













達觀數據智能問答技術研究
在機器人圍棋大勝李世石、柯潔之后,人工智能越來越火。作為一項新興技術,智能問答也是人工智能中必不可少的一環。智能問答一般用于解決企業客服、智能資訊等應用場景,實現的方式多種多樣,包括簡單的規則實現,也可以基于檢索實現,還可以通過encoder-decoder框架生成,本文通過幾種常見的問答技術,概要介紹了達觀數據智能問答相關原理研究。
1. 基于規則的智能問答
基于規則的智能問答通常是預先設置了一系列的問答規則,在用戶輸入一個問題時,去規則庫里匹配,看是否滿足某項規則,如果滿足了就返回該規則對應的結果。如規則庫里設置“*你好*”->“你好啊!”,那么用戶在輸入“你好”時,機器人會自動返回“你好啊!”。如果規則庫非常龐大,達到了海量的級別庫,則可對規則建立倒排索引,在用戶新輸入一個問題時,先去倒排索引中查找***的規則集合,再通過這個集合中的規則進行匹配返回。
使用規則庫的智能問答優點是簡單方便,準確率也較高;缺點是規則庫要經常維護擴展,而且覆蓋的范圍小,不能對新出現的問題進行回答。
2. 基于檢索的智能問答
基于檢索的智能問答很像一個搜索引擎,但又和搜索引擎不同,相比搜索引擎而言,智能問答更側重于用戶意圖和語義的理解。它基于歷史的問答語料庫構建索引,索引信息包括問題、答案、問題特征、答案特征等。用戶問問題時,會將問題到索引庫中匹配,首先進行關鍵字和語義的粗排檢索,召回大量可能符合答案的問答對;然后通過語義和其他更豐富的算法進行精排計算,返回***的一個或幾個結果。
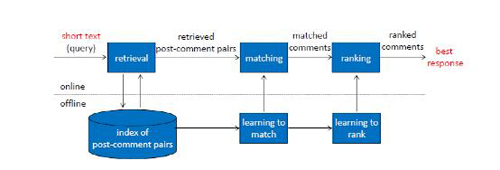
圖1
2.1 粗排策略
粗排策略跟一般的搜索引擎非常類似,主要基于的技術包括粗細粒度分詞、詞重要性計算、核心詞識別、命名實體識別、語義歸一等相關技術,主要是為了在粗排階段盡可能地把相關問題進行召回。
1) 詞重要性計算:通過計算重要性,越能表示問題的詞匯權重越高,在召回時***這些詞匯的候選集越有可能被召回。如:“靠譜的英語培訓機構有哪些?”,在這個問題中,“英語”、“培訓”、“機構”是高權重的詞,“靠譜”是較高權重的詞,“哪些”是較低權重的詞;因此越符合“英語培訓機構”的答案越有可能被召回。
2) 核心詞識別:核心詞就是候選集中必須相關的詞。如“北京住宿多少錢?”
,核心詞是“北京”、“住宿”,如果候選集中沒有這兩個相關的詞,如“上海住宿多少錢?”,“北京吃飯多少錢”,都是不符合問題需求的。
3) 命名實體識別:通過命名實體識別,能協助識別出問題答案中的核心詞,也可以對核心專有名詞進行重要性加權,輔助搜索引擎提升召回效果。
4) 語義歸一也是擴大召回的重要手段,同一個問題可能有很多種問法,不同的問法如果答案不同,或者召回的結果數目不同,就會很讓人煩惱了,比如“劉德華生日是哪天?”、“劉德華出生在哪一天?”,如果不作語義歸一的話,有可能某一個問題都不會召回結果。
2.2 精排策略
通過粗排,搜索引擎已經返回了一大批可能相關的結果,比如500個,如何從這500個問題中找到***問題的一個或者幾個,非常考驗算法精度。一般基于檢索的問答系統都會通過語義或者深度學習的方法尋找最匹配的答案。
1) 基于句子相似度的算法。
基于句子相似度的算法有很多種,效果比較好的有基于word2vec的句子相似度計算和基于sentence2vec的句子相似度計算。基于word2vec計算兩個句子的相似度,就是以詞向量的角度計算***個句子轉換到***個句子的代價:
詞向量有個有趣的特性,通過兩個詞向量的減法能夠計算出兩個詞的差異,這些差異性可以應用到語義表達中。如:vec(Berlin) – vec(Germany) = vec(Paris) – vec(France);通過這個特性能夠用用來計算句子的相似度。假設兩個詞xi, xj之間的距離為ci, j= xi- xj2,這可以認為是xi轉換到xj的代價。可以將句子用詞袋模型d∈Rn表示,模型中某個詞i的權重為di= cij=1ncj,其中ci是詞i在該句子中出現的次數。設置 T∈Rn*n為一個轉換矩陣,Tij表示句子d中詞i有多少權重轉換成句子d’中的詞j,如果要將句子d完全轉換成句子d’,所花費的代價計算如下:
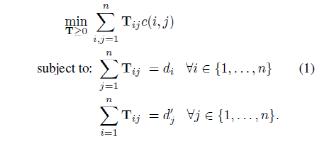
