關于Hadoop技術的HA機制學習

導語
最近分享過一次關于Hadoop技術主題的演講,由于接觸時間不長,很多技術細節認識不夠,也沒講清楚,作為一個技術人員,本著追根溯源的精神,還是有必要吃透,也為自己的工作沉淀一些經驗總結。網上關于Hadoop HA的資料多集中于怎么搭建HA,對于HA為什么要這么做描述甚少,所以本文對于HA是如何搭建的暫不介紹,主要是介紹HA是怎么運作,QJM又是怎么發揮功效的。
一、Hadoop 系統架構
1.1 Hadoop1.x和Hadoop2.x 架構
在介紹HA之前,我們先來看下Hadoop的系統架構,這對于理解HA是至關重要的。Hadoop 1.x之前,其官方架構如圖1所示:
[ 圖1.Hadoop 1.x架構圖 ]
從圖中可看出,1.x版本之前只有一個Namenode,所有元數據由惟一的Namenode負責管理,可想而之當這個NameNode掛掉時整個集群基本也就不可用。
Hadoop 2.x的架構與1.x有什么區別呢。我們來看下2.x的架構:
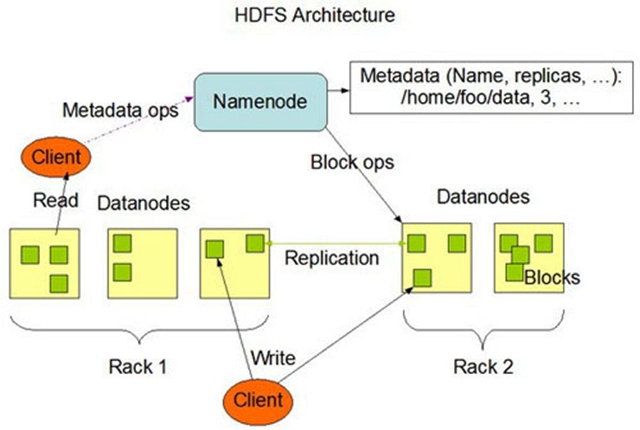
[ 圖2.Hadoop 2.x架構圖 ]
2.x版本中,HDFS架構解決了單點故障問題,即引入雙NameNode架構,同時借助共享存儲系統來進行元數據的同步,共享存儲系統類型一般有幾類,如:Shared NAS+NFS、BookKeeper、BackupNode 和 Quorum Journal Manager(QJM),上圖中用的是QJM作為共享存儲組件,通過搭建奇數結點的JournalNode實現主備NameNode元數據操作信息同步。Hadoop的元數據包括哪些信息呢,下面介紹下關于元數據方面的知識。
1.2 Hadoop 2.x元數據
Hadoop的元數據主要作用是維護HDFS文件系統中文件和目錄相關信息。元數據的存儲形式主要有3類:內存鏡像、磁盤鏡像(FSImage)、日志(EditLog)。在Namenode啟動時,會加載磁盤鏡像到內存中以進行元數據的管理,存儲在NameNode內存;磁盤鏡像是某一時刻HDFS的元數據信息的快照,包含所有相關Datanode節點文件塊映射關系和命名空間(Namespace)信息,存儲在NameNode本地文件系統;日志文件記錄client發起的每一次操作信息,即保存所有對文件系統的修改操作,用于定期和磁盤鏡像合并成***鏡像,保證NameNode元數據信息的完整,存儲在NameNode本地和共享存儲系統(QJM)中。
如下所示為NameNode本地的EditLog和FSImage文件格式,EditLog文件有兩種狀態: inprocess和finalized, inprocess表示正在寫的日志文件,文件名形式:editsinprocess[start-txid],finalized表示已經寫完的日志文件,文件名形式:edits[start-txid][end-txid]; FSImage文件也有兩種狀態, finalized和checkpoint, finalized表示已經持久化磁盤的文件,文件名形式: fsimage_[end-txid], checkpoint表示合并中的fsimage, 2.x版本checkpoint過程在Standby Namenode(SNN)上進行,SNN會定期將本地FSImage和從QJM上拉回的ANN的EditLog進行合并,合并完后再通過RPC傳回ANN。
- data/hbase/runtime/namespace
- ├── current
- │ ├── VERSION
- │ ├── edits_0000000003619794209-0000000003619813881
- │ ├── edits_0000000003619813882-0000000003619831665
- │ ├── edits_0000000003619831666-0000000003619852153
- │ ├── edits_0000000003619852154-0000000003619871027
- │ ├── edits_0000000003619871028-0000000003619880765
