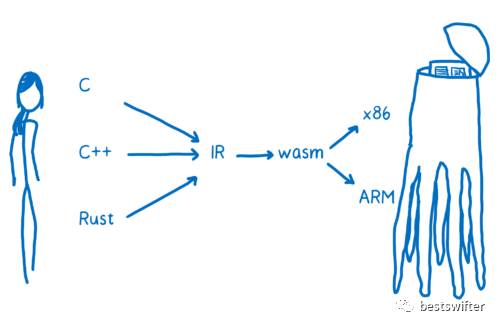
通常從中間代碼到機器碼,需要經(jīng)過平臺具體化(轉目標代碼)和二進制化(匯編器把匯編代碼變?yōu)槎M制機器碼)這兩個步驟。而 WebAssembly 首先完成了第二個步驟,即已經(jīng)是二進制格式的,但只是一系列虛擬的通用指令,還需要轉換到各個 CPU 架構上。這樣一來,從 WebAssembly 到機器碼其實是透明且統(tǒng)一的,各個瀏覽器廠商只需要考慮如何從中間代碼轉換 WebAssembly 就行了。
由于編譯器的前端工具 Clang 可以把 C/C++ 轉換成中間代碼,因此理論上它們都可以用來開發(fā)網(wǎng)頁。然而誰會這么這么做呢,放著簡單快捷,現(xiàn)在又高效的 JavaScript 不寫,非要去啃 C++?
跨語言那些事兒
C++ 寫網(wǎng)頁這個腦洞雖然比較大,但它啟發(fā)我思考一個問題:“對于一個常見的可以由某個語言完成的任務(比如 JavaScript 寫網(wǎng)頁),能不能換一個語言來實現(xiàn)(比如 C++),如果不能,制約因素在哪里”。
由于絕大多數(shù)主流語言都是圖靈完備的,也就是說一切可計算的問題,在這些語言層面都是等價的,都可以計算。那么制約語言能力的因素也就只剩下了運行時的環(huán)境是否提供了相應的功能。比如前文解釋過的,雖然瀏覽器中的 JavaScript 不能讀寫文件,不能實現(xiàn)一個服務器,但這是瀏覽器(即運行時環(huán)境)不行,不是 JavaScript 不行,只要把運行環(huán)境換成 Node.js 就行了。
直接語法轉換
大部分讀者應該接觸過簡單的逆向工程。比如編譯后的 .o 目標文件和 .class 字節(jié)碼都可以反編譯成源代碼,這種從中間代碼倒推回源代碼的技術也被叫做反編譯(decompile),反編譯器的工作流程基本上是編譯器的倒序,只不過***的反編譯一般來說比較困難,這取決于中間代碼的實現(xiàn)。像 Java 字節(jié)碼這樣的中間代碼,由于信息比較全,所以反編譯就相對容易、準確一些。C 代碼在生成中間代碼時丟失了很多信息,因此就幾乎不可能 100% 準確的倒推回去,感興趣的讀者可以參考一下知名的反編譯工具Hex-Rays 的一篇博客。
前文說過,編譯器前端可以對多種語言進行詞法分析和語法分析,并且生成一套語言無關的中間代碼,因此理論上來說,如果某個編譯器前端工具支持兩個語言 A 和 B 的解析,那么 A 和 B 是可以互相轉換的,流程如下:
A 源碼 <--> 語言無關的中間代碼 <--> B 源碼
其中從源碼轉換到中間代碼需要使用編譯器,從中間代碼轉換到源碼則使用反編譯器。
但在實際情況中,事情會略復雜一些,這是因為中間代碼雖然是一套語言無關、CPU 也無關的指令集,但不代表不同語言生成的中間代碼就可以通用。比如中間代碼共有 1、2、3、……、6 這六個指令。A 語言生成的中間代碼僅僅是所有指令的一個子集,比如是 1-5 這 5 個指令;B 語言生成的中間代碼可能是所有指令的另一個子集,比如 2-6。這時候我們說的 B 語言的反編譯器,實際上是從 2-6 的指令子集推導出 B 語言源碼,它對指令 1 可能無能為力。
以 GCC 的中間代碼 RTL: Register Transfer Language 為例,官方文檔 在對 RTL 的解釋中,就明確的把 RTL 樹分為了通用的、C/C++ 特有的、Java 特有的等幾個部分。
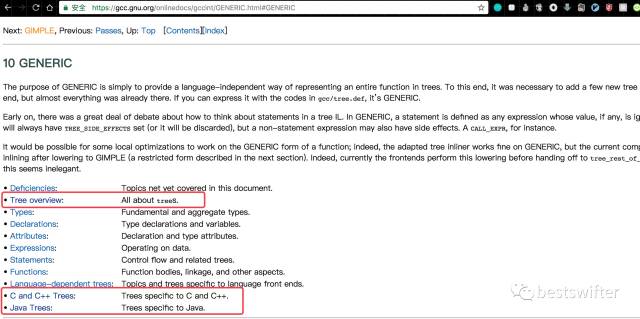
具體來說,我們知道 Java 并不能直接訪問內(nèi)存地址,這一點和瀏覽器上的 JavaScript 不能讀寫文件很類似,都是因為它們的運行環(huán)境(虛擬機)具備這種能力,但沒有在語言層面提供。因此,含有指針四則運算的 C 代碼無法直接被轉換成 Java 代碼,因為 Java 字節(jié)碼層面并沒有定義這樣的抽象,一種簡單的方案是申請一個超大的數(shù)組,然后自己模擬內(nèi)存地址。
