













清華教授解密AIOps:智能運維如何落地?
隨著 AI 技術在各個應用領域的落地及實踐,IT 運維也將迎來一個智能化運維的新時代。算法的效率提升了 AIOps 的價值,通過持續學習,智能運維將把運維人員從紛繁復雜的告警和噪音中解放出來。
那么,基于算法的 IT 運維與自動化運維的區別是什么?在現階段,運維中的哪些痛點適合引入人工智能技術?如何加速落地?
8 月 26 日下午 51CTO 在北京舉辦了第十四期以“Tech Neo”為主題的技術沙龍活動,進一步拓寬運維/開發人員的運維思路、激發創新能力。由清華計算機系副教授,智能運維算法專家裴丹為大家分享主題為“智能運維如何落地”的精彩演講。
在演講開始,裴丹教授通過運維背景介紹,普世化智能運維關鍵技術,意在讓所有公司都能用上***的智能運維技術。裴丹教授認為,解決智能運維普世化的問題在數據、算法、算力、人才四方面。
第二部分是分解定義智能運維中的關鍵技術,通過分解關鍵技術來定義科研問題。
裴丹老師指出的科研問題要求分別為:
- 清晰輸入,數據可獲得。
- 清晰輸出,輸出目標切實可行。
- 有 high-level 的技術路線圖。
- 有參考文獻。
- 非智能運維領域的學術界能理解、能解決。
裴丹教授還指出,Gartner報告中關于智能運維的問題描述太寬泛。智能運維如何做好?裴丹教授認為,機器學習本身有很多成熟的算法和系統,及其大量的優秀的開源工具。
如果成功的將機器學習應用到運維之中,還需要以下三個方面的支持:
- 數據。互聯網應用本身具有海量的日志。需要做優化存儲。 數據不夠還需要自主生成。
- 標注的數據。日常運維工作會產生標注的數據。 比如出了一次事件后,運維工程師會記錄下過程, 這個過程會反饋到系統之中, 反過來提升運維水平。
- 應用。運維工程師是智能運維系統的用戶。 用戶使用過程發現的問題可以對智能系統的優化起正向反饋作用。
裴丹教授通過與百度運維、搜索部門的合作,分享了智能運維的三個案例,包括異常檢測、瓶頸分析以及智能熔斷。***個案例是基于機器學習的 KPI 自動化異常檢測。
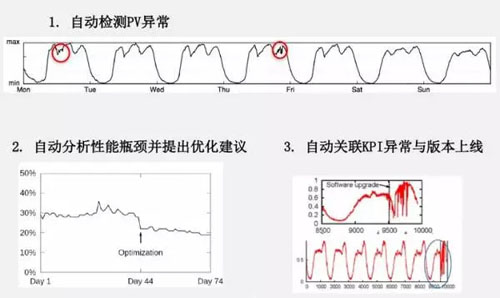
上圖表示運維人員判斷 KPI 曲線的異常并標注出來, 系統對標注的特征數據進行學習 。這是典型的監督式學習,需要高效的標注工具來節省運維人員的時間: 如可以拖拽,放大等方式。
***,裴丹教授在通過構建 KPI 異常檢測系統中分享了相關的實踐與挑戰等相關的解決方案。以下為演講實錄:
智能運維的發展歷程
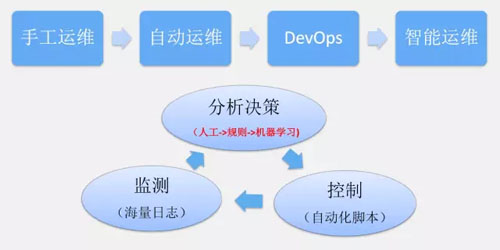
我們大家都知道,在運維發展的過程中,最早出現的是手工運維;在大量的自動化腳本產生后,就有了自動化的運維;后來又出現了 DevOps 和智能運維。
在運維的過程中,涉及到的步驟可以概括為:產生海量的監測日志,進行分析決策,并通過自動化的腳本進行控制。
運維的發展過程,主要是分析決策步驟發生了變化:起初,由人工決策分析;后來,在采集數據的基礎上,使用自動化的腳本進行決策分析;***,用機器學習方法做決策分析。

根據 Gartner Report,智能運維相關的技術產業處于上升期。2016 年,AIOps 的部署率低于 5%,Gartner 預計 2019 年 AIOps 的全球部署率可以達到 25%。所以,AIOps 的前景一片光明。
如果 AIOps 普遍部署之后會是什么樣的呢?現在做運維的同學們會變成怎樣?