- │ ├── edits_0000000003619880766-0000000003620060869
- │ ├── edits_inprogress_0000000003620060870
- │ ├── fsimage_0000000003618370058
- │ ├── fsimage_0000000003618370058.md5
- │ ├── fsimage_0000000003620060869
- │ ├── fsimage_0000000003620060869.md5
- │ └── seen_txid
- └── in_use.lock
上面所示的還有一個很重要的文件就是seen_txid,保存的是一個事務ID,這個事務ID是EditLog***的一個結束事務id,當NameNode重啟時,會順序遍歷從edits_0000000000000000001到seen_txid所記錄的txid所在的日志文件,進行元數據恢復,如果該文件丟失或記錄的事務ID有問題,會造成數據塊信息的丟失。
HA其本質上就是要保證主備NN元數據是保持一致的,即保證fsimage和editlog在備NN上也是完整的。元數據的同步很大程度取決于EditLog的同步,而這步驟的關鍵就是共享文件系統,下面開始介紹一下關于QJM共享存儲機制。
二、QJM原理
2.1 QJM背景
在QJM出現之前,為保障集群的HA,設計的是一種基于NAS的共享存儲機制,即主備NameNode間通過NAS進行元數據的同步。該方案有什么缺點呢,主要有以下幾點:
- 定制化硬件設備:必須是支持NAS的設備才能滿足需求
- 復雜化部署過程:在部署好NameNode后,還必須額外配置NFS掛載、定制隔離腳本,部署易出錯
- 簡陋化NFS客戶端:Bug多,部署配置易出錯,導致HA不可用
所以對于替代方案而言,也必須解決NAS相關缺陷才能讓HA更好服務。即設備無須定制化,普通設備即可配置HA,部署簡單,相關配置集成到系統本身,無需自己定制,同時元數據的同步也必須保證完全HA,不會因client問題而同步失敗。
2.2 QJM原理
2.2.1 QJM介紹
QJM全稱是Quorum Journal Manager, 由JournalNode(JN)組成,一般是奇數點結點組成。每個JournalNode對外有一個簡易的RPC接口,以供NameNode讀寫EditLog到JN本地磁盤。當寫EditLog時,NameNode會同時向所有JournalNode并行寫文件,只要有N/2+1結點寫成功則認為此次寫操作成功,遵循Paxos協議。其內部實現框架如下:
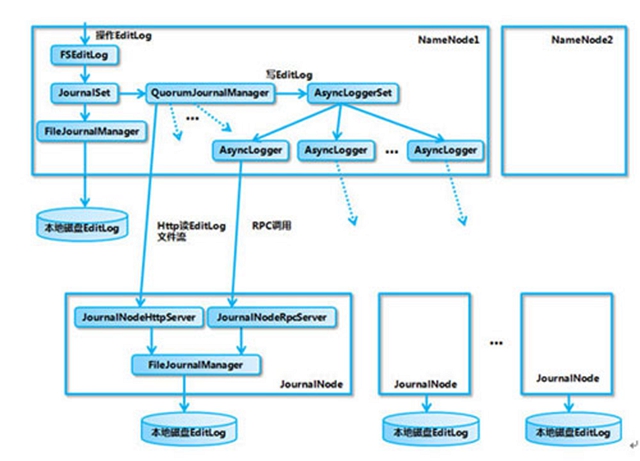
[ 圖3.QJM內部實現框架 ]
從圖中可看出,主要是涉及EditLog的不同管理對象和輸出流對象,每種對象發揮著各自不同作用:
- FSEditLog:所有EditLog操作的入口
- JournalSet: 集成本地磁盤和JournalNode集群上EditLog的相關操作
- FileJournalManager: 實現本地磁盤上 EditLog 操作
- QuorumJournalManager: 實現JournalNode 集群EditLog操作
- AsyncLoggerSet: 實現JournalNode 集群 EditLog 的寫操作集合
- AsyncLogger:發起RPC請求到JN,執行具體的日志同步功能
- JournalNodeRpcServer:運行在 JournalNode 節點進程中的 RPC 服務,接收 NameNode 端的 AsyncLogger 的 RPC 請求。
- JournalNodeHttpServer:運行在 JournalNode 節點進程中的 Http 服務,用于接收處于 Standby 狀態的 NameNode 和其它 JournalNode 的同步 EditLog 文件流的請求。
下面具體分析下QJM的讀寫過程。
2.2.2 QJM 寫過程分析
