利用 TensorFlow 實現上下文的 Chat-bots
在我們的日常聊天中,情景才是最重要的。我們將使用 TensorFlow 構建一個聊天機器人框架,并且添加一些上下文處理機制來使得機器人更加智能。
你是否想過一個問題,為什么那么多的聊天機器人會缺乏會話情景功能?
鑒于上下文在所有的對話場景中的重要性,那么又該如何加入這個特性?
接下來,我們將創建一個聊天機器人的框架,并且以一個島嶼輕便摩托車租賃店為例子,建立一個對話模型。這個小企業的聊天機器人需要處理一些關于租賃時間,租賃選項等的簡單問題。我們也希望這個機器人可以處理一些上下文的信息,比如查詢同一天的租賃信息。如果可以解決這個問題,那么我們將節約很多的時間。
關于構建聊天機器人,我們通過以下三部進行:
- 我們會利用 TensorFlow 來編寫對話意圖模型。
- 接下啦,我們將構建一個處理對話的聊天機器人框架。
- 最后,我們將介紹如何將上下文信息合并到我們的響應式處理器中。
在模型中,我們將使用 tflearn 框架,這是一個 TensorFlow 的高層 API,并且我們將使用 IPython 作為開發工具。
1. 我們會利用 TensorFlow 來編寫對話意圖模型。
完整的 notebook 文檔,可以點擊這里。
對于一個聊天機器人框架,我們需要定義一個會話意圖的結構。最簡單方便的方式是使用一個 JSON 格式的文件,如下所示:

每個會話意圖包含:
- 標簽(唯一的名稱)
- 模式(我們的神經網絡文本分類器需要分類的句子)
- 回應(一個將被用作回應的句子)
稍后,我們也會添加一些基本的上下文元素。
首先,我們來導入一些我們需要的包:
# things we need for NLP import nltk from nltk.stem.lancaster import LancasterStemmer stemmer = LancasterStemmer() # things we need for Tensorflow import numpy as np import tflearn import tensorflow as tf import random
如果你還不了解 TensorFlow,那么可以學習一下這個教程或者這個教程。
# import our chat-bot intents file
import json
with open('intents.json') as json_data:
intents = json.load(json_data)
代碼中的 JSON 文件可以這里下載,接下來我們可以開始組織代碼的文件,數據和分類器。
words = []
classes = []
documents = []
ignore_words = ['?']
# loop through each sentence in our intents patterns
for intent in intents['intents']:
for pattern in intent['patterns']:
# tokenize each word in the sentence
w = nltk.word_tokenize(pattern)
# add to our words list
words.extend(w)
# add to documents in our corpus
documents.append((w, intent['tag']))
# add to our classes list
if intent['tag'] not in classes:
classes.append(intent['tag'])
# stem and lower each word and remove duplicates
words = [stemmer.stem(w.lower()) for w in words if w not in ignore_words]
words = sorted(list(set(words)))
# remove duplicates
classes = sorted(list(set(classes)))
print (len(documents), "documents")
print (len(classes), "classes", classes)
print (len(words), "unique stemmed words", words)
我們創建了一個文件列表(每個句子),每個句子都是由一些詞干組成,并且每個文檔都屬于一個特定的類別。
27 documents 9 classes ['goodbye', 'greeting', 'hours', 'mopeds', 'opentoday', 'payments', 'rental', 'thanks', 'today'] 44 unique stemmed words ["'d", 'a', 'ar', 'bye', 'can', 'card', 'cash', 'credit', 'day', 'do', 'doe', 'good', 'goodby', 'hav', 'hello', 'help', 'hi', 'hour', 'how', 'i', 'is', 'kind', 'lat', 'lik', 'mastercard', 'mop', 'of', 'on', 'op', 'rent', 'see', 'tak', 'thank', 'that', 'ther', 'thi', 'to', 'today', 'we', 'what', 'when', 'which', 'work', 'you']