從機器的角度,基礎性、重復性的運維工作都交給計算機來做了;同時,機器通過機器學習算法為復雜的問題提供決策的建議,然后向運維專家學習解決復雜問題的思路。
從運維專家的角度,運維專家主要處理運維過程中的難題,同時基于機器建議給出決策和訓練機器徒弟。
運維工程師將逐漸轉型為大數據工程師,主要負責開發數據采集程序以及自動化執行腳本,負責搭建大數據基礎架構,同時高效實現基于機器學習的算法。
機器學習科學家主要負責 AI 的落地應用,智能運維領域相對于其他 AI 應用領域的優勢在于,我們不僅有大量的應用數據,而且有實際的應用場景和部署環境。
因此,人工智能在計算機視覺、自然語言理解、語音識別之外,又多了一個落地應用——這是一座尚未開采的金礦。
智能運維科研門檻高-工業界
一般有“前景光明”、“前途光明”這些詞的時候,下面跟著的就是“道路曲折”。實際上,智能運維是一個門檻很高的工作。
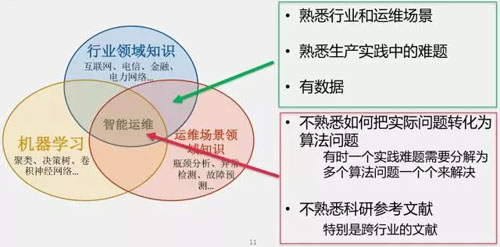
為什么呢?因為智能運維需要三方面的知識:
- 我們要熟悉應用的行業,比如互聯網、電信或者相對傳統的行業,如金融、電力等等。
- 我們要熟悉運維相關的場景,包括異常檢測、故障預測、瓶頸分析、容量預測等。
- 雖然工業界熟悉運維行業和場景,熟悉生產實踐中的挑戰,也有數據。但是,工業界并不熟悉整個智能運維中最重要的部分——如何把實際問題轉化為算法問題(后面會講到如何把實踐中的難題分解成多個算法并逐個解決)。
同時,工業界也不太熟悉查閱科研文獻,特別是跨行業的文獻。因此,智能運維是一個需要三方面領域知識結合的高門檻領域。
在智能運維文獻里有幾十種常見的基礎算法。但是,工業界并不熟悉這些算法。所以,我們利用微信公眾號介紹這些算法。
下面我將介紹一個例子——通過機器學習方法提升視頻流媒體的用戶體驗和觀看時長。
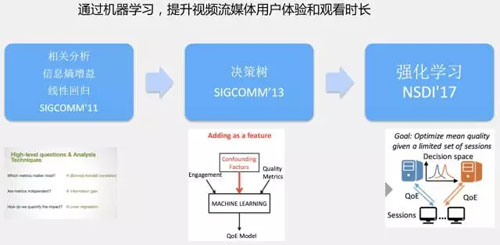
這是一位 CMU 教授的系列文章,這位教授在一個做視頻分發的創業公司做了若干工作。
2011 年,他在學術界發表了一篇文章,這一工作比較簡單,主要為了提升用戶觀看流媒體的體驗,其中用到了相關分析、線性回歸、信息增益等簡單算法。
2013 年,該教授基于網絡行為數據和性能數據,使用決策樹方法預測用戶的觀看時長。該教授于 2017 年發表了一篇新的文章,將視頻質量的實時優化問題轉化為一種基礎的強化學習問題,并使用上限置信區間算法有效解決了這一問題。
智能運維科研門檻高-學術界
在學術界中,很少有人做智能運維方向。這是因為,對于學術界來說,進入到智能運維這一科研領域具有很強的挑戰性。為什么呢?
