













計算架構:分布式調度技術演變

1 引言
什么是調度?通常所說的調度(schedule)是和時間有關的,比如我今天的schedule很緊(如圖1所示)。時間作為唯一的不可逆轉的資源,一般是劃分為多個時間片來使用。就計算機而言,由于CPU的速度快的多,所以就有了針對CPU時間片的調度,讓多個任務在同一個CPU上運行起來。然而這是一個假象,某一時刻CPU還是單任務運行的。
圖1 時間片的劃分
為了在同一時間運行更多的任務,或者多個處理器一起工作完成一個任務目標,就需要一個協調者——這就成為一個分布式系統,就單個數據中心或者小范圍來說,這就是集群。如果讓一個分布式系統運行多個任務,每個任務對分布式系統中的資源必然產生競爭,時間調度就發展到資源調度。
宏觀上來說調度主題包括了單機操作系統、C/S系統、B/S系統、P2P系統、集群系統、分布式系統等等,以及網絡協議棧、存儲協議棧的各種調度機制。本文主要總結了集群調度發展的三個階段:宏調度、兩層調度和共享狀態調度,并比較了三者之間的優缺點。
2 集群調度
2.1 宏調度(Monolithic schedulers)
宏調度:在同一個代碼模塊中實現調度策略,單個實例,沒有并行。常見于HPC(high-performance computing)世界中。
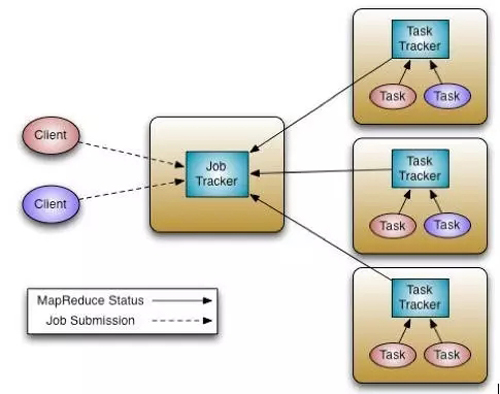
圖2 Hadoop1和MapReduce 的宏調度架構
如圖2所示,以為MapReduce為例,一個稱之為JobTracker的Master進程是所有MapReduce任務的中心調度器。每一個節點上面都運行一個TaskTracker進程來管理各個節點上的任務。各個TaskTracker要和Master節點上的JobTracker通信并接受JobTracker的控制。和大多數資源管理器類似,MapReduce的JobTracker支持兩種調度策略,Capacity調度策略和Fair調度策略。
在JobTracker中,資源的調度和作業的管理功能全部放到一個進程中完成。這種設計方式的缺點是擴展性差:首先,集群規模受限;其次,新的調度策略難以融入現有代碼中,比如之前僅支持批處理作業,現在要支持流式作業,而將流式作業的調度策略嵌入到中央式調度器中是一項很難的工作。
2.2 靜態分區(Statically partitioned schedulers)
基于靜態分區的資源劃分和調度也被稱為云計算中的調度,通過在云平臺中分配和定義虛擬機角色,實現資源集合的全面控制。業務系統往往部署在專門的、靜態劃分的集群的一個子集上——把集群劃分為不同的部分,分別支持不同的業務。現在大多數企業級的云計算都是采用這樣計劃經濟式的資源分配方式——在系統部署之前做好容量規劃和資源分配
2.3 兩層調度(Two-level scheduling)
為了處理宏調度和集群靜態分區的種種限制,一個直接的解決方案就是兩層調度。通過引入一個中央的協調組件來決定每一個子集群需要分配的資源數量,從而動態的調整分配給每一個調度器(框架調度器)的資源。兩層調度本質上是在調度中分離資源分配和任務分配,讓渡一部分決策權力給應用框架,解決不同應用框架的需求異構問題。如圖3所示,YARN為上層不同的應用框架提供了統一的資源調度層。后文對Mesos的介紹一節會詳細介紹兩層調度的需求背景。
