58同城高可用Docker容器云平臺的技術演進之路
58 私有云平臺是 58 同城架構線基于容器技術為內部服務開發的一套業務實例管理平臺。
它支持業務實例按需擴展,秒級伸縮,平臺提供友好的用戶交互過程,規范化的測試、上線流程,旨在將開發、測試人員從基礎環境的配置與管理中解放出來,使其更聚焦于自己的業務。
本文和大家分享在私有云平臺實施過程中的相關容器技術實踐,主要從以下三個部分來進行討論:
- 背景:當前存在哪些問題,為什么使用容器技術。
- 整體架構:整個容器技術的架構方案。
- 核心模塊的設計方案:一些核心模塊的選型決策與解決方案。
為什么使用容器技術
在沒有用容器化技術之前,我們存在這些問題:
01資源利用率問題
不同業務場景對資源的需求是不一樣的,有 CPU 密集型、內存密集型、網絡密集型,這就可能導致資源利用率不合理的問題。比如,一個機器上部署的服務都是網絡密集型,那么 CPU 資源和內存資源就都浪費了。
有些業務可能只聚焦于服務本身而忽略機器資源利用率的問題。
02混合部署交叉影響
對于線上服務,一臺機器要混合部署多個服務,那么服務之間可能存在相互影響的情況。
比如,一個服務由于某些原因突然網絡流量暴漲,可能把整個機器的帶寬都打滿,那么其他服務就會受到影響。
03擴/縮容效率低
當業務節點需要進行擴/縮容時,從機器下線到應用部署、測試,周期較長。當業務遇到突發流量高峰時,機器到手部署后,可能流量高峰已經過去了。
04多環境代碼不一致
由于過去內部開發流程的不規范,存在一些問題,業務提測的代碼在測試環境測試完畢后,在沙箱可能會進行修改、調整,然后再打包上線。
這就會導致測試的代碼和線上運行的代碼是不一致的,增加了服務上線的風險,也增加了線上服務故障排查的難度。
05缺少穩定的線下測試環境
在測試過程中,會遇到一個問題,服務依賴的其他下游服務都沒有提供穩定的測試環境。
這導致無法在測試環境模擬整個線上流程進行測試,所以很多測試同學會用線上服務進行測試,這里有很高的潛在風險。

為了解決上述問題,架構線云團隊進行了技術選型與反復論證,最終決定使用 Docker 容器技術。
58 私有云整體架構
58 私有云的整體架構如下圖:
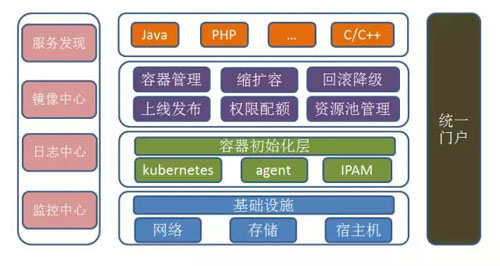
01基礎設施
整個私有云平臺接管了所有的基礎設施,包括服務器、存儲和網絡等資源。
02容器層
基礎設施之上提供了整個容器初始化層,容器初始化層包含 Kubernetes、Agent、IPAM;Kubernetes 是 Docker 的調度和管理組件。
Agent 部署在宿主機上,用于系統資源和底層基礎設施的管理,包含監控采集、日志采集、容器限速等。IPAM 是 Docker 的網絡管理模塊,用于管理整個網絡系統的 IP 資源。
03資源管理
容器層之上是資源管理層,包含容器管理、縮擴容、回滾降級、上線發布、配額管理、資源池管理等模塊。
04應用層
運行用戶提交的業務實例,可以是任意編程語言。
05基礎組件
私有云平臺為容器運行環境提供必備的基礎組件,包含服務發現、鏡像中心、日志中心、監控中心。
06服務發現
接入云平臺的服務提供統一的服務發現機制,便捷業務接入云平臺。
07鏡像中心
存儲業務鏡像,分布式存儲,可彈性擴展。
08日志中心
中心化收集業務實例日志,提供統一的可視化入口,方便用戶分析與查詢。
09監控中心
匯總全部的宿主和容器監控信息,監控視圖化,報警定制化,為智能化調度提供基礎。
10統一門戶
可視化的 UI 門戶頁面,規范化整個業務流程,簡潔的用戶流程,可動態管理整個云環境的所有資源。
全新的架構帶來全新的業務流轉方式:
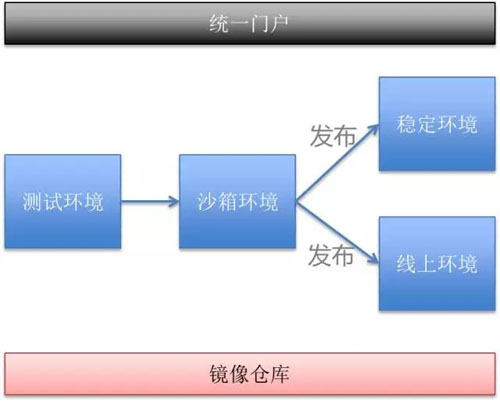