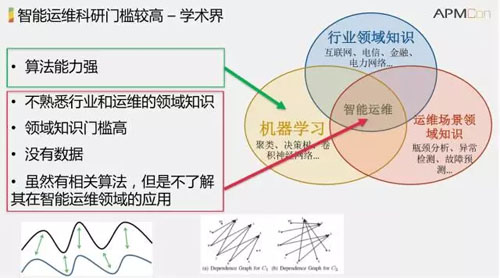
雖然學術界研究人員的算法能力相對較強,但是他們往往不熟悉行業和運維領域的相關知識。而智能運維處于三個領域的交叉部分。這就導致智能運維的門檻比較高,需要花大量的時間和精力才能進入智能運維領域。
前面講了如何降低工業界進入智能運維的門檻。同時,我也做了一些工作,以降低學術界進入智能運維領域的門檻。例如,我應邀在《中國計算機學會通訊》上發表文章,向學術界的同行介紹智能運維中的科研問題。
但是,僅僅宣傳是遠遠不夠的,我們還要實踐。去年,我在***屆 APMCon 會議上做了報告,講述了當時和百度合作的三個案例,包括異常檢測、瓶頸分析以及智能熔斷。
這種公開的宣傳給我自己帶來了很多新的合作。除了與百度的合作,我們清華實驗室相繼與滴滴、搜狗、阿里巴巴、騰訊簽署了正式的合作協議。
這驗證我的在去年我在 APMCon 上演講的觀點:工業界可以獲得算法層面的深度支持,學術界可以獲得現實世界的前沿問題和數據,有利于發表論文和申請國家項目。
工業界-學術界合作
1.0:一對一交流合作
但是,現在這種工業界跟學術界的合作方式,還處于1.0階段,即一對一的交流。

在這個過程中,我們遇到了諸多挑戰:
- 交流合作效率低,見效慢。比如說我是這個教授,我跟 A 公司討論一下,再跟 B 公司討論一下。很多情況下,不同公司遇到的問題都是類似的,比如異常檢測。但是,我需要跟每個公司梳理一遍這些問題。
C 公司可能不知道我,就找另外一位教授,他依然需要梳理這些問題。這就大大降低了交流合作的效率。我們知道,科研最難的部分,就是把一個實踐中的問題定義好。當定義好問題之后,只要數據準備好,其他問題都可以迎刃而解。
- 智能運維算法不幸成了特權。因為很少有教授愿意去做這種一對一交流,而愿意或有渠道和學校科研人員溝通交流的公司也不多。
這就導致,在國外,只有少數大公司和教授才能合作。比如,目前只有 Google、 Microsoft、Linkedin、Facebook、雅虎等大公司發表過智能運維有關的論文。
- 涉及知識產權,不符合開源大趨勢。因為一對一的合作需要簽署涉及知識產權的協議,不符合開源的大趨勢。
2.0:開源開放
一對一交流效率低,那具體應該怎么做呢?我們希望擁抱開源開放的文化,形成工業界與學術界合作的 2.0。
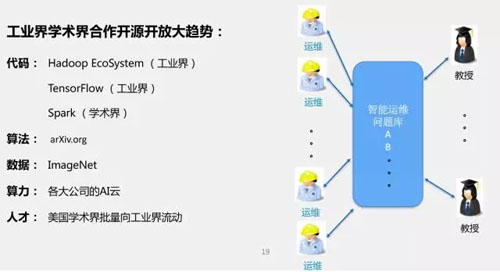
開源開放的大趨勢已經對工業界和學術界產生了巨大的影響。大家耳熟能詳的 Hadoop、Ecosystem、TensorFlow 等,都是開源開放的產物。
在算法層面,當前有 arXiv 共享算法(論文)平臺,和 Github 代碼共享;在數據層面,ImageNet 等數據共享平臺對機器學習算法的研究起到了巨大的推動作用;在計算能力層面,各大公司都建立了 AI 云;在人才層面,我們也可以看到,學術界和工業界的人才流動比原來順暢多了。
所以,我們的基本思路是,希望能夠建立智能運維的問題庫。具體的,我們嘗試把運維的常見問題梳理出來,并存儲到一個問題庫里。