比如,詞干 tak 將和 take,taking,takers 等匹配。在實際過程中,我們可以刪除一些無用的條目,但在這里已經足夠了。
不幸的是,這種數據結構不能在 TensorFlow 中使用,我們需要進一步將這個數據進行轉換:從單詞轉換到數字的張量。
# create our training data
training = []
output = []
# create an empty array for our output
output_empty = [0] * len(classes)
# training set, bag of words for each sentence
for doc in documents:
# initialize our bag of words
bag = []
# list of tokenized words for the pattern
pattern_words = doc[0]
# stem each word
pattern_words = [stemmer.stem(word.lower()) for word in pattern_words]
# create our bag of words array
for w in words:
bag.append(1) if w in pattern_words else bag.append(0)
# output is a '0' for each tag and '1' for current tag
output_row = list(output_empty)
output_row[classes.index(doc[1])] = 1
training.append([bag, output_row])
# shuffle our features and turn into np.array
random.shuffle(training)
training = np.array(training)
# create train and test lists
train_x = list(training[:,0])
train_y = list(training[:,1])
請注意,我們的數據順序已經被打亂了。 TensorFlow 會選取其中的一些數據作為測試數據,用來測試訓練的模型的準確度。
如果我們觀察單個的 x 向量和 y 向量,那么這就是一個詞袋模型,一個表示需要匹配的模式,一個表示匹配的目標。
train_x example: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1] train_y example: [0, 0, 1, 0, 0, 0, 0, 0, 0]
接下來,我們來構建我們的模型。
# reset underlying graph data
tf.reset_default_graph()
# Build neural network
net = tflearn.input_data(shape=[None, len(train_x[0])])
net = tflearn.fully_connected(net, 8)
net = tflearn.fully_connected(net, 8)
net = tflearn.fully_connected(net, len(train_y[0]), activation='softmax')
net = tflearn.regression(net)
# Define model and setup tensorboard
model = tflearn.DNN(net, tensorboard_dir='tflearn_logs')
# Start training (apply gradient descent algorithm)
model.fit(train_x, train_y, n_epoch=1000, batch_size=8, show_metric=True)
model.save('model.tflearn')
這個模型使用的是 2 層神經網絡模型,跟這篇文章中的是一樣的。
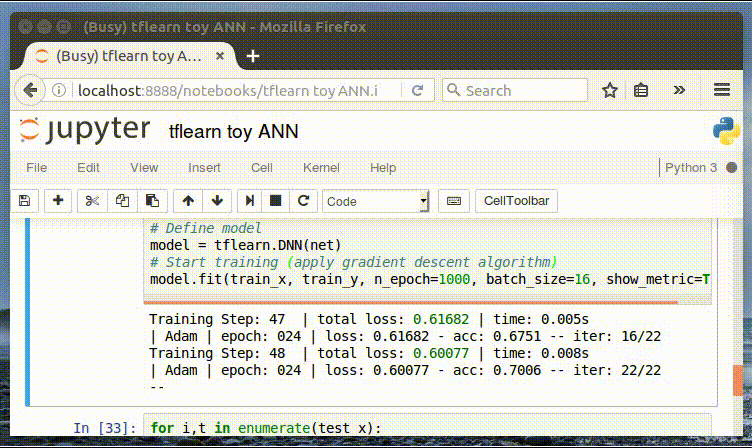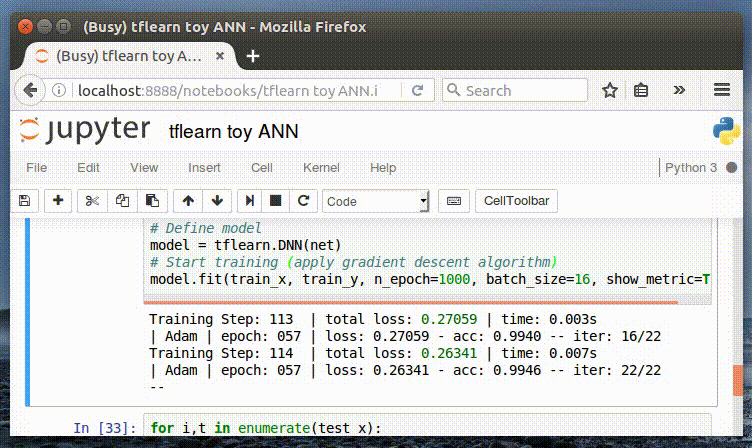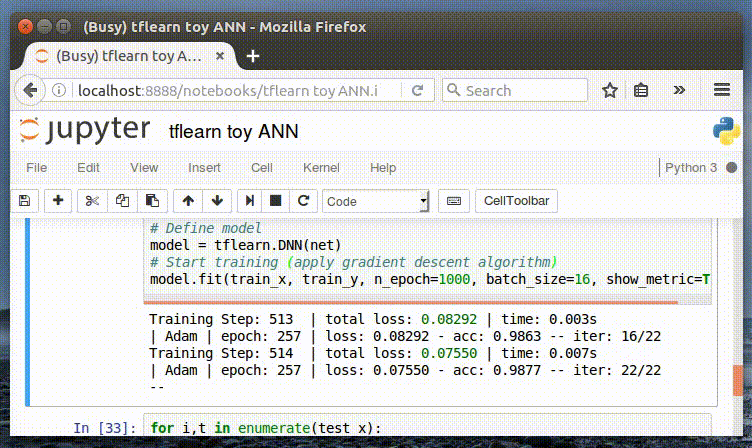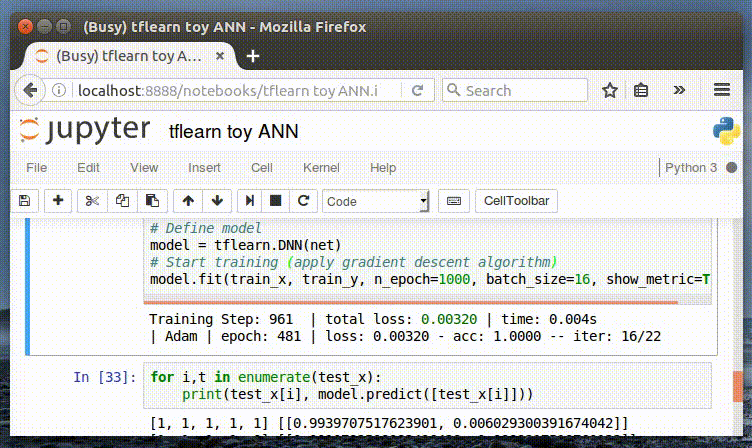
我們完成了這部分的工作,現在需要保存我們的模型和文檔, 以便在后續的代碼中可以使用它們。
# save all of our data structures
import pickle
pickle.dump( {'words':words, 'classes':classes, 'train_x':train_x, 'train_y':train_y}, open( "training_data", "wb" ) )
構建我們的聊天機器人框架
這部分,完整的代碼在這里。
我們將構建一個簡單的狀態機來處理響應,并且使用我們的在上一部分中提到的意圖模型來作為我們的分類器。如果你想了解聊天機器人的工作原理,那么可以點擊這里。

我們需要導入和上一部分相同的包,然后 un-pickle 我們的模型和句子,正如我們在上一部分中操作的。請記住,我們的聊天機器人框架與我們的模型是分開構建的 —— 除非意圖模式改變了,那么我們需要重新運行我們的模型,否則不需要重構模型。如果擁有數百種意圖和數千種模式,模型可能需要幾分鐘的時間才能構建完成。