平臺定義了四套基礎環境:
- 測試環境:測試人員進行功能測試,對接到線下環境。
- 沙箱環境:程序預發布環境,對接到線上環境。
- 線上環境:提供服務的線上環境。
- 穩定環境:運行在線下環境的實例,為其他上游服務提供穩定的測試環境實例。
業務基于 SVN 提交的代碼構建鏡像,鏡像的整個生命周期就是在 4 個環境中流轉。因為是基于同一個鏡像創建實例,所以可以保證測試通過的程序與線上運行的程序是完全一致的。
核心模塊的設計方案
開發 58 私有云平臺需要考慮很多細節,這里主要和大家分享下其中的五個核心模塊:
- 容器管理。
- 網絡模型。
- 鏡像倉庫。
- 日志收集。
- 監控告警。
有了這幾個核心模塊,平臺就有了基礎框架,可以運轉起來。
01容器管理
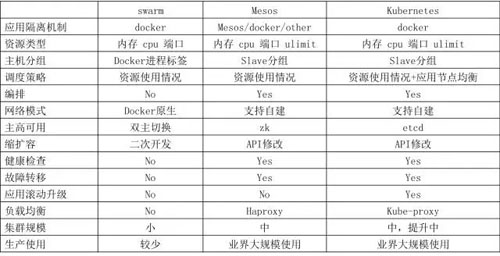
我們調研的基于 Docker 的管理平臺主要有三個:Swarm、Mesos、Kubernetes,通過對比,我們最終選擇了 Kubernetes。
Swarm 功能過于簡陋,所以最早就 pass 了,Mesos + Marathon 是一個成熟的解決方案,但是社區不夠活躍,而且使用起來要熟悉兩套框架。
Kubernetes 是專門針對容器技術提供的調度管理平臺,更專一,社區非常活躍,配套的組件與解決方案較多,使用它的公司也越來越多,通過和一些公司溝通,他們也在逐步的將 Docker 應用從 Mesos 遷移到 Kubernetes 上。
下面表格為我們團隊關注點的一些對比情況:
02網絡模型
網絡模型是任何云環境都必須面對的問題,因為網絡規模一旦擴大之后,會帶來各種問題。網絡選型這塊,針對 Docker 和 Kubernetes 的特性,對六種組網方式進行了對比,如下所示:
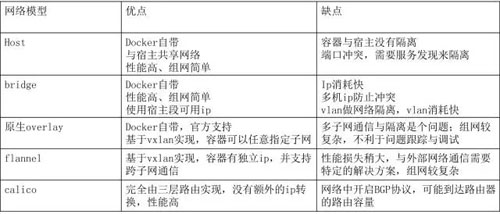
針對每種網絡模型,云團隊都做了相應的性能測試,Calico 除外,因為公司所用的機房不支持開啟 BGP 協議,所以沒有進行測試。
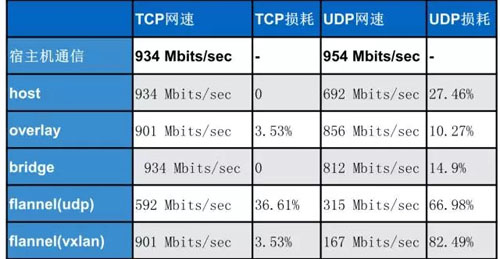
iPerf 測試網絡帶寬結果如下:
Qperf 測試 TCP 延遲結果如下:
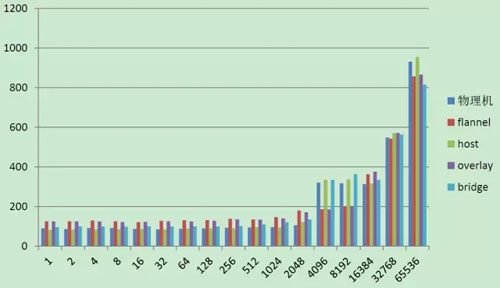
Qperf 測試 UDP 延遲結果如下:
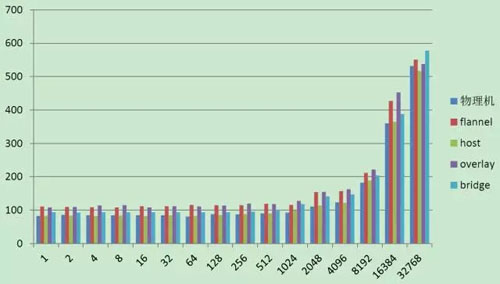
通過測試結果可以看出:Host 模式和 Bridge 模式性能與宿主機是最接近的,其他組網模式還是有一些差距的,這和 Overlay 的原理有關。
私有云平臺最終選擇了 Bridge + VLAN 的組網方式,原因如下:
- 性能較好,組網簡單,可以與現有網絡無縫對接;可以很好的實現容器與容器、容器與宿主互通。
- 故障易于調試,傳統的 SA 即可解決;適應任意物理設備,可大規模擴展。
- 公司內部服務之間都是基于 RPC 協議,有自己的服務發現機制,可以很好的兼容;現有內部框架改動小。
由于 VLAN 最多有 4096 個,所以 VLAN 是有個數限制的,這也是為什么會有 VLAN 的原因。
在云平臺當前的網絡規劃中,VLAN 是夠用的,未來隨著使用規模的擴大,技術的發展,我們也會深入研究更合適的組網方式。
網上也有同學反饋 Calico 的 IPIP 模式網絡性能也很高;但是考慮到 Calico 當前的坑比較多,需要有專門的網絡組來支撐,而這塊是云團隊所欠缺的,所以沒有深入調研。
這里還有一個問題,默認的使用 Bridge 模式是每個宿主機配置不同網段的地址,這樣就可以保證不同宿主機上為容器分配的 IP 不沖突,但是這樣也會導致出現大量的 IP 浪費。