這樣的話,對于缺乏智能運維背景知識的科研人員,在問題的輸入、輸出、數據集齊全的前提下,可以很容易地著手解決問題庫中的科研問題。對于做運維實踐的工業界的同學們,當遇到實際的問題時,可以查詢問題庫中的解決方案。
這一思路受到了斯坦福教授李飛飛的影響。她最近在宣傳普世化 AI 的思路——讓所有人都可以使用 AI。李飛飛教授建立的 ImageNet 上面有 1000 多萬張圖片的分類標注數據。
在 2012 年 Hinton 教授提出了一種基于 CNN 的圖片分類算法,取得比以往***結果高好幾個百分點的結果, 引起了深度學習的復興。
現在,她同時兼任 Google 機器學習部門的負責人。她在宣傳普世化 AI 思路時,提到普世化有四個基本點:計算能力、數據、算法、人才。
這四個基本點跟我們要落地智能運維所遇到的挑戰是一樣的。 因為我們也需要用到機器學習和 AI 的技術來解決智能運維中的挑戰性問題。
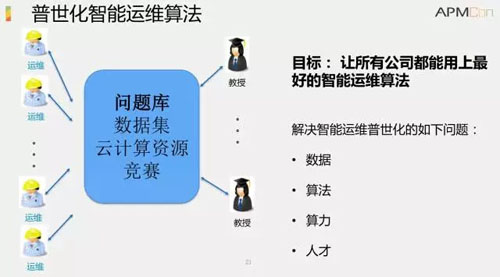
除了問題庫,學術界還需要數據集。此外,工業界***能提供云計算資源,讓學術界提供的算法在云端跑。數據公開后,學術界可以公布訓練好的算法,工業界就可以直接使用這些算法。
在人才方面,工業界可以與學術界合作。同時,那些參與我們的智能運維算法大賽且排名靠前的學生,也可以成為工業界的人才儲備。最終,我們希望所有的公司都能用上***的智能運維算法。
分解定義智能運維中的科研問題
下面分解定義一下智能運維中的科研問題,由于時間關系,我只能概述算法的特性。
為什么我們要定義科研問題呢?對于科研工作者來說,類似 Gartner Report 中列舉的智能運維問題太寬泛。
首先,科研問題需要清晰的輸入,并且數據是可以獲得的;其次,科研問題要有清晰的輸出,并且輸出的目標要切實可行;再次,科研問題要有高層面的技術路線圖,以及參考文獻;***,非智能運維領域的學術界要能理解該科研問題。

這是我們已經梳理出來的一些科研問題,我將用后面的時間來解釋一下這些算法。
這些算法分為三種:
- ***種算法是相對獨立的基礎模塊,面臨的挑戰較少,可以直接落地。
- 第二種算法依賴于其他的算法,我們需要把這些算法分解成一個個切實可行的解決問題。
- 第三種是把非常難的問題降低要求和難度,“退而求其次”。
基礎模塊
先講一下基礎模塊,基礎模塊是相對獨立并能夠落地的。
KPI 瓶頸分析算法

我介紹的***個基礎模塊算法是 KPI 瓶頸分析算法。在智能運維領域和 APM 領域,我們收集了很多的數據,數據的形式有 KPI 時間序列、日志等。
假如打開一個頁面的響應時間(首屏時間)是我們的 KPI,當首屏時間不理想、不滿意時,我們希望能夠找出哪些條件的組合導致了首屏時間不理想。這就是我們要解決的 KPI 瓶頸分析的定義。
該問題的輸入為一張又寬又長的表,其中包含 KPI 和影響到 KPI 的多維屬性。 輸出為可能影響 KPI 性能的屬性組合。這一科研問題具有廣泛的應用場景,包括首屏時間、應用加載時間、軟件報錯、視頻傳輸用戶體驗等。
在具體應用時,這一科研問題面臨著諸多挑戰:搜索的空間巨大;不同屬性之間可能存在關聯關系,導致用簡單的分析方法是不可行的。