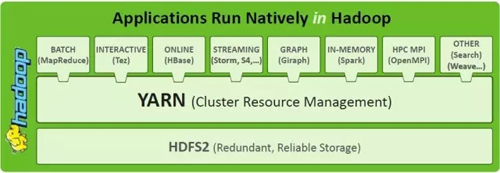
圖3 Hadoop1和MapReduce 的宏調度架構
各個框架調度器并不知道整個集群資源使用情況,只是被動的接收資源。中央協調組件僅將可用的資源推送給各個框架,而框架自己選擇使用還是拒絕這些資源。一旦框架(比如JobTracker)接收到新資源后,再進一步將資源分配給其內部的各個應用程序(各個MapReduce作業),進而實現雙層調度。
雙層調度器有兩個缺點,其一,各個框架無法知道整個集群的實時資源使用情況;其二,采用悲觀鎖,并發粒度小。
2.3.1 YARN
YARN被稱之為Apache Hadoop Next Generation Compute Platform,是hadoop1和hadoop2之間***的區別如圖4所示。
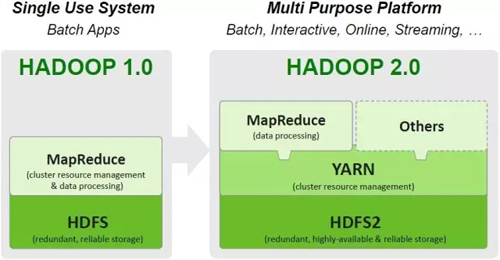
圖4 在Hadoop 2.0中引入YARN
Hadoop2(MRv2)的基礎思想就是把JobTracker的功能劃分成兩個獨立的進程:全局的資源管理ResourceManager和每個進程的監控和調度ApplicationMaster。這個進程可以是Map-Reduce 中一個任務或者是DAG中一個任務。
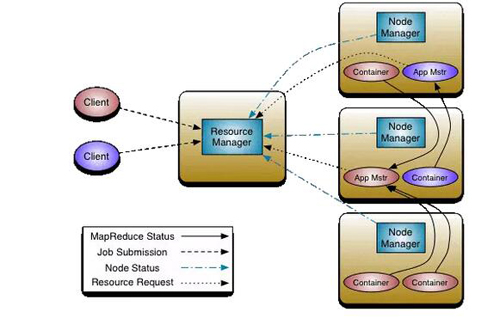
圖5 在Hadoop 2.0中引入YARN
在YARN的設計中,集群中可以有多個ApplicationMasters,每一個ApplicationMasters可以有多個Containers (例如,圖5中有兩個ApplicationMasters,紅色和藍色。紅色的有三個Containers,藍色的有一個Container)。關鍵的一點是ApplicationMasters 不是ResourceManager的部分,這就減輕了中心調度器的壓力,并且,每一個ApplicationMasters都可以動態的調整自己控制的container。
而 ResourceManager 是一個純粹的調度器(不監控和追蹤進程的執行狀態,也不負責重啟故障的進程),它唯一的目的就是在多個應用之間管理可用的資源(以Containers的粒度)。ResourceManager是資源分配的***權威。如果說ResourceManager是Master,NodeManager就是其slave。ResourceManager并且支持調度策略的插件化,CapacityScheduler 和 FairScheduler就是這樣的插件。