如果用Xd表示句子中的詞向量通過權重di進行加權平均的句向量,可以推導出,句子轉換代價的下限是兩個句向量的歐式距離。
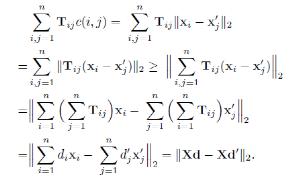
一般這個下限表示兩個短句子相似的程度已經足夠了,如果需要通過完全***化的方法計算minT≥0i, j =1nTijc(i, j)的值,可以通過EMD solver算法計算。
2) 基于深度學習計算問答匹配程度。
基于句向量的距離計算句子相似度,可以cover大部分的case,但在句子表面相似,但含義完全不同的情況下就會出現一些問題,比如“我喜歡冰淇淋”和“我不喜歡冰淇淋”,分詞為“我”,“不”,“喜歡”,“冰淇淋”,兩個句子的相似度是很高的,僅一字“不”字不同,導致兩個句子意思完全相反。要處理這種情況,需要使用深度模型抓住句子的局部特征進行語義識別。
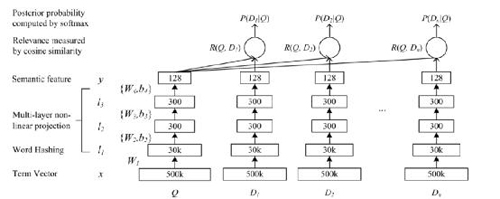
圖2
如圖所示,Q是用戶的問題,D是返回的各個答案。對于某一個問答句子,首先將它映射到500k大小的BOW向量Term Vector里。因為Term Vector是稀疏矩陣,可以使用Word Hashing或者其他Embedding的方法將其映射到30k大小的詞向量空間里。接下來的l1, l2, l3層就是傳統的MLP網絡,通過神經網絡得到query和document的語義向量。計算出(D,Q)的cosine similarity后,用softmax做歸一化得到的概率值是整個模型的最終輸出,該值作為監督信號進行有監督訓練。模型通過挖掘搜索點擊日志構造的query和對應的正負document樣本(點擊/不點擊),輸入DSSM進行訓練。
3) 基于卷積神經網絡計算問答匹配程度。
句子中的每個詞,單獨來看有單獨的某個意思,結合上下文時可能意思不同;比如“Microsoft office”和“I sat in the office”,這兩句話里的office意思就完全不一樣。通過基于卷積神經網絡的隱語義模型,我們能夠捕捉到這類上下文信息。
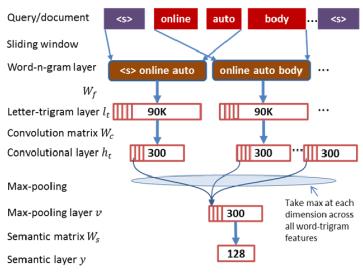
圖3
如圖所示,先通過滑窗構造出query或document中的一系列n-gram terms,比如圖中是Word-n-gram layer中的trigram;然后通過word-hashing或者embedding將trigram terms表示為90k的向量;通過卷積向量Convolution matrix Wc對每個letter-trigram向量作卷積,可以得到300維的卷積層Convolutional layer;***通過max-pooling取每個維度在Convolutional layer中的***值,作為文本的隱語義向量。模型也是通過挖掘搜索日志進行有監督訓練。
通過卷積神經網絡,能得到句子中最重要的信息。如下面一些句子,高亮的部分是卷積神經識別的核心詞,它們是在300維的Max-pooling層向量里的5個***神經元激活值,回溯找到原始句子中的詞組。
microsoft office excel could allow remote code execution
welcome to the apartment office
4) 基于主題模型計算問答匹配程度。
短文本一般詞語比較稀疏,如果直接通過共現詞進行匹配,效果可能會不理想。華為諾亞方舟實驗室針對短文本匹配問題,提出一個DeepMatch的神經網絡語義匹配模型,通過(Q, A)語料訓練LDA主題模型,得到其topic words,這些主題詞用來檢測兩個文本是否有語義相關。該模型還通過訓練不同“分辨率”的主題模型,得到不同抽象層級的語義匹配(“分辨率”即指定topic個數,高分辨率模型的topic words通常更加具體,低分辨率的topic words通常更加抽象)。在高分辨率層級無共現關系的文本,可能在低分辨率存在更抽象的語義關聯。DeepMatch模型借助主題模型反映詞的共現關系,可以避免短文本詞稀疏帶來的問題,并且能得到不同的抽象層級的語義相關性。
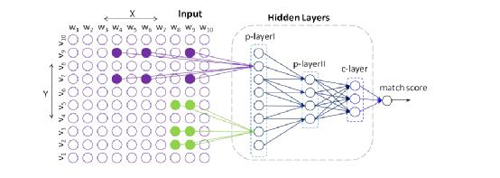
圖4
