如何使用AWR報告來診斷數據庫性能問題
對于數據庫整體的性能問題,AWR的報告是一個非常有用的診斷工具。
一般來說,當檢測到性能問題時,我們會收集覆蓋了發生問題的時間段的AWR報告-但是***只收集覆蓋1個小時時間段的AWR報告-如果時間過長,那么AWR報告就不能很好的反映出問題所在。
還應該收集一份沒有性能問題的時間段的AWR報告,作為一個參照物來對比有問題的時間段的AWR報告。這兩個AWR報告的時間段應該是一致的,比如都是半個小時的,或者都是一個小時的。
Interpretation
在處理性能問題時,我們最關注的是數據庫正在等待什么。
當進程因為某些原因不能進行操作時,它需要等待。花費時間最多的等待事件是我們最需要關注的,因為降低它,我們能夠獲得***的好處。
AWR報告中的"Top 5 Timed Events"部分就提供了這樣的信息,可以讓我們只關注主要的問題。
Top 5 Timed Events
正如前面提到的,"Top 5 Timed Events"是AWR報告中最重要的部分。它指出了數據庫的sessions花費時間最多的等待事件,如下:
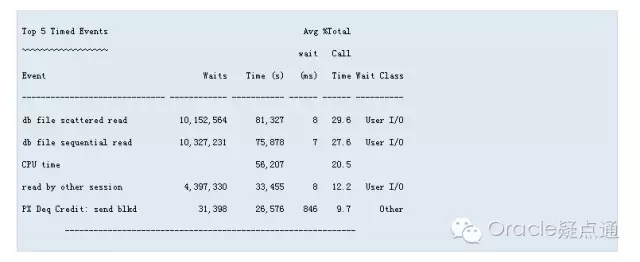
Top 5 Events部分包含了一些跟Events(事件)相關的信息。它記錄了這期間遇到的等待的總次數,等待所花費的總時間,每次等待的平均時間;這一部分是按照每個Event占總體call time的百分比來進行排序的。
根據Top 5 Events部分的信息的不同,接下來我們需要檢查AWR報告的其他部分,來驗證發現的問題或者做定量分析。等待事件需要根據報告期的持續時間和當時數據 庫中的并發用戶數進行評估。如:10分鐘內1000萬次的等待事件比10個小時內的1000萬等待更有問題;10個用戶引起的1000萬次的等待事件比 10,000個用戶引起的相同的等待要更有問題。
就像上面的例子,將近60%的時間是在等待IO相關的事件。
- 事件"db file scattered read"一般表明正在做由全表掃描或者index fast full scan引起的多塊讀。
- 事件"db file sequential read"一般是由不能做多塊讀的操作引起的單塊讀(如讀索引)
其他20%的時間是花在使用或等待CPU time上。過高的CPU使用經常是性能不佳的SQL引起的(或者這些SQL有可能用更少的資源完成同樣的操作);對于這樣的SQL,過多的IO操作也是一個癥狀。關于CPU使用方面,我們會在之后討論。
在以上基礎上,我們將調查是否這個等待事件是有問題的。若有問題,解決它;若是正常的,檢查下個等待事件。
過多的IO相關的等待一般會有兩個主要的原因:
- 數據庫做了太多的讀操作
- 每次的IO讀操作都很慢
Top 5 Events部分的顯示的信息會幫助我們檢查:
- 是否數據庫做了大量的讀操作:
上面的圖顯示了在這段時間里兩類讀操作都分別大于1000萬,這些操作是否過多取決于報告的時間是1小時或1分鐘。我們可以檢查AWR報告的elapsed time
如果這些讀操作確實是太多了,接下來我們需要檢查AWR報告中 SQL Statistics 部分的信息,因為讀操作都是由SQL語句發起的。
- 是否是每次的IO讀操作都很慢:
上面的圖顯示了在這段時間里兩類讀操作平均的等待時間是小于8ms的
至于8ms是快還是慢取決于底層的硬件設備;一般來講小于20ms的都可以認為是可以接受的。
我們還可以在AWR報告"Tablespace IO Stats"部分得到更詳細的信息
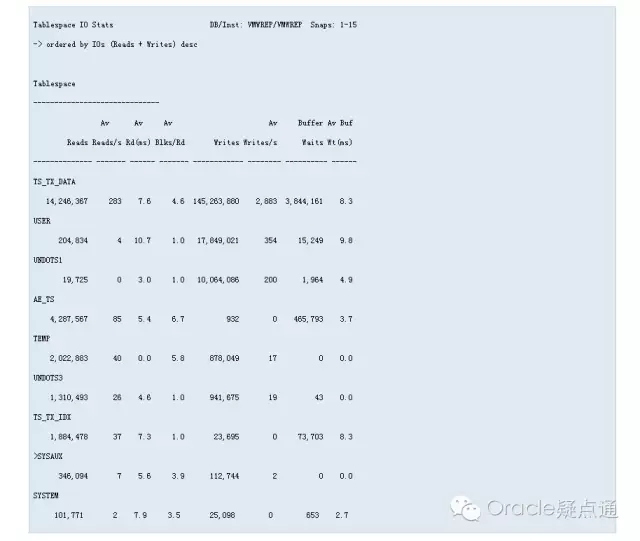
如上圖,我們關心Av Rd(ms)的指標。如果它高于20ms并且同時有很多讀操作的,我們可能要開始從OS的角度調查是否有潛在的IO問題。