上面提到EditLog,NameNode會把EditLog同時寫到本地和JournalNode。寫本地由配置中參數dfs.namenode.name.dir控制,寫JN由參數dfs.namenode.shared.edits.dir控制,在寫EditLog時會由兩個不同的輸出流來控制日志的寫過程,分別為:EditLogFileOutputStream(本地輸出流)和QuorumOutputStream(JN輸出流)。寫EditLog也不是直接寫到磁盤中,為保證高吞吐,NameNode會分別為EditLogFileOutputStream和QuorumOutputStream定義兩個同等大小的Buffer,大小大概是512KB,一個寫Buffer(buffCurrent),一個同步Buffer(buffReady),這樣可以一邊寫一邊同步,所以EditLog是一個異步寫過程,同時也是一個批量同步的過程,避免每寫一筆就同步一次日志。
這個是怎么實現邊寫邊同步的呢,這中間其實是有一個緩沖區交換的過程,即bufferCurrent和buffReady在達到條件時會觸發交換,如bufferCurrent在達到閾值同時bufferReady的數據又同步完時,bufferReady數據會清空,同時會將bufferCurrent指針指向bufferReady以滿足繼續寫,另外會將bufferReady指針指向bufferCurrent以提供繼續同步EditLog。上面過程用流程圖就是表示如下:
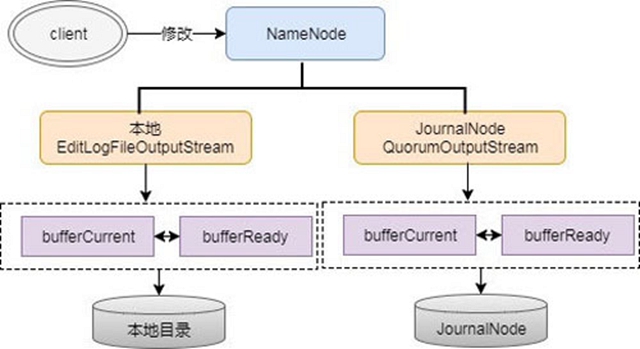
[ 圖4.EditLog輸出流程圖 ]
這里有一個問題,既然EditLog是異步寫的,怎么保證緩存中的數據不丟呢,其實這里雖然是異步,但實際所有日志都需要通過logSync同步成功后才會給client返回成功碼,假設某一時刻NameNode不可用了,其內存中的數據其實是未同步成功的,所以client會認為這部分數據未寫成功。
第二個問題是,EditLog怎么在多個JN上保持一致的呢。下面展開介紹。
1.隔離雙寫:
在ANN每次同步EditLog到JN時,先要保證不會有兩個NN同時向JN同步日志。這個隔離是怎么做的。這里面涉及一個很重要的概念Epoch Numbers,很多分布式系統都會用到。Epoch有如下幾個特性:
- 當NN成為活動結點時,其會被賦予一個EpochNumber
- 每個EpochNumber是惟一的,不會有相同的EpochNumber出現
- EpochNumber有嚴格順序保證,每次NN切換后其EpochNumber都會自增1,后面生成的EpochNumber都會大于前面的EpochNumber
QJM是怎么保證上面特性的呢,主要有以下幾點:
- ***步,在對EditLog作任何修改前,QuorumJournalManager(NameNode上)必須被賦予一個EpochNumber
- 第二步, QJM把自己的EpochNumber通過newEpoch(N)的方式發送給所有JN結點
- 第三步, 當JN收到newEpoch請求后,會把QJM的EpochNumber保存到一個lastPromisedEpoch變量中并持久化到本地磁盤
- 第四步, ANN同步日志到JN的任何RPC請求(如logEdits(),startLogSegment()等),都必須包含ANN的EpochNumber
- 第五步,JN在收到RPC請求后,會將之與lastPromisedEpoch對比,如果請求的EpochNumber小于lastPromisedEpoch,將會拒絕同步請求,反之,會接受同步請求并將請求的EpochNumber保存在lastPromisedEpoch
這樣就能保證主備NN發生切換時,就算同時向JN同步日志,也能保證日志不會寫亂,因為發生切換后,原ANN的EpochNumber肯定是小于新ANN的EpochNumber,所以原ANN向JN的發起的所有同步請求都會拒絕,實現隔離功能,防止了腦裂。
2. 恢復in-process日志
為什么要這步呢,如果在寫過程中寫失敗了,可能各個JN上的EditLog的長度都不一樣,需要在開始寫之前將不一致的部分恢復。恢復機制如下:
- ANN先向所有JN發送getJournalState請求;
- JN會向ANN返回一個Epoch(lastPromisedEpoch);