如圖所示,綠色和紫色塊分別表示在同一個分辨率下不同的主題在X和Y文本中***的主題詞塊,與上一層分辨率(p-layerII)的主題的關聯通過是否與上一層的主題詞塊有重疊得到。如此通過多層的主題,能夠構建出神經網絡,并使用有監督的方式對相關權重進行訓練。
3. 基于產生式的智能問答
基于產生式的智能問答系統,主要是通過seq2seq的方式,通過一個翻譯模型的方式進行智能回答,其中問題是翻譯模型的原語言,答案是翻譯模型的目標語言。Seq2seq模型包含兩個RNN,一個是Encoder,一個是Decoder。Encoder將一個句子作為輸入序列,每一個時間片處理一個字符。Decoder通過Encoder生成的上下文向量,使用時間序列生成翻譯(回答)內容。(達觀數據 江永青)
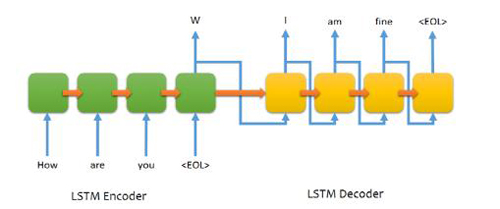
圖5
在Encoder中,每一個隱藏的狀態影響到下一個隱藏狀態,并且***一個隱藏狀態可以被認為是序列的總結信息。***這個狀態代表了序列的意圖,也就是序列的上下文。通過上下文信息,Decoder會生成另一個結果序列,每一個時間片段,根據上下文和之前生成的字符,Decoder都會生成一個翻譯字符。
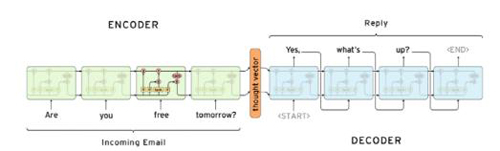
圖6
這個模型有一些不足:首先是這個模型不能處理變長的字符序列,而一般的翻譯模型和問答模型中的序列長度都是不定的。另外一個是僅通過一個context變量,并不足以完全表示輸入序列的信息。在序列變得很長之后,大量的信息會被丟棄,因此需要多個context變量及注意力機制進行處理。
3.1 Padding
通過Padding方式,可以將問答字符串固定為定長的序列,比如使用如下幾個序列進行Padding:
EOS : 序列的結束
PAD : Padding字符
GO : 開始Decode的字符
UNK : 不存在字典中的字符
對于問答對:
Q : 你過得怎樣?
A : 過得很好。
通過padding將生成固定的如下字符串:
Q : [ PAD, PAD, PAD, PAD, “?”, “樣”, “怎”, “得”, “過”, “你” ]
A : [ GO, “過”, “得”, “很”, “好”, “。”, PAD, EOS, PAD, PAD ]
3.2 注意力機制
Seq2Seq的一個限制是輸入序列的所有信息只能編碼到一個定長的數組context里,如果輸入序列變長的話,我們很容易會丟失信息,因此Seq2Seq模型對長輸入序列效果很差。通過引入一個注意力機制,可以讓Decoder在翻譯(回答)時按權重選擇性地提取輸入的各個隱層變量進行計算,這樣就能在產生輸出時考慮到輸入的關鍵信息了。
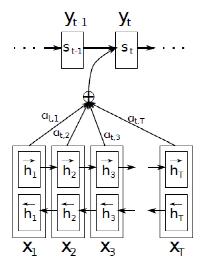
圖7
如圖中,每個輸入的狀態yi除了與前一個狀態yi-1,輸入的隱藏狀態si有關之外,還與注意力向量ci有關。

這里的注意力向量不再是單獨的一個c,而是對于每一個輸入yi都有對應的ci,它的計算方式如下:
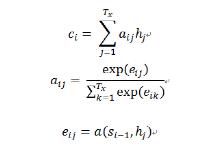
eij是一個對準模型,它計算了位置為i的輸入和位置為j的輸出之間關系的比重。它通過輸出的隱藏狀態si – 1(用來計算si及輸出狀態yi)和輸入序列的第j個隱藏變量hj計算而得。
通過將問答對以翻譯模型進行訓練(問題作為原語言,答案作為目標語言),在新來一個問題時,可以在沒有任何歷史相似問題的情況下得到較接近的答案。然而因為目前的翻譯模型還不夠成熟,經常翻譯出莫名奇妙的答案,讓人摸不著頭腦,如下所示:
你好->你好
很高興認識你->我也是
你是誰->我是說,我們是朋友
我們是朋友嗎->不是
我們為什么不是朋友->我們不知道,我們都不知道你們在哪里
達觀數據很厲害->我們知道
通過產生式的翻譯模型,即使基于大量的語料訓練,很有可能效果還是不夠理想,因此經常作為基于規則和檢索的問答系統的輔助方式。
4. 小結
本文介紹了智能問答技術的相關原理,講述了實現智能問答的一般方法。借助于深度學習技術,智能問答效果比傳統機器學習提升20%左右。達觀數據擁有多年的自然語言處理技術積累,并且緊跟行業潮流,在文本語義、信息檢索、智能問答方面不斷深耕,助力各個企業享受大數據技術的成果。
【本文為51CTO專欄作者“達觀數據”的原創稿件,轉載可通過51CTO專欄獲取聯系】


