KPI 瓶頸分析的常用基礎算法有:決策樹、聚類樹(CLTree)、層次聚類。
故障預測算法

我介紹的第二個基礎模塊算法,是我們最近跟百度系統部合作的一個案例——交換機故障預測。
在交換機故障之前,我們可以從交換機日志中提取一些預示故障的信號。如果找到這些信號,我們就可以提前兩小時預測出交換機故障。
故障預測的應用場景還包括硬盤故障預測、服務器故障預測等,使用到的算法包括隱式馬爾科夫模型、支持向量機,隨機森林等。
在具體應用時,故障預測面臨著一些挑戰。訓練故障預測模型的數據需要足夠多,但往往實踐中的故障案例比較少。雖然日志量很大,但日志中的有益信息相對較少。我們已經實現了切實可行的系統,且已經在百度運行。
庖丁解牛
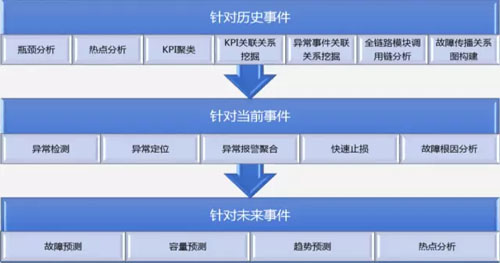
當我們應用層出現問題的時候,我們希望找到問題的原因。這里要解決的問題都描述過了,常用的根因分析算法有基于故障傳播鏈的、有基于概率圖模型的。這里我們對基于故障傳播鏈的的思路來庖丁解牛。
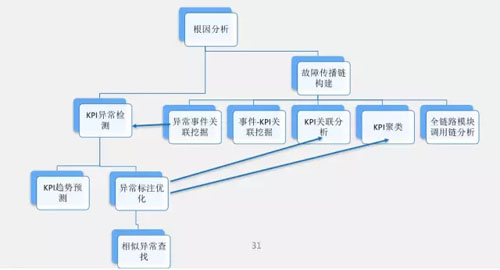
假如說我們有這樣的故障傳播鏈,同時又對事件有很好的監測和準確的報警,那根因的分析就簡單了。因為只需要順著故障傳播鏈各個報警找,找到***一個就是根因。
這其中有兩個關鍵的步驟,一個是 KPI 異常檢測,另一個是故障傳播鏈,下面會詳細介紹這兩部分。
異常檢測
首先是異常檢測,很多算法是基于 KPI 的趨勢預測的,還有一些算法是基于機器學習的,機器學習的算法需要有標注。而標注會給運維人員帶來很多開銷,所以能不能做一些工作減少標注的開銷呢?
這其中就包括相似異常的查找,運維人員標一個異常后,能不能自動地把相似的、相關的異常都找出來? 以上是對異常檢測問題的簡單分解,后面會更詳細的說明。
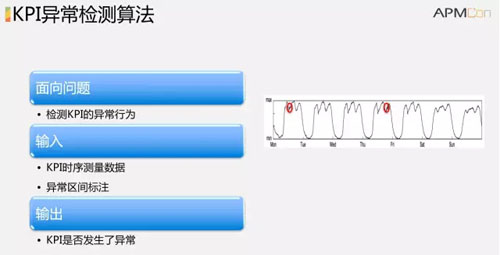
異常檢測的問題定義很簡單,就是對于這樣的隨著時間有周期性變化的KPI曲線,當它發生異常的時候能夠快速準確的報警。
它的常見算法有:基于窗口,基于預測,基于近似性,基于隱式馬爾可夫模型,也有機器學習,集成學習,遷移學習,深度學習,深度生成模型等等。
異常檢測所面對的挑戰就是 KPI 種類各異,如果基于趨勢預測算法,調整算法參數費時費力,同時需要人工標注,人工標注也可能不準確。
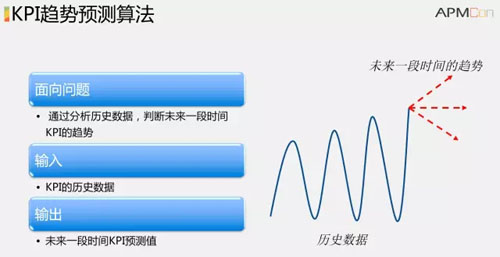
我們再分解一下,剛剛提到了異常檢測的一種思路是基于 KPI 趨勢預測。KPI 趨勢預測就是通過時序數據的算法能預測出來 KPI 將來一段時間是什么樣的,取什么值,常見的算法有 ARIMA、EWMA、Holt-Winters、時序數據分解、RNN等。
主要挑戰包括突發事件的影響、節假日的影響、數據不規則的影響,最重要的就是大家對異常的定義不一樣,會有主觀的因素,***導致這些算法很難調。
異常檢測的另外一個思路是基于機器學習來做, 但是這種方法通常都需要標注,而標注是需要消耗人力資源的。
并且如果標注不全或不準確,這個機器學習模型的效果就會打折扣。我們把減少異常標注的工作分解一下,在同一條曲線內找相似的異常,跨 KPI 找異常。
