













MySQL數據表存儲引擎類型及特性
數據表類型(存儲引擎)
數據庫引擎用于存儲、處理和保護數據的核心服務,利用數據庫引擎可控制訪問權限并快速處理事務,利用數據庫引擎創建用于聯機事務處理或聯機分析處理數據的關系數據庫,包括創建用于存儲數據的表和用于查看、管理、保護數據安全的數據庫對象(索引、視圖、存儲過程)。
常見引擎比對
| 特性 | Myisam | InnoDB | Memory | BDB | Archive |
|---|---|---|---|---|---|
| 存儲限制 | ***制 | 64TB | 有 | 沒有 | 沒有 |
| 事務安全 | - | 支持 | - | 支持 | - |
| 鎖機制 | 表鎖 | 行鎖 | 表鎖 | 頁鎖 | 行鎖 |
| B樹索引 | 支持 | 支持 | 支持 | 支持 | - |
| 哈希索引 | - | 支持 | 支持 | - | - |
| 全文索引 | 支持 | - | - | - | - |
| 集群索引 | - | 支持 | - | - | - |
| 數據緩存 | - | 支持 | 支持 | - | - |
| 索引緩存 | 支持 | 支持 | 支持 | - | - |
| 數據壓縮 | 支持 | - | - | - | 支持 |
| 空間使用 | 低 | 高 | N/A | 低 | 非常低 |
| 內存使用 | 低 | 高 | 中 | 低 | 低 |
| 批量插入速度 | 高 | 低 | 高 | 高 | 非常高 |
| 外鍵支持 | - | 支持 | - | - | - |
各引擎特點
- Myisam
mysql默認存儲引擎,在磁盤上存儲成三個文件.frm(存儲表定義).MYD(MYData存儲數據)。MYI(MYIndex存儲索引);
沒有事務支持,不支持行鎖外鍵,因此當insert、update會鎖定整個表,效率會低一些,MyIASM中存儲了行數,如果表的讀操作遠大于寫且不需要事務,MyISAM優選。
索引
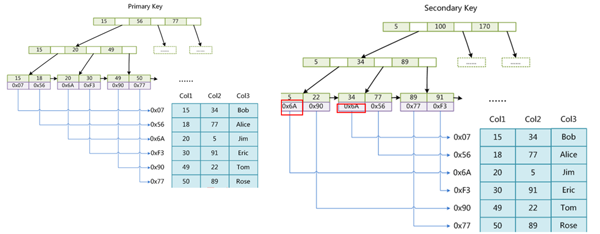
1.MyISAM引擎索引結構為B+Tree,其中B+Tree的數據域存儲的為實際數據地址即索引和實際數據分開即非聚集索引。
2.如圖主鍵索引和輔助索引結構一直只不過主鍵索引要求key唯一。
3.MyISAM中索引檢索算法首先安裝B+Tree搜索算法搜索索引,如果key存在,則取出data域的值,然后以data域的值為地址,讀取相應數據記錄。
- Innodb
提供了對數據庫ACID事務支持并實現SQL標準的四種隔離級別,提供行級鎖和外鍵約束。Mysql運行時Innodb會在內存中建立緩沖池用于緩沖數據和索引,該引擎不支持fulltext類型索引且沒有保存表的行數,select count(*) from table 血藥掃全表。
需要事務操作時Innodb***,鎖力度小,寫操作不會鎖定權標,所以并發高時Innodb引擎效率更高,
相比Myisam寫處理效率差一些會占用更多的磁盤空間保存數據和索引。
索引
