htcap:一款實用的遞歸型Web漏洞掃描工具
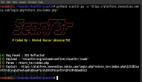
今天給大家介紹的是一款名叫 htcap 的開源 Web 漏洞掃描工具,它通過攔截 AJAX 調用和頁面 DOM 結構的變化并采用遞歸的形式來爬取單頁面應用(SPA)。htcap 并不是一款新型的漏洞掃描工具,因為它主要針對的是漏洞掃描點的爬取過程,然后使用外部工具來掃描安全漏洞。在 htcap 的幫助下,我們就可以通過手動或自動滲透測試來對現代 Web應用進行漏洞掃描了。
一、環境要求
- Python 2.7
- PhantomJS v2
- Sqlmap
- Arachni
二、工具下載和運行
- $ git clonehttps://github.com/segment-srl/htcap.git htcap
- $ htcap/htcap.py
三、命令行參數
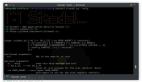
- $ htcap crawl -h
- usage: htcap [options] url outfile
- Options:
- -h 幫助菜單
- -w 覆蓋輸出文件
- -q 不顯示處理過程信息
- -mMODE 設置爬取模式:
- - passive:不與頁面交互
- - active:觸發事件
- - aggressive:填寫輸入值并爬取表單 (默認)
- -sSCOPE 設置爬取范圍:
- - domain:僅爬取當前域名 (默認)
- - directory:僅爬取檔期那目錄 (以及子目錄)
- - url: 僅分析單一頁面
- -D 最大爬取深度 (默認: 100)
- -P 連續表單的最大爬取深度 (默認: 10)
- -F 主動模式下不爬取表單
- -H 保存頁面生成的HTML代碼
- -dDOMAINS 待掃描的域名,多個域名用逗號分隔 (例如*.target.com)
- -cCOOKIES 以JSON格式或name=value鍵值對的形式設置cookie,多個值用分號隔開
- -CCOOKIE_FILE 包含cookie的文件路徑
- -rREFERER 設置初始引用
- -xEXCLUDED 不掃描的URL地址,多個地址用逗號隔開
- -pPROXY 設置代理,protocol:host:port- 支持'http'或'socks5'
- -nTHREADS 爬蟲線程數量 (默認: 10)
- -ACREDENTIALS 用戶HTTP驗證的用戶名和密碼,例如username:password
- -UUSERAGENT 設置用戶代理
- -tTIMEOUT 分析一個頁面最長可用時間(默認300)
- -S 跳過初始url檢測
- -G 分組query_string參數
- -N 不使用標準化URL路徑 (保留../../)
- -R 最大重定向數量 (默認10)
- -I 忽略robots.txt
四、htcap簡單介紹
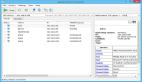
htcap的掃描過程分為兩步,htcap首先會盡可能地收集待測目標可以發送的請求,例如url、表單和AJAX請求等等,然后將收集到的請求保存到一個SQLite數據庫中。爬取工作完成之后,我們就可以使用其他的安全掃描工具來測試這些搜集到的測試點,最后將掃描結果存儲到剛才那個SQLite數據庫之中。
htcap內置了sqlmap和arachni模塊,sqlmap主要用來掃描SQL注入漏洞,而arachni可以發現XSS、XXE、代碼執行和文件包含等漏洞。
htcap所采用的爬蟲算法能夠采用遞歸的方式爬取基于AJAX的頁面,htcap可以捕獲AJAX調用,然后映射出DOM結構的變化,并對新增的對象進行遞歸掃描。當htcap加載了一個測試頁面之后,htcap會嘗試通過觸發所有的事件和填充輸入值來觸發AJAX調用請求,當htcap檢測到了AJAX調用之后,htcap會等待請求和相關調用完成。如果之后頁面的DOM結構發生了變化,htcap便會用相同算法對新增元素再次進行計算和爬取,直到觸發了所有的AJAX調用為止。
1. 爬蟲模塊
Htcap支持三種爬取模式:被動型、主動型和攻擊型。在被動模式下,htcap不會與任何頁面進行交互,這意味著爬蟲不會觸發任何頁面事件,它只會收集頁面現有的鏈接。在這個模式下,htcap就跟普通的Web爬蟲一樣,只會收集頁面標簽中的鏈接。在主動模式下,htcap會觸發所有發現的事件,相當于模擬用戶與頁面進行交互,但不填寫任何表單數據。在攻擊模式下,htcap會向所有掃描到的表單和輸入框中填寫測試數據,即盡可能地模擬用戶與頁面進行交互。