踩過無數坑,觸過N次雷:程序世界中必須處處設防!
人與人之間最重要的是信任,但程序的世界里,可能信任越少越好;我越發覺得越是高性能高可用的系統里,不信任原則會體現得更加淋漓盡致。

為了少走彎路,寫下這篇文章留給自己參考,其中一些是自己踩過的一些坑;一些是接手他人系統時觸過的雷;還有一些是從別人分享的經驗學習得來;能力有限,先記下自己的一些體會,錯誤的地方再慢慢改正。
編程的世界里十面埋伏
編程,是一件容易的事,也是一件不容易的事。說它容易,是因為掌握一些基本的數據類型和條件語句,就可以實現復雜的邏輯;說它不容易,是因為高性能高可用的代碼,需要了解的知識有很多很多。
編程的世界,也跟掃雷游戲的世界一樣,充滿雷區,十面埋伏,一不小心,隨時都可能踩雷,隨時都可能 Game Over。
而玩過掃雷的人都知道,避免踩雷的最好方法,就是提前識別雷區并做標記(設防)避免踩踏。
鑒于此,編程的世界里,從輸入到輸出同樣需要處處設防,步步為營。
01對輸入的不信任
對空指針的檢查
不只是輸入,只要是使用到指針的地方,都應該先判斷指針是否為 NULL,而內存釋放后,應當將指針設置為 NULL。
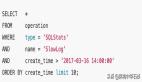
【真實案例】:注冊系統某段邏輯,正常使用情況下,都有對指針做檢查,在某個錯誤分支,打印日志時,沒檢查就使用了該字符串;結果可正常運行,但當訪問某個依賴模塊超時走到該分支,觸發 Bug,導致 coredump。
對數據長度的檢查
使用字符串或某段 buf,特別是 memcpy / strcpy 時,需要盡量對數據長度做下檢查和截斷。
【真實案例】:接手 oauth 系統后運行數月表現良好,突然有一天,發生了 coredump,經查,是某個業務不按規定,請求包中填寫了超長長度,導致 memcpy 時發生段錯誤,根本原因還是沒有做好長度檢查。
對數據內容的檢查
某些場景下,沒有對數據內容做檢查就直接使用,可能導致意想不到的結果。
【真實案例】:SQL 注入和 XSS 攻擊都是利用了服務端沒有對數據內容做檢查的漏洞。
02對輸出(變更)的不信任
變更的影響一般體現在輸出,有時候輸出的結果并不能簡單的判斷是否正常,如輸出是加密信息,或者輸出的內容過于復雜。
所以,對于每次變更:
修改代碼時,采用不信任編碼,正確的不一定是“對”的,再小的修改也應確認其對后續邏輯的影響,有些修正可能改變原來錯誤時的輸出,而輸出的改變,就會影響到依賴該改變字段的業務。
發布前,應該對涉及到的場景進行測試和驗證,測試可以有效的發現潛在的問題,這是眾所周知的。
發布過程,應該采用灰度發布策略,因為測試并非總是能發現問題,灰度發布,可以減少事故影響的范圍。常見灰度發布的策略有機器灰度、IP灰度、用戶灰度、按比例灰度等,各有優缺點,需要根據具體場景選擇,甚至可以同時采用多種的組合。
發布后,全面監控是有效發現問題的一種方法。因為測試環境和正式環境可能存在不一致的地方,也可能測試不夠完整,導致上線后有問題。
所以需采取措施進行補救:
- 如使用 Monitor 監控請求量、成功量、失敗量、關鍵節點等。
- 使用 DLP 告警監控成功率。
- 發布完,在正式環境測試一遍。