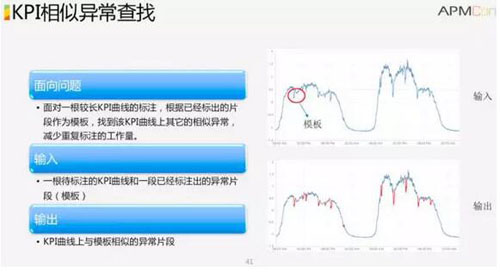
KPI 相似異常查找是在 KPI 內找異常,運維人員標注異常,然后算法以標注的異常為模塊,在曲線上找出類似的其他的異常,這樣就能減少標注開銷。
例如圖中的紅色部分即為標注,輸出為其他類似的異常。常用基本算法包括 DTW,MK ***配對等。
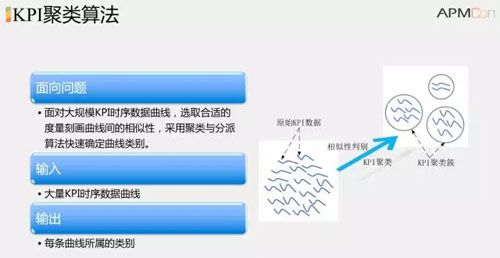
如果跨 KPI,可以先把一個模塊的各種 KPI 提前進行聚類,在同一個類別中的某條曲線上進行標注,那么其他的同類的曲線上的對應位置也為異常。聚類用到的基本算法包括 DBSCAN,K-medoids、CLARANS。
聚類是基于曲線的相似性,如果曲線不相似,但是其內在有關聯導致它們經常一起變化,這也能夠找出更多的異常,從而可以作為一個減少標注開銷的方法。
這個是“KPI 關聯分析”科研問題, 其基本算法包括關聯分析算法和 Granger 因果性分析算法等。
故障傳播鏈
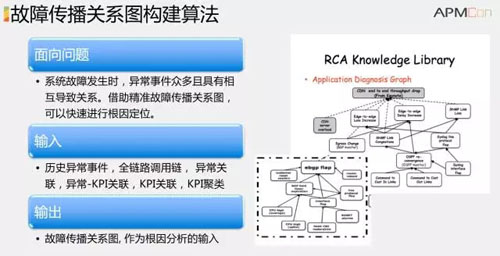
另一個關鍵因素是故障傳播鏈的構建,即 A 事件發生會導致 B 事件的發生。如果理清了事件的傳播關系,就可以構成故障傳播圖。
上文提到的 KPI 的關聯分析和 KPI 的聚類都可以用上。下面介紹異常事件的關聯關系和 KPI 的關聯關系挖掘。
上圖是故障傳播鏈,當應用層、業務層發生故障的時候,如果有故障傳播圖,就可以從中找到對應時間范圍內的相關事件。
如果有就沿著傳播鏈繼續往上找,直至找到根因。我們希望能得到這樣的故障傳播圖,但是很多軟件之間的模塊關系很復雜,很難描述。
另外,剛才提到的調用關系,即 A 模塊調 B 模塊,并不代表 A 發生異常就會導致 B 發生異常,而是還有很多其他的因素。 通過機器學習算法挖掘各種關聯關系,再輔以模塊調用關系鏈,則構建準確完整的調用關系鏈就相對比較容易了。
挖掘關聯關系包括之前闡述過的 KPI 聚類,KPI 關聯分析,下面我們再講述另外的兩個算法。

先看異常事件的關聯關系。兩個關聯事件是不是在歷史上經常一起發生,比如說這個時間窗口內發生了這四個不同的事件,如果說經常一起發生,它們就有兩兩對應關系。現有文獻中常見的算法有:FP-Growth、Apriori、隨機森林。

另外就是事件和 KPI 的關聯關系,比如程序啟動的事件,在某個時間點程序 A 啟動了,下個時間點程序 B 啟動了。在程序 A 每次啟動的時候 CPU 利用率就上了一個臺階,而 B 沒有。
所以說事件和曲線的關聯關系,還包括先后順序、變化方向。 常用基本算法包括 Pearson 關聯分析, J-Measure, Two-sample test 等。
退而求其次
前面我們分解了根因分析問題,但是有時由于數據采集不全等原因,完整的根因分析條件不具備,這就要求我們降低要求,“退而求其次”,解決簡單一些但是同樣有實際意義的問題。
智能熔斷

眾所周知,80% 的線上故障都是由產品上線或者變更導致的。也就是說在這種情況下,運維人員自己的操作、上線和變更就是業務出問題的根因,那么對于這種根因我們能不能做一些工作呢?