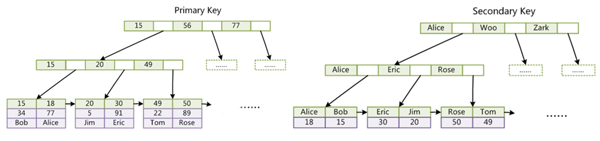
1.Innodb索引采用B+Tree且Innodb索引文件本身就是數據文件即B+Tree的數據域存儲的就是實際的數據如圖Primary Key即聚集索引。這個索引的key就是數據表主鍵,Innodb表本身就是主索引。
2.Innodb輔助索引數據域存儲的是相應的主鍵的值而不是地址,通過輔助索引查找時先找到主鍵再通過主鍵查找數據。所以主鍵不建議過長否則輔助索引會變得很大。
3.Innodb必須有主鍵如果沒有顯示指定Mysql會自動選擇一個唯一標識的數據記錄為主鍵。
4.聚集索引按主鍵搜索效率十分高效,輔助索引必須檢索兩遍。
5.基于Innodb索引結構可以解釋為什么不建議使用過長的主鍵,為什么不建議使用非單調(非遞增)的記錄做主鍵,B+Tree索引結構導致使用非單調做主鍵會相當低效。
常用命令
- show engines; 查看當前支持的引擎和默認引擎
- show table status from mytest; show create table tablename;查看數據表引擎
- 修改默認引擎 my.ini [mysqld]下增加 default-storage-engine=InnoDB
名詞概念
- ACID: (Atomicity)原子性,要么全部執行要么不執行;(Consistency)一致性,事務的運行不改變數據庫中數據的一致性;(Isolation)獨立性,也稱隔離性兩個以上的食物不會出現交錯執行的狀態;(Durability)持久性,事務執行成功后數據持久保存。
- BTree 二叉搜索樹
1.所有非葉子幾點最多有兩個子節點(left right)
2.所有節點存儲一個關鍵字
3.非葉子節點左指針指向小于其關鍵字的子樹,右指針指向大于其關鍵字的子樹
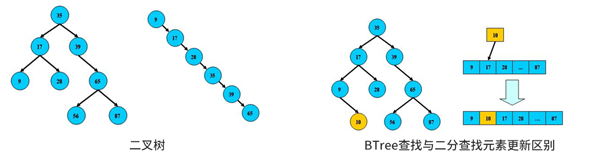
二叉樹查找:從跟節點開始查詢關鍵字與節點相等,***返回。否則查詢關鍵字比節點小,進入左子節點否則進入右節點。如果左或右為空反饋找不到。如果樹左右節點保持平衡如圖1、3棵樹查詢性能逼近二分查找。樹比二分查找的有點是數據更新時不需要移動大段內存數據如3、4圖數據更新。
經過一系列的更新可能導致圖2的BTree樹,該樹搜索成線性無查詢優勢,在實際使用中通常使用平衡二叉樹如圖1、3即“平衡二叉樹”,平衡算法是一種在B樹種插入和刪除節點的策略。
- B-Tree 多路搜索樹(非二叉樹)
1.任意非葉子節點最多只有M個子節點且M>2
2.跟節點的子節點數為[2, M]
3.除跟節點外的非葉子節點的子節點樹為[M/2, M]
4.每個節點存放至少M/2-1(取上整)和至多M-1個關鍵字(至少2個關鍵字)
5.非葉子節點的關鍵字個數=指向兒子的指針個數-1
6.非葉子節點的關鍵字:K[1],K[2],…,K[M-1]且K[i]<K[i+1]
7.非葉子幾點的指針:P[1],P[2],…,P[M],其中P[1]指向關鍵字小于K[1]的子樹,P[M]指向管關鍵字大于K[M-1]的子樹,其他P[i]指向關鍵字屬于(K[i-1], K[i])的子樹
