高速數據總線kafka介紹
1. Kafka的作用
在大數據系統中,常常會碰到一個問題,整個大數據是由各個子系統組成,數據需要在各個子系統中高性能,低延遲的不停流轉。有沒有一個系統可以同時搞定在線應用(消息)和離線應用(數據文件,日志)?這就需要kafka。Kafka可以起到兩個作用:
- 降低系統組網復雜度。
- 降低編程復雜度,各個子系統不在是相互協商接口,各個子系統類似插口插在插座上,Kafka承擔高速數據總線的作用。
2. Kafka產生背景
Kafka是Linkedin于2010年12月份開源的消息系統,它主要用于處理活躍的流式數據。活躍的流式數據在web網站應用中非常常見,這些數據包括網站的pv、用戶訪問了什么內容,搜索了什么內容等。 這些數據通常以日志的形式記錄下來,然后每隔一段時間進行一次統計處理。
傳統的日志分析系統提供了一種離線處理日志信息的可擴展方案,但若要進行實時處理,通常會有較大延遲。而現有的消(隊列)系統能夠很好的處理實時或者近似實時的應用,但未處理的數據通常不會寫到磁盤上,這對于Hadoop之類(一小時或者一天只處理一部分數據)的離線應用而言,可能存在問題。Kafka正是為了解決以上問題而設計的,它能夠很好地離線和在線應用。
3. Kafka架構

- 生產者(producer):消息和數據產生者
- 代理(Broker):緩存代理
- 消費者(consumer):消息和數據消費者
架構很簡單,Producer,consumer實現Kafka注冊的接口,數據從producer發送到broker,broker承擔一個中間緩存和分發的作用。broker分發注冊到系統中的consumer。
4. 設計要點
(1) 直接使用linux 文件系統的cache,來高效緩存數據。
(2) 采用linux Zero-Copy提高發送性能。傳統的數據發送需要發送4次上下文切換,采用sendfile系統調用之后,數據直接在內核態交換,系統上下文切換減少為2次。根據測試結果,可以提高60%的數據發送性能。Zero-Copy詳細的技術細節可以參考:https://www.ibm.com/developerworks/linux/library/j-zerocopy/
(3) 數據在磁盤上存取代價為O(1)。
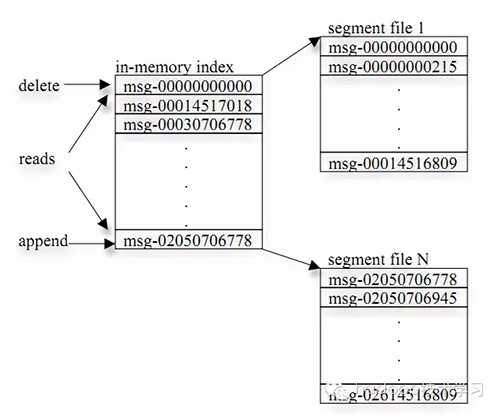
- 以topic來進行消息管理,每個topic包含多個part(ition),每個part對應一個邏輯log,有多個segment組成。
- 每個segment中存儲多條消息(見下圖),消息id由其邏輯位置決定,即從消息id可直接定位到消息的存儲位置,避免id到位置的額外映射。
- 每個part在內存中對應一個index,記錄每個segment中的第一條消息偏移。
- 發布者發到某個topic的消息會被均勻的分布到多個part上(隨機或根據用戶指定的回調函數進行分布),broker收到發布消息往對應part的最后一個segment上添加該消息,當某個segment上的消息條數達到配置值或消息發布時間超過閾值時,segment上的消息會被flush到磁盤,只有flush到磁盤上的消息訂閱者才能訂閱到,segment達到一定的大小后將不會再往該segment寫數據,broker會創建新的segment。
(4) 顯式分布式,即所有的producer、broker和consumer都會有多個,均為分布式的。Producer和broker之間沒有負載均衡機制。broker和consumer之間利用zookeeper進行負載均衡。所有broker和consumer都會在zookeeper中進行注冊,且zookeeper會保存他們的一些元數據信息。如果某個broker和consumer發生了變化,所有其他的broker和consumer都會得到通知。
5. 類似的系統
RocketMQ:國內淘寶團隊參考開源的實現的消息隊列,解決了kafka的一些問題,如優先級問題。
6. 參考資料:
- http://blog.chinaunix.net/uid-20196318-id-2420884.html
- http://dongxicheng.org/search-engine/kafka/
【本文為51CTO專欄作者“大數據和云計算”的原創稿件,轉載請通過微信公眾號獲取聯系和授權】