ApplicationMaster 負責任務提交,通過協商和談判從ResourceManager那里以Containers的形式獲得資源(負責談判獲得適合其應用需要的Containers)。然后就track進程的運行狀態。ApplicationMasters是特定于具體的應用,可以根據不同的應用來編寫不同的ApplicationMasters。例如,“YARN includes a distributed Shell framework that runs a shell script on multiple nodes on the cluster. ” 另外,ApplicationMaster 提供自動重啟的服務。ApplicationMaster可以理解為應用程序可以自己實現的接口庫。
ApplicationMasters請求和管理Containers。Containers指定了一個應用在某一臺主機上可以使用多少資源 (包括memory, CPU等) ,這類似于HPC調度中的資源池。ApplicationMaster一旦從 ResourceManager那里獲得資源,它就會聯系NodeManager 來啟動某個特定的任務。例如如果使用 MapReduce 框架,這些任務可能就是Mapper 和 Reducer 進程。不同的框架會有不同的進程。
NodeManager是每一個機器上框架代理,負責該機上的Containers,并且監控可用的資源(CPU, memory, disk, network)。并且資源狀態報告給ResourceManager。
表面上看來,YARN也是一個兩層調度。在YARN中,資源請求從Application Masters發出到一個中心的全局調度器上,中心調度器根據應用的需要在集群中的多個節點上分配資源。但是YARN中的Application Masters提供的僅僅是一個任務管理服務,并不是一個真正的二層調度器。因此本質上YARN仍舊是一個宏調度架構。截止目前,YARN只支持資源類型(內存)的調度。
Hadoop2(MRv2)的API是后向兼容的,支持Map-Reduce的任務只需要重新編譯一下就可以運行在Hadoop2(MRv2)上。
2.3.2 Mesos
大量分布式計算框架(Hadoop, Giraph, MPI, etc)的出現,每一個計算框架需要管理自己的計算集群。這些計算框架往往把任務分割成很多小任務,讓計算靠近數據,從而可以提高集群的利用率。但是這些框架都是獨立開發的,不可能在應用框架之間共享資源。形象的表示如圖6所示。
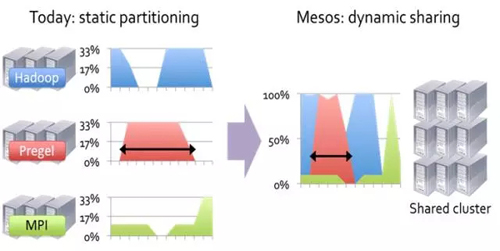
圖6 集群的靜態分區和動態共享
我們希望在同一個集群上可以運行多個應用框架。 Mesos是通過提供一個通用資源共享層,多個不同的應用框架可以運行在這個資源共享層之上。形象的表示如圖7所示。

圖7 Mesos為不同應用框架提供統一調度接口
但我們不希望使用簡單的靜態分區的方法,如圖8所示。
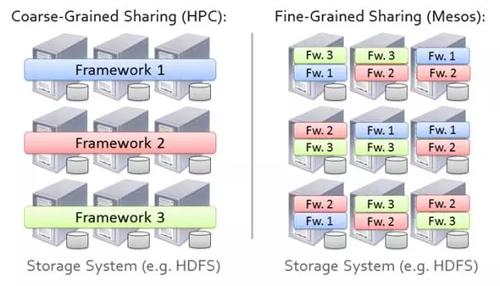
圖8 集群內靜態分區
Mesos的英文定義為:“ Mesos, which is an open source platform for fine-grained resource sharing between multiple diverse cluster computing frameworks.”