# restore all of our data structures
import pickle
data = pickle.load( open( "training_data", "rb" ) )
words = data['words']
classes = data['classes']
train_x = data['train_x']
train_y = data['train_y']
# import our chat-bot intents file
import json
with open('intents.json') as json_data:
intents = json.load(json_data)
接下來,我們需要導入剛剛利用 TensorFlow(tflearn 框架)訓練好的模型。請注意,你第一步還是需要去定義 TensorFlow 模型結構,正如我們在第一部分中做的那樣。
# load our saved model
model.load('./model.tflearn')
在我們開始處理對話意圖之前,我們需要一種從用戶輸入數據生詞詞袋的方法。而這個方法,跟我們前面所使用的方法是相同的。
def clean_up_sentence(sentence):
# tokenize the pattern
sentence_words = nltk.word_tokenize(sentence)
# stem each word
sentence_words = [stemmer.stem(word.lower()) for word in sentence_words]
return sentence_words
# return bag of words array: 0 or 1 for each word in the bag that exists in the sentence
def bow(sentence, words, show_details=False):
# tokenize the pattern
sentence_words = clean_up_sentence(sentence)
# bag of words
bag = [0]*len(words)
for s in sentence_words:
for i,w in enumerate(words):
if w == s:
bag[i] = 1
if show_details:
print ("found in bag: %s" % w)
return(np.array(bag))
p = bow("is your shop open today?", words)
print (p)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0]
現在,我們可以開始構建我們的響應處理器了。
ERROR_THRESHOLD = 0.25
def classify(sentence):
# generate probabilities from the model
results = model.predict([bow(sentence, words)])[0]
# filter out predictions below a threshold
results = [[i,r] for i,r in enumerate(results) if r>ERROR_THRESHOLD]
# sort by strength of probability
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append((classes[r[0]], r[1]))
# return tuple of intent and probability
return return_list
def response(sentence, userID='123', show_details=False):
results = classify(sentence)
# if we have a classification then find the matching intent tag
if results:
# loop as long as there are matches to process
while results:
for i in intents['intents']:
# find a tag matching the first result
if i['tag'] == results[0][0]:
# a random response from the intent
return print(random.choice(i['responses']))
results.pop(0)
傳遞給 response() 的每個句子都會被分類。我們分類器使用 model.predict() 函數來進行類別預測,這個方法非常快。模型返回的概率值和我們定義的意圖是一直的,用來生成潛在的響應列表。
如果一個或多個分類結果高于閾值,那么我們會選取出一個與意圖匹配的標簽,然后處理。我們將我們的分類列表作為一個堆棧,并從這個堆棧中尋找一個適合的匹配,直到找到一個最好的或者直到堆棧變空。
我們來舉一個例子,模型會返回最有可能的標簽和其概率。
classify('is your shop open today?')
