搜索那點事兒:Lucene 文件存儲和讀取技術詳解
Lucene是一個高性能、可伸縮的信息搜索(IR)庫。它可以為你的應用程序添加索引和搜索能力。Lucene是用Java實現的、成熟的開源項目,是著名的Apache Jakarta大家庭的一員,并且基于Apache軟件許可。
Lucene的檢索算法屬于索引檢索,即用空間來換取時間,對需要檢索的文件、字符流進行全文索引,在檢索的時候對索引進行快速的檢索,得到檢索位置,這個位置記錄檢索詞出現的文件路徑或者某個關鍵詞。Lucene的索引是用文件存儲,Lucene中的文件操作都是通過Directory來實現,下面來介紹一下Lucene有關文件存儲和讀取的有關技術。
1 數據存儲類Directory(org.apache.lucene.store.Directory)
一個Directory對象是一系列統一的文件列表(a flat list of files)。文件可以在它們被創建的時候一次寫入,一旦文件被創建,它再次打開后只能用于讀取(read)或者刪除(delete)操作,并且同時在讀取和寫入的時候允許隨機訪問(random access)。
在這里并不直接使用Java I/O API,但是更確切地說,所有I/O操作都是通過這個API處理的。這使得讀寫操作方式更統一,如基于內存的索引(RAM-based indices)的實現(即RAMDirectory)、通過JDBC存儲在數據庫中的索引、將一個索引存儲為一個文件的實現(即FSDirectory)。
Directory的鎖機制是一個LockFactory的實例實現的,可以通過調用Directory實例的setLockFactory()方法來更改。
如下圖是org.apache.lucene.store.Directory類以及它的一些子類的類圖:
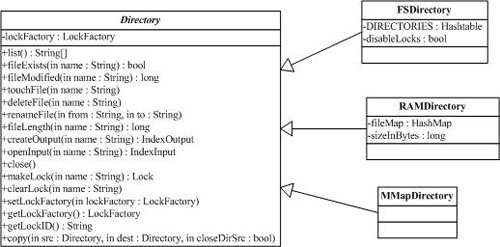
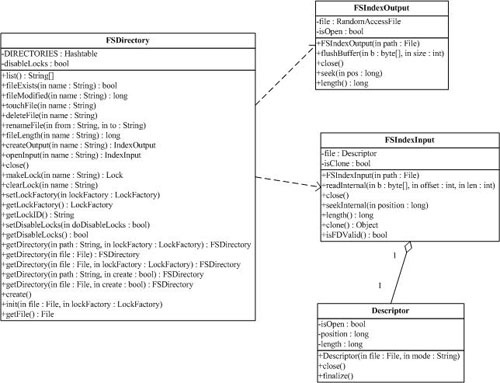
(1) org.apache.lucene.store.FSDirectory
FSDirectory類直接實現Directory抽象類為一個包含文件的目錄。目錄鎖的實現使用缺省的SimpleFSLockFactory,但是可以通過兩種方式修改,即給getLockFactory()傳入一個LockFactory實例,或者通過調用setLockFactory()方法明確制定LockFactory類。
目錄將被緩存(cache)起來,對一個指定的符合規定的路徑(canonical path)來說,同樣的FSDirectory實例通常通過getDirectory()方法返回。這使得同步機制(synchronization)能對目錄起作用。
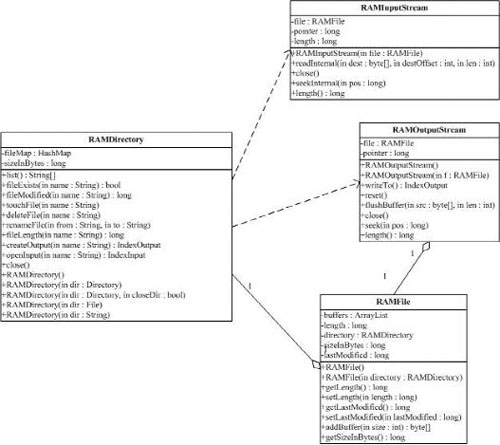
(2) org.apache.lucene.store.RAMDirectory
RAMDirectory類是一個駐留內存的(memory-resident)Directory抽象類的實現。目錄鎖的實現使用缺省的SingleInstanceLockFactory,但是可以通過setLockFactory()方法修改。
(3) org.apache.lucene.store.MMapDirectory