【真實案例】:oauth 系統某次修改后編譯時,發現有個修改不相關的局部變量未初始化的告警,出于習慣對變量進行了初始化(初始化值和編譯器默認賦值不一樣),而包頭某個字段采用了該未初始化的變量,但在測試用例中未能體現,監控也沒細化到每個字段的值,導致測試正常,監控正常;但前端業務齊齊互動使用了該包頭字段,導致發布后影響該業務。
服務程序的世界里防不勝防
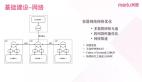
一般的系統,都會有上下游的存在,如下圖所示:
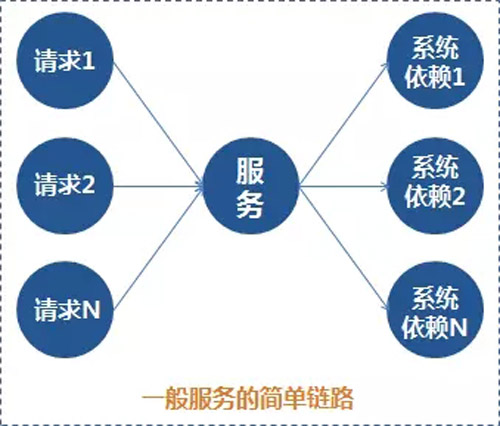
而上下游的整個鏈路中,每個點都是不能保證絕對可靠的,任何一個點都可能隨時發生故障,讓你措手不及。因此,不能信任整個鏈路中的任何一個點,需進行設防。
01對服務本身的不信任
主要措施如下:
- 服務監控。前面所述的請求量、成功量、失敗量、關鍵節點、成功率的監控,都是對服務環節的單點監控。在此基礎上,可以加上自動化測試,自動化測試可以模擬應用場景,實現對流程的監控。
- 進程秒起。人可能在程序世界里是不可靠的因素(大牛除外),前面的措施,多是依賴人來保證的;所以,coredump 還是有可能發生的,這時,進程秒起的實現,就可以有效減少 coredump 的影響,繼續對外提供服務。
02對依賴系統的不信任
可采用柔性可用策略,根據模塊的不可或缺性,區分關鍵路徑和非關鍵路徑,并采取不同的策略:
對于非關鍵路徑,采用柔性放過策略。當訪問非關鍵路徑超時時,簡單的可采取有限制(一定數量、一定比重)的重試,結果超時則跳過該邏輯,進行下一步;復雜一點的統計一下超時的比例,當比例過高時,則跳過該邏輯,進行下一步。
對于關鍵路徑,提供弱化服務的柔性策略。關鍵路徑是不可或缺的服務,不能跳過;某些場景,可以根據目的,在關鍵路徑嚴重不可用時,提供弱化版的服務。
舉例如派票系統訪問票據存儲信息嚴重不可用時,可提供不依賴于存儲的純算法票據,為彌補安全性的缺失,可采取縮短票據有效期等措施。
03對請求的不信任
對請求來源的不信任,有利可圖的地方,就會有黑產時刻盯著,偽造各種請求,對此,可采取如下措施:
- 權限控制。如 IP 鑒權、模塊鑒權、白名單、用戶登錄態校驗等。
- 安全審計。權限控制僅能打擊一下非正常流程的請求,但壞人經常能夠成功模擬用戶正常使用的場景;所以,對于一些重要場景,需要加入安全策略,打擊如 IP、號碼等信息聚集,頻率過快等機器行為,請求重放、劫持等。
對請求量的不信任,前端的請求,不總是平穩的;有活動時,會暴漲;前端業務故障恢復后,也可能暴漲;前端遭到惡意攻擊時,也可能暴漲;一旦請求量超過系統負載,將會發生雪崩,最終導致整個服務不可用。
對此種種突發情況,后端服務需要有應對措施:
- 頻率限制,控制各個業務的最大請求量(業務根據正常請求峰值的2-3倍申請,該值可修改),避免因一個業務暴漲影響所有業務的情況發生。
- 過載保護,雖然有頻率限制,但業務過多時,依然有可能某個時間點,所有的請求超過了系統負載,或者到某個 IDC,某臺機器的請求超過負載。
為避免這種情況下發生雪崩,將超過一定時間的請求丟棄,僅處理部分有效的請求,使得系統對外表現為部分可用,而非完全不可用。
運營的世界里不可預測