答案是肯定的,就是智能熔斷。當產品上線時,根據現有的數據判斷業務層出現的問題是否為該上線操作所導致的。具體實現的時候可以用 CUSUM,奇異譜變換(SST),DID 等算法。
異常報警聚合算法
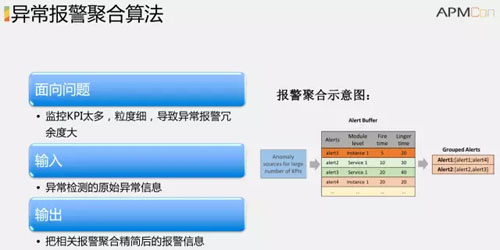
再換一個角度,現在有各種監控的報警,如果運維人員聚合不準,就無法決定下一步的操作。因為監控的 KPI 太多,導致異常報警冗余。
我們的算法會將各種報警原始數據聚合,比如將 100 個異常報警聚合成 5 個,這樣實際處理的時候就會相對容易些。具體的算法包括基于服務、機房、集群等拓撲的層次分析,還有基于挖掘的關系和基于故障傳播鏈的報警聚合。
故障定位算法
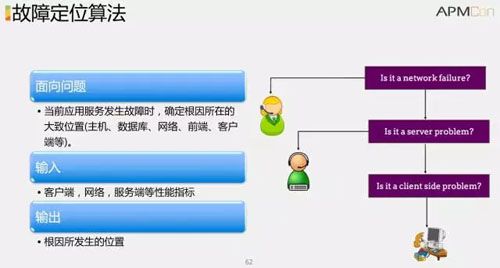
***舉一個退而求其次的方案。當業務發生故障時, 故障定位并不是給出完全的根因,而是能夠大致區分是哪里的問題,輸入是各種各樣的性能指標,輸出根因所發出的具體位置。
例如去年 SIGCOMM 2016 微軟提出的基于數據中心的故障定位,先用實驗床把所有可能故障都模擬一下,同時收集各類監控指標。
通過機器學習建立模型,這個模型可以根據實際發生的監控指標的癥狀, 推斷根因的大致位置,以便加速止損。 在相關文獻中用到的基礎算法包括隨機森林,故障指紋構建,邏輯回歸,馬爾科夫鏈,狄利克雷過程等方法來進行故障定位。
簡單小結一下, 智能運維關鍵技術落地可以有三種方式。相對獨立的算法可以直接落地,依賴其他算法的根因分析可以庖丁解牛,數據條件不成熟的可以退而求其次。
另外從前面列舉的那么多的算法例子,大家可以看到的確有很多的算法可以應用到智能運維里面的。
工業界的朋友們可以花一些時間和精力, 簡單了解一下這些算法,知道這些算法的輸入和輸出是什么,能解決運維中哪些實際問題,以及組合起來能解決什么問題,這樣會對智能運維更快落地起到事半功倍的效果。
總結與前瞻
智能運維本身前景非常光明,因為它具備豐富的數據和應用場景,將極大提高智能運維領域的生產力,也是 AI 領域尚未充分開采的金庫。
智能運維需要工業界和學術界的密切合作,但是目前仍只限于一對一相對低效的合作,少數公司和少數教授的特權不符合我們大的開源開放的趨勢。
我們的解決思路就是以科研問題為導向, 從日常工作中找到相關的問題,然后把這些問題分解定義成切實可行的科研問題, 并匯總成智能運維的科研問題庫。
同時, 工業界能夠提供一些脫敏數據作為評測數據集,這樣學術界就可以下載數據,并貢獻算法。
我的實驗室 NetMan 將會運營一個“智能運維算法競賽”的網站,匯總智能運維的科研問題庫,提供數據下載,并舉辦智能運維算法大賽。已經有包括美國 eBay 公司在內的多家公司同意為網站提供脫敏的運維數據。
在此非常感謝工業界的各位合作伙伴,也感謝我在清華的團隊,NetMan,可以把它認為是在智能運維算法里面的特種兵部隊。
***,與大家共勉:智能運維落地, 前景是光明的,道路肯定是曲折的。在智能運維的領域,我們從去年開始來推動智能運維算法在實踐中的落地,我已經行動了一年了,我們還有四年時間。
我相信只要我們有更多的學術界和工業界的朋友參與進來,再加上我們這樣的“智能運維算法競賽”網站的載體,我相信就像 ImageNet 曾經推動深度學習、人工智能的復興一樣,我們一定能推動智能運維算法在實踐中更好的落地! 謝謝大家。

51CTO Tech Neo 技術沙龍是 51CTO 在 2016 年開始定期組織的 IT 技術人員線下交流活動,目前僅限北京地區,周期為每月 1 次,每期關注一個話題,范圍涉及大數據、云計算、機器學習、物聯網等多個技術領域。

