機房的內網環境 IP 資源有限,沒有辦法這樣配置網絡,所以只能開發 IPAM 模塊進行全局的 IP 管理。
IPAM 模塊的實現參考了開源項目 Shrike 的實現,將可分配的網段寫入 etcd 中,Docker 實例啟動時,會通過 IPAM 模塊從 etcd 中獲取一個可用 IP,在實例關閉時,會對 IP 進行歸還,整體架構如下所示:

另外,由于 Kubernetes 不支持使用 CNM,所以我們針對 Kubernetes 源碼進行了修改。網絡方面還有一個點需要考慮:就是網絡限速。
03鏡像倉庫
Docker 的鏡像倉庫使用官方提供的鏡像倉庫,但是后端提供的存儲系統我們進行選型,默認的存在本地磁盤的方式是無法應用到線上系統的。具體的選型如下:
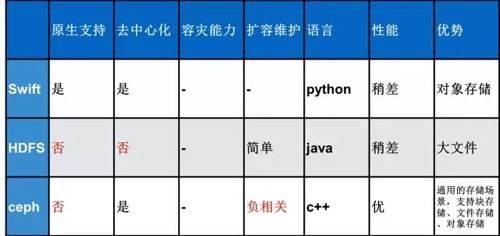
通過對比,可以看出 Ceph 是最合適的,但是最終云團隊選擇使用 HDFS 作為鏡像倉庫的后端存儲,原因如下:
- Swift 是官方默認提供支持的存儲類型,但是搭建一套 Swift 并保證其穩定運行需要專人深入研究,由于人員有限所以暫沒使用,Ceph 也是基于同理沒有進行選擇。
- HDFS 系統公司有專門的數據平臺部門在管理和維護,他們更專業,云團隊可以放心的將 Docker 鏡像托管到 HDFS 上。
但是 HDFS 本身也存在一些問題,比如壓力大時,NameNode 無法及時響應,未來我們會考慮將后端存儲遷移到架構線部門內部自研的對象存儲中,以提供穩定高效的服務。
04日志系統
傳統服務遷移到容器環境,日志是一個大問題。因為容器即用即銷,容器關閉后,容器的存儲也會被刪除。
雖然可以把容器中的日志導出到宿主機上的指定位置,但是容器會經常漂移,在排查故障時,我們還需要知道歷史上的某一時刻,某個容器在哪臺宿主機上運行,并且由于使用方沒有宿主機的登陸權限,所以使用方也沒法很好的獲取日志。
在容器環境下,需要新的故障排查方式。這里,一個通用的解決方案就是采用中心化的日志解決方案,將零散的日志統一進行收集存儲,并提供靈活的查詢方式。
私有云平臺采用的方案如下:

使用方在管理門戶上配置要采集的日志,私有云平臺通過環境變量的方式映射到容器中,宿主機上部署的 Agent 根據環境變量獲取要采集的日志,啟動 Flume 進行采集。
Flume 將日志統一上傳到 Kafka 中,上傳到 Kafka 中的日志保證嚴格的先后順序。
Kafka 有兩個訂閱者,一個將日志上傳到搜索服務中,供管理門戶查詢使用;一個將日志上傳到 HDFS 中,用于歷史日志的查詢和下載,使用方也可以自己編寫 Hadoop 程序對指定日志進行分析。
05監控告警
資源的監控和報警也是一個云平臺必不可少的部分。針對容器的監控有很多成熟的開源軟件可供選擇,58 內部也有專門的監控組件,如何更好的監控,云團隊也進行了相應的選型。

最終,云團隊選擇使用 WMonitor 來作為容器的監控組件,因為 WMonitor 本身集成了物理機和報警邏輯,我們不需要再做相對應的開發,只需要開發容器監控部分的組件,并且針對內部的監控需求,我們可以很好的進行定制。
Heapster + InfluxDB + Grafana 是 Kubernetes 官方提供的監控組件,規模小時用它也沒有問題,但是規模大時使用它可能會存在問題,因為它是輪詢獲取所有節點監控信息的。
后記
以上內容是 58 同城架構線針對容器技術如何落地進行的相關探索,很多技術選型無關優劣,只選擇適合 58 相關應用場景的。整個云平臺要解決的技術點有很多,這里選取了其中幾個關鍵的點和大家進行分享。