[('opentoday', 0.9264171123504639)]
請注意,“is your shop open today?” 不是這個意圖中的任何模式:“pattern : ["Are you open today?", "When do you open today?", "What are your hours today?"]”。但是,“open” 和 “today” 術語對我們的模式是非常有用的(他們在選擇意圖時,有決定性的作用)。
我們現在從用戶的輸入數據中產生一個結果:
response('is your shop open today?')
Our hours are 9am-9pm every day
再來一些例子:
response('do you take cash?')
We accept VISA, Mastercard and AMEX
response('what kind of mopeds do you rent?')
We rent Yamaha, Piaggio and Vespa mopeds
response('Goodbye, see you later')
Bye! Come back again soon.
接下來讓我們結合一些基礎的語境來設計一個聊天機器人,比如拖車租賃聊天機器人。
語境
我們想處理的是一個關于租賃摩托車的問題,并詢問一些有關租金的事。對于用戶問題的理解應該是非常容易的,語境非常清晰。如果用戶詢問 “today”,那么上下文的租賃信息就是進入時間框架,那么最好你還能指定是哪一個自行車,這樣交流起來就不會浪費時間。
為了實現這一點,我們需要在框架中再加入一個概念 “state” 。這需要一個數據結構來維護這個新的概念和原來的意圖。
因為我們需要我們的狀態機是一個非常容易的維護,恢復和復制等等操作,所以我們需要把數據都保存在一個諸如字典的數據結構中,這是非常重要的。
接下來,我們給出基本語境的回復過程:
# create a data structure to hold user context
context = {}
ERROR_THRESHOLD = 0.25
def classify(sentence):
# generate probabilities from the model
results = model.predict([bow(sentence, words)])[0]
# filter out predictions below a threshold
results = [[i,r] for i,r in enumerate(results) if r>ERROR_THRESHOLD]
# sort by strength of probability
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append((classes[r[0]], r[1]))
# return tuple of intent and probability
return return_list
def response(sentence, userID='123', show_details=False):
results = classify(sentence)
# if we have a classification then find the matching intent tag
if results:
# loop as long as there are matches to process
while results:
for i in intents['intents']:
# find a tag matching the first result
if i['tag'] == results[0][0]:
# set context for this intent if necessary
if 'context_set' in i:
if show_details: print ('context:', i['context_set'])
context[userID] = i['context_set']
# check if this intent is contextual and applies to this user's conversation
if not 'context_filter' in i or \
(userID in context and 'context_filter' in i and i['context_filter'] == context[userID]):
if show_details: print ('tag:', i['tag'])
# a random response from the intent
return print(random.choice(i['responses']))
results.pop(0)
我們的上下文狀態是一個字典,它將包含每個用戶的狀態。我將為每個用戶使用一個唯一的標識(例如,cell#)。這允許我們的框架和狀態機同事維護多個用戶的狀態。
# create a data structure to hold user context
context = {}
我們在意圖處理流程中,添加了上下文信息,具體如下:
if i['tag'] == results[0][0]:
# set context for this intent if necessary
if 'context_set' in i:
if show_details: print ('context:', i['context_set'])
context[userID] = i['context_set']
# check if this intent is contextual and applies to this user's conversation
if not 'context_filter' in i or \
(userID in context and 'context_filter' in i and i['context_filter'] == context[userID]):
if show_details: print ('tag:', i['tag'])
# a random response from the intent
return print(random.choice(i['responses']))
如果一個意圖想要設置上下文信息,那么我們可以這樣做:
{“tag”: “rental”,
“patterns”: [“Can we rent a moped?”, “I’d like to rent a moped”, … ],
“responses”: [“Are you looking to rent today or later this week?”],
“context_set”: “rentalday”
}
如果另一個意圖想要與上下文進行關聯,那么可以這樣做:
{“tag”: “today”,
“patterns”: [“today”],
“responses”: [“For rentals today please call 1–800-MYMOPED”, …],
“context_filter”: “rentalday”
}
以這種方法構建的信息庫,如果用戶只是輸入 "today" 而沒有上下文信息,那么這個 “today” 的用戶意圖是不會被處理的。如果用戶輸入的 "today" 是對我們的一個時間回應,即觸動了意圖標簽 "rental" ,那么這個意圖將會被處理。
response('we want to rent a moped')
Are you looking to rent today or later this week?