Mesos***的好處就是提高集群的利用率。可以很好的隔離產品環境和實驗環境,可以同時并發運行多個框架。其次,可以在多個集群之間共享數據。第三,可以降低維護成本。 Mesos***挑戰是如何支持大量的應用框架。因為每一個框架都有不同的調度需求:編程模型、通信范型、任務依賴和數據放置。另外 Mesos的調度系統需要能夠擴展到數千個節點,運行數百萬個任務。由于集群中的所有任務都依賴于 Mesos,調度系統必須是容錯和高可用的。
Mesos的設計決策(設計哲學):不采用中心化的,設計周全的(應用需求,可用資源,組織策略),適用于所有任務的全局調度策略。而采用委派調度任務給應用框架(把調度和執行的功能交給應用框架)。 Mesos聲稱:這樣的設計策略可能不會達到全局***的調度,但在實際運行中出奇的好,可以使得應用框架近乎***的達到目標。其聲稱中的優點主要有兩個:應用框架的演化獨立和保持 Mesos的簡潔。
Mesos的主要組件包括Master daemon,Slave daemons和在slaves之上運行的 Mesos applications (也被稱為 frameworks)(如圖9所示)。Master根據相應的策略(公平調度,優先級調度等)決定給每一個應用分配多少資源。模塊化架構支持多種策略。Resource offer是資源的抽象表示,基于該資源,應用框架可以在集群中的某個node上實例化分配offer,并運行任務。每一個Resource offer 就是一個分布在多個node上的空閑資源列表。Mesos基于一定的算法策略(如公平調度)決定有多少資源可以分配給應用框架,而應用框架決定使用(接受)哪些資源,運行哪些任務。Mesos上運行的應用框架由兩部分組成:應用調度器和slave上運行代理。應用調度器向 Mesos注冊。Master決定向注冊的框架提供多少資源,應用調度器決定Master分配的資源中哪些來使用。調度完成之后,應用調度器把接受的資源發送給 Mesos,從而決定了使用哪些slave。然后應用框架中的任務的執行可以在slave上運行。當任務很小并且是短期任務(每個任務都頻繁的讓渡自己握著的資源的時),Mesos工作的很好。
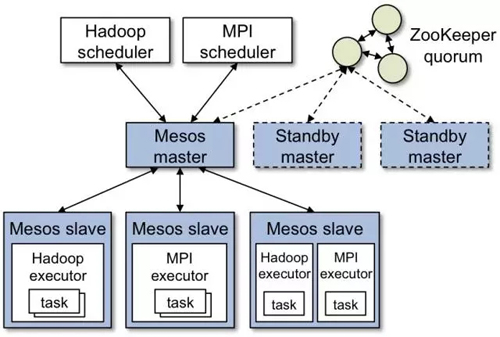
圖9 Mesos調度框架
在 Mesos中,一個中央資源分配器動態的劃分集群,分配資源給不同的調度框架(scheduler frameworks)。資源可以在不同的調度框架之間以“offers”的形式任意分配,offers表示了當前可用的資源。資源分配器為了避免不同調度框架對同一資源沖突申請,只允許一次只能分配給一個調度框架。在調度決策的過程中,資源分配器實質上起到了鎖的作用。因此 Mesos中的并發調度是悲觀策略的。
Master使用resource offer機制在多個框架之間細粒度的共享資源。每一個resource offer空閑資源列表,分布在多個slave上。Master決定給每一個應用框架提供多少資源,依據是公平方法或者優先級方法。第三發可以以可插拔模塊的方式定制策略。
Reject機制:駁回 Mesos提供的資源方案。為了保持接口的簡單性, Mesos不允許應用框架指定資源需求的限制信息,而是允許應用框架拒絕 Mesos提供的資源方案。應用框架如果遇到沒有滿足其需求的資源提供方案,則會拒絕等待。 Mesos聲稱拒絕機制可以支持任意復雜的資源限制,同時保持擴展性和簡單。