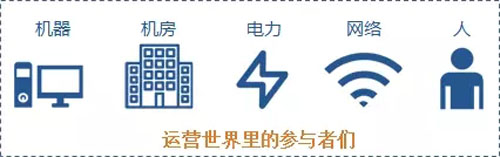
01對機器的不信任
機器故障時有發生,如果服務存在單點問題,故障時,則服務將完全不可用,而依賴人工的恢復是不可預期的。對此,可通過以下措施解決:
容災部署。即至少有兩臺以上的機器可以隨時對外提供服務。
心跳探測。用于監控機器是否可用,當機器不可用時,若涉及到主備機器的,應做好主備機器的自動切換;若不涉及到主備的,禁用故障機器對外提供服務即可。
02對機房的不信任
現實生活中,整個機房不可用也是有發生過的,如 2015 年的天津濱海新區爆炸事故,導致騰訊在天津的多個機房不能對外提供正常服務,對此采取的措施有:
- 異地部署。不同 IDC、不同城市、不同國家等部署,可以避免整個機房不可用時,有其他機房的機器可以對外提供服務。
- 容量冗余。對于類似 QQ 登陸這種入口型的系統,必須保持兩倍以上的冗余;如此,可以保證當有一個機房故障時,所有請求遷移到其他機房,不會引發系統過載。
03對電力的不信任
雖然我們越來越離不開電力,但電力卻不能保證一直為我們提供服務。斷電時,其影響和機器故障、機房故障類似,機器會關機,數據會丟失。所以,需要對數據進行備份:
- 磁盤備份。來電后,機器重啟,可以從磁盤中恢復數據,但可能會有部分數據丟失。
- 遠程備份。機器磁盤壞了,磁盤的數據會丟失。對于重要系統,相關數據應當考慮采用遠程備份。
04對網絡的不信任
不同地方,網絡時延不一樣,一般來說,本地就近的機器,時延要好于異地的機器,所以,比較簡單的做法就是近尋址,如 CMLB。
也有部分情況,是異地服務的時延要好于本地服務的時延,所以,如果要做到較好的最優路徑尋址,就需要先做網絡探測,如 Q 調。
常有網絡有波動或不可用情況出現,和機器故障一樣處理,應當做到自動禁用;但網絡故障和機器故障又不一樣,經常存在某臺機器不可用。
但別的機器可以訪問的情況,這時就不能在服務端禁用機器了,而應當采用本地回包統計策略,自動禁用服務差的機器;同時需配合定時探測禁用機器策略,自動恢復可正常提供服務的機器。
05對人的不信任
人的因素在運營的世界里也是不穩定的因素(大牛除外)。所以,不能對人的操作有過多的信任:
操作備份。每一步操作都有記錄,便于發生問題時的回溯,重要的操作需要 review,避免個人考慮不周導致事故。
效果確認。實際環境往往和測試環境會存在一些差異,所有在正式環境做變更后,應通過視圖 review 和驗證來確認是否符合預期。
變更可回滾。操作前需對舊程序、舊配置等做好備份,以便發生故障時,及時恢復服務。
自動化部署。機器的部署,可能有一堆復雜的流程,如各種權限申請,各種客戶端安裝等,僅靠文檔流程操作加上測試驗證是不夠的。
可能某次部署漏了某個步驟而測試又沒測到,上線后就可能發生事故,若能所有流程實現自動化,則可有效避免這類問題。
一致性檢查。現網的發布可能因某個節點沒同步導致漏發,也就是不同的機器服務不一樣;對此,有版本號的,可通過版本號監控發現;沒版本號的,則需借助進程、配置等的一致性檢查來發現問題。
備注:以上提到的不信任策略,有的不能簡單的單條使用,需要結合其他的措施一起使用。
小結
最重要的還是那句話,程序的世界里,應該堅持不信任原則,處處設防。