- 雖 然高"db file scattered read"和"db file sequential read"等待可以是I / O相關的問題,但是很多時候這些等待也可能是正常的;實際上,對一個已經性能很好的數據庫系統,這些等待事件往往在top 5等待事件里,因為這意味著您的數據庫沒有那些真正的“問題”。
訣竅是能夠評估引起這些等待的語句是否使用了***的訪問路徑。如果"db file scattered read"比較高,那么相關的SQL語句可能使用了全表掃描而沒有使用索引(也許是沒有創建索引,也許是沒有合適的索引);相應的,如果"db file sequential read"過多,則表明也許是這些SQL語句使用了selectivity不高的索引從而導致訪問了過多不必要的索引塊或者使用了錯誤的索引。這些等待可 能說明SQL語句的執行計劃不是***的。
接下來就需要通過AWR來檢查這些top SQL是否可以進一步的調優,我們可以查看AWR報告中 SQL Statistics 的部分.
上面的例子顯示了20%的時間花在了等待或者使用CPU上,我們也需要檢查 SQL statistics 部分來進一步的分析。
需要注意,接下來的分析步驟取決于我們在TOP 5部分的發現。在上面的例子里,3個top wait event表明問題可能與SQL語句執行計劃不好有關,所以接下來我們要去分析"SQL Statistics"部分。
同樣的,因為我們并沒有看到latch相關的等待,latch在我們這個例子里并沒有引發嚴重的性能問題;那么我們接下來就完全不需要分析latch相關的信息。
一般來講,如果數據庫性能很慢,TOP 5等待事件里"CPU", "db file sequential read" 和"db file scattered read" 比較明顯(不管它們之間的順序如何),我們總是需要檢查Top SQL (by logical and physical reads)部分;調用SQL Tuning Advisor或者手工調優這些SQL來確保它們是有效率的運行。
SQL Statistics
AWR包含了一些不同的SQL統計值:

根據Top 5 部分的Top Wait Event不同,我們需要檢查不同的SQL statistic。
在我們這個例子里,Top Wait Event是"db file scattered read","db file sequential read"和CPU;我們最需要關心的是SQL ordered by CPU Time, Gets and Reads。
我們會從"SQL ordered by gets"入手,因為引起高buffer gets的SQL語句一般是需要調優的對象。

對這些Top SQL,可以手工調優,也可以調用SQL Tuning Advisor。
分析:
- -> Total Buffer Gets: 4,745,943,815
假設這是一個一個小時的AWR報告,4,745,943,815是一個很大的值;所以需要進一步分析這個SQL是否使用了***的執行計劃
- Individual Buffer Gets
上面的例子里單個的SQL的buffer get非常多,最少的那個都是8億5千萬。這三個SQL指向了兩個不同的引起過多buffers的原因:
注意:對于某些非常繁忙的系統來講,以上的數字可能都是正常的。這時候我們需要把這些數字跟正常時段的數字作對比,如果沒有什么太大差別,那么這些SQL并不是引起問題的元兇(雖然通過調優這些SQL我們仍然可以受益)
# 單次執行buffer gets過多
SQL_ID為'5t1y1nvmwp2'和'4at7cbx8hnz'的SQL語句總共被執行了168次,但是每次執行引起的buffer gets超過500萬。這兩個SQL應該是主要的需要調優的候選者。
# 執行次數過多
SQL_ID 'grr4mg7ms81' 每次執行只是引起16次buffer gets,減少這條SQL每次執行的buffer get可能并不能顯著減少總共的buffer gets。這條語句的問題是它執行的太頻繁了,6500萬次。
改變這條SQL的執行次數可能會更有意義。這個SQL看起來是在一個循環里面被調用,如果可以讓它一次處理的數據更多也許可以減少它執行的次數。