Reject機制帶來的一個問題是在應用框架收到一個滿足其需求的方案之前可能需要等待很長時間。由于不知道應用框架的需求, Mesos可能會把同一個資源方案發給多個應用框架。因此,引入fliter機制: Mesos中的一個調度框架使用filter來描述它期望被服務的資源類型(允許應用框架設置一個filter表示該應用框架會永遠的拒絕某類資源)。因此,它不需要訪問整個集群,它只需要訪問它被offer的節點即可。這種策略帶來的缺點是不能支持基于整個集群狀態的搶占和策略:一個調度框架不知道分配給其他調度框架的資源。 Mesos提供了一種資源儲存的策略來支持Gang調度。例如,應用框架可以指定一個其可以運行node白名單列表。這不是動態的集群分區嗎? Mesos進一步解釋filter機制:filter只是一個資源分配模型的性能優化方案,應用框架有哪些任務運行在哪些node上最終決定權。
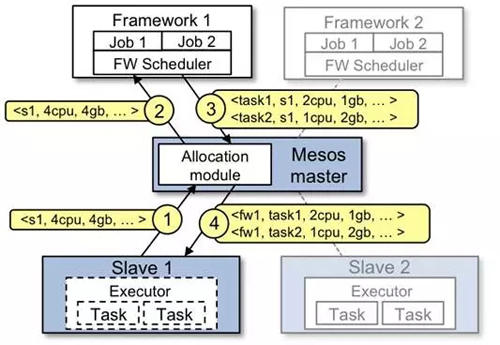
圖10 Mesos調度流程
Mesos任務調度過程如圖10所示,具體流程如下:
Slave 1 向Master匯報它有4個CPUs 和 4 GB的空閑內存,Master 的allocation模塊會根據相應的分配策略通知framework 1 可以使用所有可用資源。
Master把slave 1上的可用資源發送給framework 1(以resource offer的方式)。
framework的調度器響應Master調度器:準備在slave上運行兩個任務,使用的資源分別是:***個任務<2 CPUs, 1 GB RAM> ,第二個任務 <1 CPUs, 2 GB RAM> 。
***,Master把任務發送給slave,然后把相應的資源分配給framework的執行器。然后執行器啟動兩個任務。由于slave1上還有1 CPU 和1 GB的內存沒有分配,分配模塊可以把資源分配給framework 2。
另外,Mesos Master的Allocation module是pluggable。使用ZooKeeper 來實現 Mesos Master的Failover。
2.4 狀態共享調度(Shared-state scheduling)
在狀態共享調度中,每一個調度器都可以訪問整個集群狀態。當多個調度器同時更新集群狀態時使用樂觀并發控制。Shared-state調度可以解決兩層調度的兩個問題:悲觀并發控制所帶來的并行限制和調度框架對整個集群資源的可見性。樂觀并發控制所帶來的問題是當樂觀假設不成立時,需要重新調度。
為了克服雙層調度器的以上兩個缺點(Omega paper主要關注了這個問題),Google開發了下一代資源管理系統Omega,Omega是一種基于共享狀態的調度器,該調度器將雙層調度器中的集中式資源調度模塊簡化成了一些持久化的共享數據(狀態)和針對這些數據的驗證代碼,而這里的“共享數據”實際上就是整個集群的實時資源使用信息。一旦引入共享數據后,共享數據的并發訪問方式就成為該系統設計的核心,而Omega則采用了傳統數據庫中基于多版本的并發訪問控制方式(也稱為“樂觀鎖”, MVCC, Multi-Version Concurrency Control),這大大提升了Omega的并發性。在Omega中沒有中心的資源分配器,調度器自己做出資源分配的決策。
2.4.1 Omega
宏調度的缺點是難以增加調度策略和專門的實現,并且不能隨著集群的擴展而擴展。兩層調度確實可以提供靈活性和并行性,但是在實踐中他們的資源可見性卻是保守的,難以適應一些挑剔型的任務和一些需要訪問整個集群資源的任務。Omega的解決方案是提出了一個新的并行調度框架:基于共享狀態的、無鎖的、樂觀并發控制,可擴展的。
如圖11所示,Omega中沒有中心的資源分配器,所有的資源分配決策都是由應用的調度器自己完成的。Omega維護了一個成為cell state的資源分配狀態信息主拷貝。每一個應用的調度器都維護了一個本地私有的,頻繁更新的cell state拷貝,用來做調度決策。調度器可以看到全局的所有資源,并根據權限和優先級來自以為是的要求需要的資源。當調度器決定資源方案時,以原子的方式更新共享的cell state:大多數時候這樣commit將會成功(這就是樂觀方法)。當沖突發生時,調度決策將會以事務的方式失敗。無論調度成功還是失敗,調度器都會重新同步本地的cell state和共享的cell state。然后,如果需要,重啟調度過程。