response('today')
Same-day rentals please call 1-800-MYMOPED
我們上下文信息也改變了:
context
{'123': 'rentalday'}
我們定義我們的 "greeting" 意圖用來清除上下文語境信息,這就像我們打招呼一樣,標志著我們要開啟一個新的對話。我們還添加了 "show_details" 參數,用來幫助我們看到程序里面的信息。
response("Hi there!", show_details=True)
context: ''
tag: greeting
Good to see you again
讓我們再次嘗試輸入 "今天" 這個詞,一些有趣的事情就發生了。
response('today')
We're open every day from 9am-9pm
classify('today')
[('today', 0.5322513580322266), ('opentoday', 0.2611265480518341)]
首先,我們對沒有上下文信息的 "today" 的回應是不同的。我們的分類產生了 2 個合適的意圖,但 "opentoday" 被選中了。所以這個隨機性就比較大,上下文信息很重要!
response("thanks, your great")
Happy to help!
現在需要考慮的事情就是如何將對話放置到具體語境中了。
狀態處理
沒錯,你的機器人將會成為你的私人機器人了,不再是那么大眾化。除非你想要重建狀態,重新加載你的模型和文檔 —— 每次調用你的機器人框架,你都會需要加載一個模型狀態。
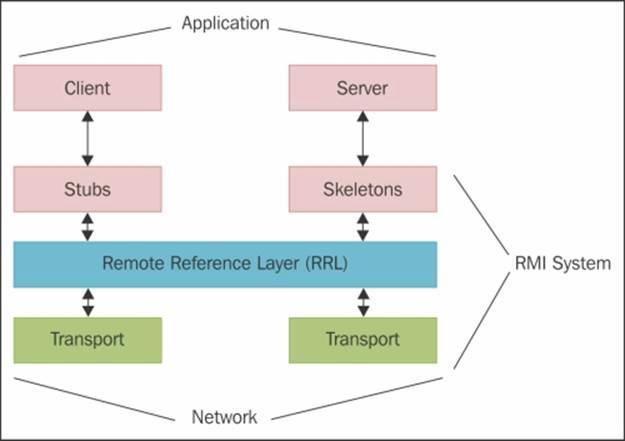
這不是那么困難,你可以在自己的進程中運行一個有狀態的聊天機器人框架,并使用 RPC(遠程過程調用)或 RMI(遠程方法調用)調用它,我推薦使用 Pyro
用戶界面(客戶端)通常是無狀態的,例如:HTTP 或 SMS。
你的聊天機器人客戶端將通過 Pyro 函數進行調用,你的狀態服務將由它處理,是不是很贊。
這里有一個手把手教你如何構建一個 Twilio SMS 機器人客戶端的方法,這里是一個構建 Facebook 機器人的方法。
不要將狀態存儲在局部變量中
所有狀態信息都必須放在諸如字典之類的數據結構中,易于持久化,重新加載或者以原子狀態進行復制。
每個用戶的對話和上下文語境都會保存在用戶 ID 下面,這個ID必須是唯一的。
我們會復制有些用戶的對話信息來進行場景分析,如果這些信息被保存在臨時變量中,那么就非常難來處理,這是一個最大的考慮。
所以,現在你已經學會了如何去構建一個聊天機器人框架,一個使它能記住上下文信息的機器人,已經如何分析文本。未來的聊天機器人也都是能分析上下文語境的,這是一個大趨勢。
我們聯想到意圖的構建會影響上下文的對話反應,所以我們可以創建各種各樣的會話環境。
快去動手試試吧!