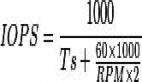分布式日志存儲系統-LogDevice
寫在前面
做過分布式系統的人都知道,想要在大規模集群下處理高并發事務時同時滿足CAP(一致性、可用性、分區容錯),從理論上來說不可能,當然聽說最近谷歌已經實現了這樣的分布式系統,但是總的來說確實非常難。對于社交媒體的海量日志文件,如果我們也提出了需要確保高可用、持續寫入數據、按照記錄順序返回數據等三條要求,你覺得是否可以實現?FaceBook的LogDevice實現了。
什么是日志
日志是記錄一系列序列化的系統行為的信息,我們需要確保它們能夠被保存在可靠的地方。對于應用程序來說,日志的作用一般有兩個,即Troubleshooting和顯示程序運行狀態。好的日志記錄方式可以提供我們足夠多定位問題的依據。對于一些復雜系統,例如數據庫,日志可以承擔數據備份、同步作用,很多分布式數據庫都采用“write-ahead”方案,在節點數據同步時通過日志文件恢復數據。
日志一般具有三個特性:
1、面向記錄:寫入日志的一定是孤立的行,而不是一個字節。日志實質上是問題的最小單元,用戶也一定是讀取整行日志。日志的存儲原則上按照順序,即按照LSN(日志順序數字)存放,但是也不完全這么要求,所以日志系統可以優先高寫入需求,對寫入失敗容錯。
2、日志天生就是遞增的:也就是說,日志是不會修改的,那么也就意味著,日志系統的設計應該是以高寫入、高讀取為目標,不需要擔心更新操作的數據一致性問題。
3、日志存儲周期長:可能是一天,也可能是一個月,甚至于一年。這也就意味著,日志的刪除規則一般都是按照時間或者空間進行設定的,具有固定的規則。
來個假如
假如我們要設計一個分布式日志存儲系統,你會怎么設計?
日志信息需要傳輸、存儲,為了實現穩定的數據交換,我們可以采用Kafka作為消息中間件。
Kafka實際上是一個消息發布訂閱系統。
Producer向某個Topic發布消息,而Consumer訂閱某個Topic的消息,進而一旦有新的關于某個Topic的消息,Broker會傳遞給訂閱它的所有Consumer。在Kafka中,消息是按Topic組織的,而每個Topic又會分為多個Partition,這樣便于管理數據和進行負載均衡。同時,它也使用了Zookeeper進行負載均衡。
Kafka在磁盤上的存取代價為O(1),即便是普通服務器,每秒也能處理幾十萬條消息,并且它本身就是分布式架構,也支持將數據并行加載到Hadoop。
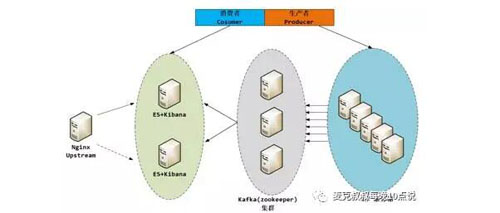
上面這張圖是一個典型的采用消息中間件進行日志數據交換的系統設計架構,但是沒有實現數據存儲,也沒有描述數據是如何被抽取并發送到Kafka的。
如果想要實現數據存儲,并描述清楚內部處理流程,我們可以采用怎么樣的日志處理系統架構呢?這里推薦你FaceBook的Scribe,它是一款開源的日志收集系統,在Facebook內部已經得到大量的應用。它能夠從各種日志源上收集日志,存儲到一個中央存儲系統 (可以是NFS,分布式文件系統等)上,以便于進行集中統計分析處理。
Scribe最重要的特點是容錯性好。當后端的存儲系統奔潰時,Scribe會將數據寫到本地磁盤上,當存儲系統恢復正常后,Scribe將日志重新加載到存儲系統中。
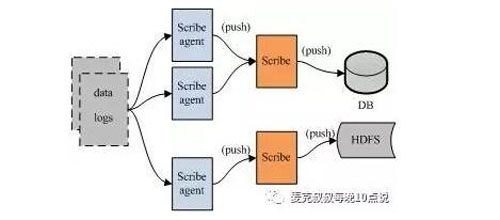
Scribe的架構比較簡單,主要包括三部分,分別為Scribe Agent, Scribe和存儲系統。Scribe Agent實際上是一個Thrift Client。Scribe接收到Thrift Client發送過來的數據,根據配置文件,將不同topic的數據發送給不同的對象。存儲系統實際上就是Scribe中的Store,當前Scribe支持非常多的Store。
貌似市面上已經有很多分布式日志收集系統了,為什么FaceBook還需要推出LogDevice呢?而且FaceBook自己已經有了Scribe,為什么還要繼續設計LogDevice?因為Scribe更多實現了日志數據的收集,它不是一個完整的日志處理、存儲、讀取服務,系統設計也較為死板,存儲更多依賴HDFS,使用過程中一定出現了不能滿足自身需求的情況。而對于開源的哪些分布式日志收集系統,更多的是集成各個開源組件,共同完成日志存儲系統設計需求。對于FaceBook的工程師來說,他們一貫秉承著用于創新的精神,想想Apache Cassandra,其實當時已經有HBase等成熟的NoSQL數據庫,但是由于存在中心節點等諸多設計上的限制,FaceBook自己搞了一個全新的無中心化設計的架構,即便在初期飽受質疑,后續也在不斷地改進,到目前為止,Cassandra真正進入到了它的黃金時代。