Omega的調度器完全是并行的,不需要等待其他調度器。為了避免沖突造成的饑餓,Omega調度器使用增量調度——Accept all but the conflict things,這樣可以避免資源囤積。如果使用all or nothing 的策略可以使用Gang調度(Either all tasks of a job are scheduled together, or none are, and the scheduler must try to schedule the entire job again.)。Gang調度要等待所有資源就緒,才commit整個任務,就造成了資源囤積。
每一個應用調度器都可以實現自己的調度策略。但是它們必須就資源分配和任務的優先級達成一致。兩層調度的中心資源管理器可以輕松實現這一點。這是一個開放的話題,可以進一步討論:Google認為公平性不是一個關鍵需求,各個調度器只是滿足自己的業務需求。因此,限制每一個應用調度器的資源上限和任務提交上限。
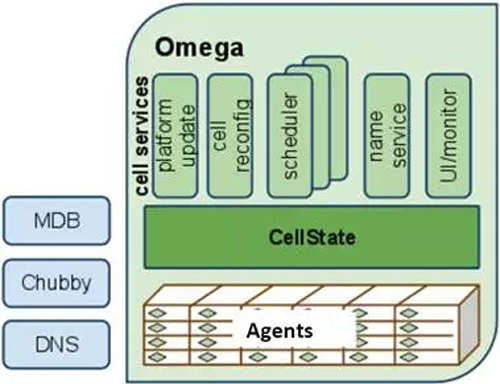
圖11 Omega調度框架
2.4 對比分析
集群調度的主要目標是提高集群的利用率和使用效率。如圖12所示為三種調度方式。如圖13所示為三種調度方式。
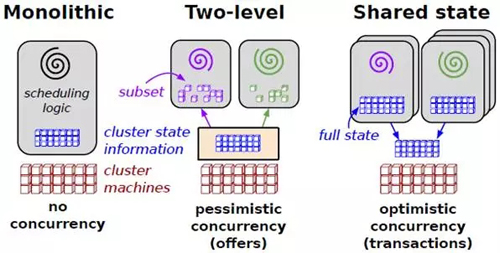
圖12 三種調度方式的對比
宏調度(Monolithic schedulers)為所有任務都使用一個中心調度算法。其缺點是不易增加新的調度策略,也不能隨著集群的擴展而擴展。
兩層調度(Two-level schedulers)本質上是在調度中分離資源分配和任務分配。使用一個動態資源管理器提供計算資源或者存儲資源給多個并行的調度框架。每一個調度框架所擁有的都是一個整個資源的一個子集。為什么是一個動態資源管理器呢?是相對于靜態的集群分區來說的。我們可以靜態的把集群分為幾個區,分別服務于不同的應用。上面的動態資源管理器完成工作就是把靜態的分區工作動態化。由于兩層調度無法處理難以調度的挑剔任務,且不能根據整個集群的狀態做出決策,Google引入共享狀態調度架構。
共享狀態調度(Shared state schedulers)使用無鎖的樂觀并發控制算法。Omega,Google的下一代調度系統中使用了該架構。那么對比起來,兩層調度(Two-level schedulers)本質上是悲觀調度算法。
在Omega看來, Mesos的offer 的機制本質上是一個動態的過濾機制,這樣 Mesos Master向應用框架提供的只是一個資源池的子集。當然可以把這個子集擴大為一個全集,也就是Share state的,但其接口依然是悲觀策略的。
在Omega看來,YARN中的Application Masters提供的僅僅是一個任務管理服務,并不是一個真正的二層調度器。其次,到目前為止,YARN只支持一種資源類型。另外,盡管YARN中的Application Masters可以請求一個特定節點的資源,但是其具體策略是不清晰的。
圖13所示幾種調度策略的對比:

圖13 調度策略的對比(包含靜態分區)
3下一步工作
集群調度技術仍在發展之中,OSDI 16將會發布一些***的關于調度的文章,包括Google的Rapid:Fast, Centralized Cluster Scheduling at Scale,后面會支持關注。資源感知調度。利用機器學習從歷史負載變化中預測資源需求模型,為調度決策提供依據。
【本文是51CTO專欄作者石頭的原創文章,轉載請通過作者微信公眾號補天遺石(butianys)獲取授權】






