8.所有葉子節點位于同一層
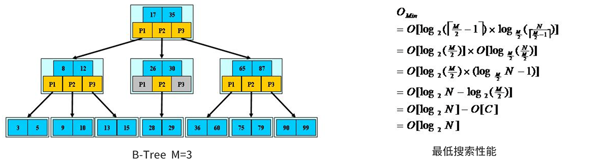
B-Tree查找:從跟節點開始,對節點內的關鍵字(有序)進行二分查找,***結束。否則進入查詢關鍵字所屬范圍的兒子節點;重復直到空或葉子節點。
由于限制除根節點外的非葉子節點至少含有M/2個兒子,確保了節點的至少利用率所以B-Tree的性能等價于二分查找,也就沒有B樹平衡的問題。由于M/2的限制,插入或刪除節點時需要考慮分裂和合并節點。
B-Tree特性:關鍵字集合分布在整科樹種;任何一個關鍵字出現且只出現在一個節點中;搜索有可能在非葉子節點結束;搜索性能等價于在關鍵字全集內做一次二分查找;自動層次控制;
- B+Tree B-Tree變體多路搜索樹
1.基本與B-Tree定義相同除以下外
2.非葉子節點的子樹指針與關鍵字個數相同
3.非葉子節點的子樹指針P[i]指向關鍵字值屬于(K[i], K[i+1])的子樹
4.為所有葉子節點增加一個鏈指針
5.所有關鍵字都在葉子節點出現
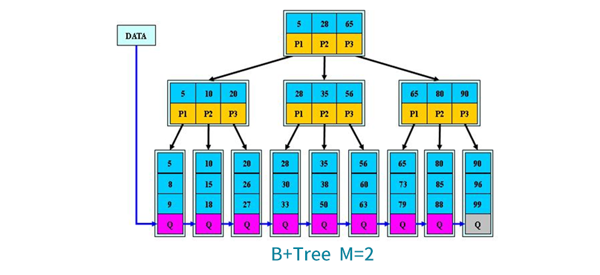
B+Tree查找:與B-Tree相同區別B+樹只有達到葉子節點才***,其性能等價于關鍵字全集做一次二分查找。
B+Tree特性:所有關鍵字都出現在葉子節點鏈表中,鏈表中關鍵字有序;不可能在非葉子節點***;非葉子節點相當于是葉子節點的索引,葉子節點相當于是存儲關鍵字數據的數據層;更適合文件索引系統;
- B*Tree B+Tree變體
1.在B+Tree的非跟和非葉子節點增加指向兄弟的指針
B+Tree分裂:當一個節點滿時,分配一個新的節點,將原節點中1/2的數據復制到新節點,***在父節點中增加新節點指針;B+樹分類只影響原節點和父節點不影響兄弟節點。
B*Tree分裂:一個節點滿時,如果下一個兄弟節點未滿,將一部分數據移到兄弟幾點中,再在源節點插入關鍵字,***修改父節點中兄弟節點的關鍵字;如果兄弟節點也滿了,則在源節點與兄弟節點之間增加新節點,并各賦值1/3的數據到新節點,***在父節點增加新節點的指針。B*Tree分配節點的概率比B+Tree要低,空間使用率高。
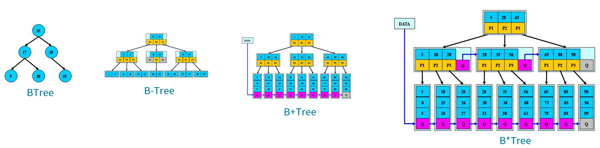
各個樹比對
-
各個樹比對
| 類型 | 特點 |
|---|---|
| BTree | 每個節點只存儲一個關鍵字,等于***,小于左節點,大于右節點 |
| B-Tree | 多路搜索樹,每個節點存儲M/2到M個關鍵字,非葉子節點存儲指向關鍵字范圍的子節點,所有關鍵字在整棵樹中出現,且只出現一次,非葉子節點可以*** |
| B+Tree | B-Tree基礎上尉葉子節點增加鏈表指針,所有關鍵字都在葉子節點出現,非葉子節點作為葉子節點的索引,B+Tree葉子節點才*** |
| B*Tree | B+Tree基礎上為非也自己點也增加鏈表指針,將節點的***利用率從1/2提高到2/3 |