所以,即使編譯器前端同時支持兩種語言的解析,要想進行轉換,還必須處理兩種語言在中間代碼層面的一些小差異,實際流程應該是:
A 源碼 <--> 中間代碼子集(A) <--適配器--> 中間代碼子集(B) <--> B 源碼
這個思路已經(jīng)不僅僅停留在理論上了,比如 Github 上有一個庫: emscripten 就實現(xiàn)了將任何 Clang 支持的語言(比如 C/C++ 等)轉換成 JavaScript,再比如 lljvm實現(xiàn)了 C 到 Java 字節(jié)碼的轉換。
然而前文已經(jīng)解釋過,實現(xiàn)單純語法的轉換意義并不大。一方面,對于圖靈完備的語言來說,換一種表示方法(語言)去解決相同的問題并沒有意義。另一方面,語言的真正功能絕不僅僅是語法本身,而在于它的運行時環(huán)境提供了什么樣的功能。比如 Objective-C 的 Foundation 庫提供了字典類型 NSDictionary,它如果直接轉換成 C 語言,將是一個找不到的符號。因為 C 語言的運行時環(huán)境根本就不提供對這種數(shù)據(jù)結構的支持。因此凡是在語言層面進行強制轉換的,要么利用反編譯器拿到一堆格式正確但無法運行的代碼,要么就自行解析語法樹并為轉換后的語言添加對應的能力,來實現(xiàn)轉換前語言的功能。
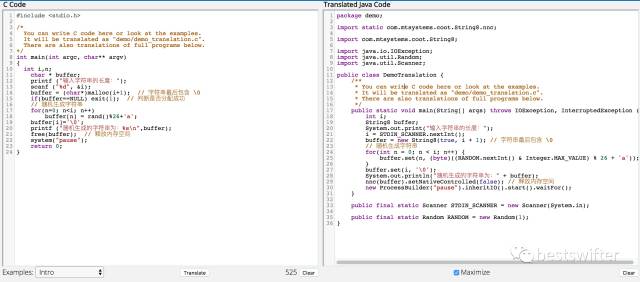
比如圖中就是一個 C 語言轉換 Java 的工具,為了實現(xiàn) C 語言中的字符串申請和釋放內(nèi)存,這個工具不得不自己實現(xiàn)了 com.mtsystems.coot.String8 類。這樣巨大的成本,顯然不夠普適,應用場景相對有限。
總之,直接的語法轉換是一個美好的想法,但實現(xiàn)起來難度大,收益有限,通常是為了移植已經(jīng)用某個語言寫好的框架,或者開個腦洞用于學習,但實際應用場景并不多。
膠水語言 Python
Python 一個很強大的特點是膠水語言,可以把 Python 理解為各種語言的粘合劑。對于 Python 可以處理的邏輯,用 Python 代碼即可完成。如果追求***的性能或者調(diào)用已經(jīng)實現(xiàn)的功能,也可以讓 Python 調(diào)用已經(jīng)由別的語言實現(xiàn)的模塊,以 Python 和 C 語言的交互解釋一下。
首先,如果是 C 語言要執(zhí)行 Python 代碼,顯然需要一個 Python 的解釋器。由于在 Mac OS X 系統(tǒng)上,Python 解釋器是一個動態(tài)鏈接庫,所以只要導入一下頭文件即可,下面這段代碼可以成功輸出 “Hello Python!!!”:
- #include <stdio.h>
- #import <Python/Python.h>
- int main(int argc, const char * argv[]) {
- Py_SetProgramName(argv[0]);
- Py_Initialize();
- PyRun_SimpleString("print 'Hello Python!!!'\n");
- Py_Finalize();
- return 0;
- }
如果是在 iOS 應用里,由于 iOS 系統(tǒng)沒有對應的動態(tài)庫,所以需要把 Python 的解釋器打包成一個靜態(tài)庫并且鏈接到應用中,網(wǎng)上已經(jīng)有人做好了: python-for-iphone,這就是為什么我們看到一些教育類的應用模擬了 Python 解釋器,允許用戶編寫 Python 代碼并得到輸出。
Python 調(diào)用 Objective-C/C 也不復雜,只需要在 C 代碼中指定要暴露的模塊 A 和要暴露的方法 a,然后 Python 就可以直接調(diào)用了:
- import A
- A.a()
詳細的教程可以看這里: 如何實現(xiàn) C/C++ 與 Python 的通信?