Lucene和Solr開始在64位的Windows和Solaris系統中默認使用MMapDirectory。簡單說MMapDirectory就是把Lucene的索引當作swap file來處理。mmap()系統調用讓OS把整個索引文件映射到虛擬地址空間,這樣Lucene就會覺得索引在內存中。然后Lucene就可以像訪問一個超大的byte[]數據(在Java中這個數據被封裝在ByteBuffer接口里)一樣訪問磁盤上的索引文件。
Lucene在訪問虛擬空間中的索引時,不需要任何的系統調用,CPU里的MMU和TLB會處理所有的映射工作。如果數據還在磁盤上,那么MMU會發起一個中斷,OS將會把數據加載進文件系統Cache。如果數據已經在cache里了,MMU/TLB會直接把數據映射到內存,這只需要訪問內存,速度很快。
程序員不需要關心paging in/out,所有的這些都交給OS。而且,這種情況下沒有并發的干擾,***的問題就是Java的ByteBuffer封裝后的byte[]稍微慢一些,但是Java里要想用mmap就只能用這個接口。還有一個很大的優點就是所有的內存issue都由OS來負責,這樣沒有GC的問題。因此在64位平臺上的Lucene,盡量使用MMapDirectory。
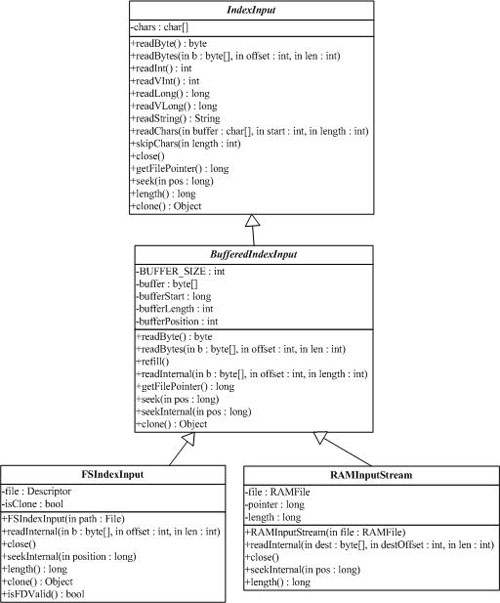
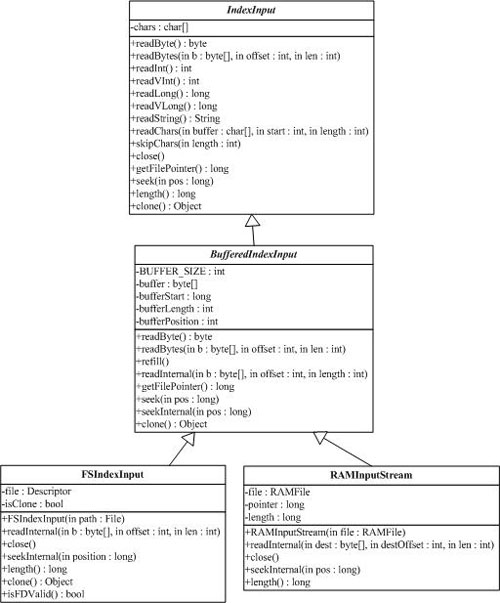
2 文件讀取類 IndexInput(org.apache.lucene.store.IndexInput)
IndexInput類是一個為了從一個目錄(Directory)中讀取文件的抽象基類,是一個隨機訪問(random-access)的輸入流(input stream),用于所有Lucene讀取Index的操作。BufferedIndexInput是一個實現了帶緩沖的IndexInput的基礎實現。
3 文件寫入類IndexOutput(org.apache.lucene.store.IndexOutput)
IndexOutput類是一個為了寫入文件到一個目錄(Directory)中的抽象基類,是一個隨機訪問(random-access)的輸出流(output stream),用于所有Lucene寫入Index的操作。BufferedIndexOutput是一個實現了帶緩沖的IndexOutput的基礎實現。RAMOuputStream是一個內存駐留(memory-resident)的IndexOutput的實現類。
作為一種檢索系統框架,Lucene并不直接提供系統的實現,而僅僅是系統框架而已。因此,為了構建一個真正可用的全文檢索系統,開發人員必須熟悉Lucene的基本框架以及API,這樣才能進行高效的開發。
這一需求要求了Lucene具備一種簡明、方便的構架與函數接口來方便用戶(即開發人員)的使用。這體現了Lucene需要很高的易用性(usability)。 不僅如此,開源是Lucene的一個重大屬性。相比Google的pagerank搜索方案,Lucene必須不斷改進其算法以及各種輔助措施來使得其運行更加高效,并支持多種語言等。因此,Lucene必須具備很好的可修改性(modifiability)。
【本文為51CTO專欄作者“達觀數據”的原創稿件,轉載可通過51CTO專欄獲取聯系】