對于容器環境來說 全棧監控究竟意味著什么?
對于大多數人來說,“全棧”(Full Stack)的意思很好理解。但是如果我們的話題涉及到監控容器環境呢?整個事情就會開始變得有些模糊了。在這篇文章中,筆者探索了在這樣的一個環境下,獲得全棧可見性的不同方面和可能會遇到的一些挑戰。
到底什么全棧?
“全棧工程師”這個術語在2010年初被提出,表示在整個應用程序堆棧中具有廣泛技能的開發人員。包括前端和后端應用程序組件的組合,甚至包括基礎設施層的代碼體現。使用許多不同的應用程序組件或微服務的容器化應用程序的趨勢,增加了現代應用程序堆棧的復雜性。甚至有人批評了“全棧工程師”這個術語。
雖然對于一個人來說,了解應用程序每個部分的開發細節可能是不現實的(除非非常簡單),但是應用程序在生產環境中運行時,通常需要堆棧的所有層都具有可見性。這允許開發人員在應用程序或基礎設施的適當部分中快速識別問題并采取相應的行動。所以,在這篇文章中,我們回來探索一個容器化應用程序的“全棧”可見性或監視方式。例如,堆棧通常是什么樣子的?棧的不同層的相關度量是什么?收集和分析所有這些度量標準需要什么功能?
容器堆棧是什么樣的?
在筆者的演示中,經常會使用下面的圖片來說明容器化應用程序中最重要的層是什么,并討論傳統的單片應用程序之間的一些重要區別。實際上,隨著容器的使用和一些編排平臺的使用,還引入了額外的抽象層。現在,從所有這些層收集度量并將它們綁定在一起是非常重要的,能方便我們完全理解一個容器化的應用程序是如何工作的。
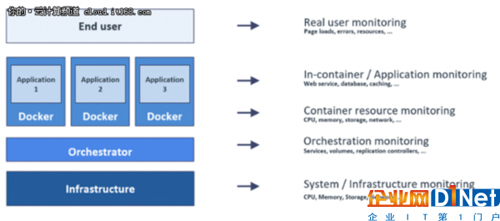
需要收集哪些指標?
根據上面的圖片,為了獲得我們的應用程序的全棧可見性,我們需要從下面的層中收集性能指標:
·在基礎設施中,我們希望收集不同的資源指標,比如CPU、內存、磁盤、網絡等等,可能來自物理服務器或虛擬服務器,也可能是云實例。在后一種情況下,這些指標通常可以通過某種API(如Amazon Cloudwatch)來訪問,同樣包括我們在云平臺上使用的服務的其他指標。
·通常,一個協調器用于幫助基礎設施上的容器的部署、擴展和管理。Kubernetes(或者是Red Hat OpenShift之類的產品)和Docker Swarm是***的技術。在這一層,我們希望了解容器計數和容器動態,例如縮放事件。從協調器中,我們還可以收集關于容器如何與服務綁定的服務定義和關系。這允許我們在服務級別進行報告,例如特定服務的容器數量或其他相關指標。
·對于容器本身,我們還希望了解每個容器和每個服務的資源度量,以及容器生命周期事件。此外,我們希望了解容器內的應用程序是如何運行的。這種所謂的容器監控為我們提供了針對容器內運行的不同服務的應用程序特定的度量標準。
·***,我們希望看到對最終用戶的影響,并理解作為應用程序的消費者所獲得的性能。這通常包括頁面加載時間、錯誤等前端指標,有時甚至可以添加業務指標來“監視真正重要的事情”。
其他的考慮
從這些層收集不同的度量標準本身已經是一個挑戰。大多數監控工具只關注其中的一個子集,因為它們是為傳統的單片應用程序開發的。現代容器監控工具應該與上面提到的所有層進行集成,以提供完整的圖像以及防止出現盲點。
但這并不僅僅局限于度量收集。還有一些其他重要的考慮事項,與度量指標和事件的收集方式有關。
·自動儀表:考慮到容器的短暫特性,新容器在啟動時自動監控是至關重要的。這包括認識到已經啟動了一個新的容器,以及在內部運行的服務,以及如何監視這些服務。例如,在CoScale中,我們使用一個豐富的插件庫來監控來自已知服務的應用程序特定指標,如NGINX、Redis、MongoDB和許多其他服務。
·另外,當將新節點添加到集群時,重要的是這些節點配置,而且配置了正確的監視代理和設置,這樣你的監視就可以與環境進行伸縮。這可以通過在Kubernetes中使用“DaemonSets”的概念或Docker Swarm的全球服務來完成。
·另一個主要的考慮因素是監視代理運行的位置和它們生成的開銷。這是特別相關的,因為容器是輕量級且不可變的結構,應該盡可能少地受到影響。一些監控工具需要將代理添加到容器映像中,或者作為sidecar容器,這通常會增加大量的開銷。其他工具,例如CoScale,只需要每個節點上的一個代理(通常是運行它自己的容器),開銷增加最小。
·收集數據是一回事,但理解它則是另一回事。為了獲得正確的見解,需要對容器環境進行正確的可視化。一個擠滿了所有容器的所有資源指標的圖表的儀表盤,并不是很有洞察力。你通常希望從高層次的服務和集群的視圖開始,然后在出現問題時能夠進行深入的研究。
·同時,對問題本身的檢測也具有挑戰性。容器和服務的數量以及它們生成的度量指標的數量已經導致了數據的泛濫。將其與容器的動態方面相結合,你就可以明白為什么經典的報警技術常常會失敗。因此,在這樣的環境中,更多的自我學習分析技術,例如動態的基底和異常檢測,是非常有價值的,并且有助于對問題的主動檢測。
·***,在發現問題的同時,還應該對它們進行修復。為此,需要收集適當數量的上下文信息來進行故障排除。這包括在問題發生時發生的其他事件的相關性。是否所有的特定服務的容器都受到了影響,或者僅僅是一個?在哪里也有下游服務的問題?更詳細的日志數據或跟蹤信息可以幫助解決問題服務的故障。
結論
容器環境的完整堆棧監控與單片應用程序監控是不同的。典型的監控工具通常不能提供所有不同層次的正確見解,并且很難處理容器環境的規模和動態。無論您計劃使用開源解決方案還是商業產品,上面的不同考慮都可以幫助您選擇正確的工具,以確保您的環境完全可見。