有時候,如果能把自己熟悉的語言應用到一個陌生的領域,無疑會大大降低上手的難度。以 iOS 開發(fā)為例,開發(fā)者的日常其實是利用 Objective-C 語法來描述一些邏輯,最終利用 UIKit 等框架完成和應用的交互。 一種很自然而然的想法是,能不能用 Python 來實現(xiàn)邏輯,并且調(diào)用 Objective-C 的接口,比如 UIKit、Foundation 等。實際上前者是完全可以實現(xiàn)的,但是 Python 調(diào)用 Objective-C 遠比調(diào)用 C 語言要復雜得多。
一方面從之前的分析中也能看出,并不是所有的源碼編譯成目標文件都可以被 Python 引用;另一方面,最重要的是 Objective-C 方法調(diào)用的特性。我們知道方法調(diào)用實際上會被編譯成 msg_Send 并交給 runtime 處理,最終找到函數(shù)指針并調(diào)用。這里 Objective-C 的 runtime 其實是一個用 C 語言實現(xiàn)動態(tài)鏈接庫,它可以理解為 Objective-C 運行時環(huán)境的一部分。換句話說,沒有 runtime 這個庫,包含方法調(diào)用的 Objective-C 代碼是不可能運行起來的,因為 msg_Send 這個符號無法被重定向,運行時將找不到 msg_Send 函數(shù)的地址。就連原生的 Objective-C 代碼都需要依賴運行時,想讓 Python 直接調(diào)用某個 Objective-C 編譯出來的庫就更不可能了。
想用 Python 寫開發(fā) iOS 應用是有可能的,比如: PyObjc,但最終還是要依賴 Runtime。大概的思路是首先用 Python 拿到 runtime 這個庫,然后通過這個庫去和 runtime 交互,進而具備了調(diào)用 Objective-C 和各種框架的能力。比如我要實現(xiàn) Python 中的 UIView 這個類,代碼會變成這樣:
- import objc
- # 這個 objc 是動態(tài)加載 libobjc.dylib 得到的
- # Python 會對 objc 做一些封裝,提供調(diào)用 runtime 的能力
- # 實際的工作還是交給 libobjc.dylib 完成
- class UIView:
- def __init__(self, param):
- objc.msgSend("UIView", "init", param)
這么做的性價比并不高,如果和 JSPatch 相比,JSPatch 使用了內(nèi)置的 JavaScriptCore 作為 JavaScript 的解析器,而 PyObjc 就得自己帶一個 libPython.a 解釋器。此外,由于 iOS 系統(tǒng)的沙盒限制,非越獄機器并不能拿到 libobjc 庫,所以這個工具只能在越獄手機上使用。
OCS
既然說到了 JSPatch 這一類動態(tài)化的 iOS 開發(fā)工具,我就斗膽猜測一下騰訊 OCS 的實現(xiàn)原理,目前介紹 OCS 的文章***,由于蘋果公司的要求,原文已經(jīng)被刪除,從新浪博客上摘錄了一份: OCS ——史上最瘋狂的 iOS 動態(tài)化方案。如果用一句話來概述,那么就是 OCS 是一個 Objective-C 解釋器。
首先,OCS 基于 clang 對下發(fā)的 Objective-C 代碼做詞法、語法分析,生成 AST 然后轉化成自定義的一套中間碼(OSScript)。當然,原生的 Objective-C 可以運行,絕不僅僅是編譯器的功勞。就像之前反復強調(diào)的那樣,運行時環(huán)境也必不可少,比如負責 GCD 的 libdispatch 庫,還有內(nèi)存管理,多線程等等功能。這些功能原來都由系統(tǒng)的動態(tài)庫實現(xiàn),但現(xiàn)在必須由解釋器實現(xiàn),所以 OCS 的做法是開發(fā)了一套自己的虛擬機去解釋執(zhí)行中間碼。這個運行原理就和 JVM 非常類似了。
當然,最終還是要和 Objective-C 的 Runtime 打交道,這樣才能調(diào)用 UIKit 等框架。由于對虛擬機的實現(xiàn)原理并不清楚,這里就不敢多講了,希望在學習完 JVM 以后再做分享。
參考資料
- AT&T與Intel匯編風格比較
- glibc
- WebAssembly 系列(一)生動形象地介紹 WebAssembly
- Decompilers and beyond
- python-for-iphone
- 如何實現(xiàn) C/C++ 與 Python 的通信?
- WebAssembly 系列(四)WebAssembly 工作原理
- 扯淡:大白話聊聊編譯那點事兒
- rubicon-objc
- OCS ——史上最瘋狂的 iOS 動態(tài)化方案
- 虛擬機隨談(一):解釋器,樹遍歷解釋器,基于棧與基于寄存器,大雜燴
- JavaScript的功能是不是都是靠C或者C++這種編譯語言提供的?
- 計算機編程語言必須能夠自舉嗎?
- 如何評論瀏覽器***的 WebAssembly 字節(jié)碼技術?
- Objective-C Runtime —— From Build To Did Launch
- 10 GENERIC
- 寫個編譯器,把C++代碼編譯到JVM的字節(jié)碼可不可行?