- ANN收到大多數JN的Epoch后,選擇***的一個并加1作為當前新的Epoch,然后向JN發送新的newEpoch請求,把新的Epoch下發給JN;
- JN收到新的Epoch后,和lastPromisedEpoch對比,若更大則更新到本地并返回給ANN自己本地一個***EditLogSegment起始事務Id,若小則返回NN錯誤;
- ANN收到多數JN成功響應后認為Epoch生成成功,開始準備日志恢復;
- ANN會選擇一個***的EditLogSegment事務ID作為恢復依據,然后向JN發送prepareRecovery; RPC請求,對應Paxos協議2p階段的Phase1a,若多數JN響應prepareRecovery成功,則可認為Phase1a階段成功;
- ANN選擇進行同步的數據源,向JN發送acceptRecovery RPC請求,并將數據源作為參數傳給JN。
- JN收到acceptRecovery請求后,會從JournalNodeHttpServer下載EditLogSegment并替換到本地保存的EditLogSegment,對應Paxos協議2p階段的Phase1b,完成后返回ANN請求成功狀態。
- ANN收到多數JN的響應成功請求后,向JN發送finalizeLogSegment請求,表示數據恢復完成,這樣之后所有JN上的日志就能保持一致。
數據恢復后,ANN上會將本地處于in-process狀態的日志更名為finalized狀態的日志,形式如edits[start-txid][stop-txid]。
3.日志同步
這個步驟上面有介紹到關于日志從ANN同步到JN的過程,具體如下:
- 執行logSync過程,將ANN上的日志數據放到緩存隊列中
- 將緩存中數據同步到JN,JN有相應線程來處理logEdits請求
- JN收到數據后,先確認EpochNumber是否合法,再驗證日志事務ID是否正常,將日志刷到磁盤,返回ANN成功碼
- ANN收到JN成功請求后返回client寫成功標識,若失敗則拋出異常
通過上面一些步驟,日志能保證成功同步到JN,同時保證JN日志的一致性,進而備NN上同步日志時也能保證數據是完整和一致的。
2.2.3 QJM讀過程分析
這個讀過程是面向備NN(SNN)的,SNN定期檢查JournalNode上EditLog的變化,然后將EditLog拉回本地。SNN上有一個線程StandbyCheckpointer,會定期將SNN上FSImage和EditLog合并,并將合并完的FSImage文件傳回主NN(ANN)上,就是所說的Checkpointing過程。下面我們來看下Checkpointing是怎么進行的。
在2.x版本中,已經將原來的由SecondaryNameNode主導的Checkpointing替換成由SNN主導的Checkpointing。下面是一個CheckPoint的流向圖:
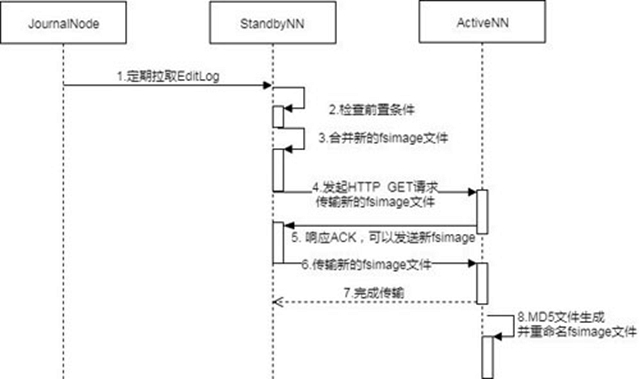
[ 圖5.Checkpointing流向圖 ]
總的來說,就是在SNN上先檢查前置條件,前置條件包括兩個方面:距離上次Checkpointing的時間間隔和EditLog中事務條數限制。前置條件任何一個滿足都會觸發Checkpointing,然后SNN會將***的NameSpace數據即SNN內存中當前狀態的元數據保存到一個臨時的fsimage文件( fsimage.ckpt)然后比對從JN上拉到的***EditLog的事務ID,將fsimage.ckpt_中沒有,EditLog中有的所有元數據修改記錄合并一起并重命名成新的fsimage文件,同時生成一個md5文件。將***的fsimage再通過HTTP請求傳回ANN。通過定期合并fsimage有什么好處呢,主要有以下幾個方面:
可以避免EditLog越來越大,合并成新fsimage后可以將老的EditLog刪除
可以避免主NN(ANN)壓力過大,合并是在SNN上進行的
可以保證fsimage保存的是一份***的元數據,故障恢復時避免數據丟失
三、主備切換機制
要完成HA,除了元數據同步外,還得有一個完備的主備切換機制,Hadoop的主備選舉依賴于ZooKeeper。下面是主備切換的狀態圖:
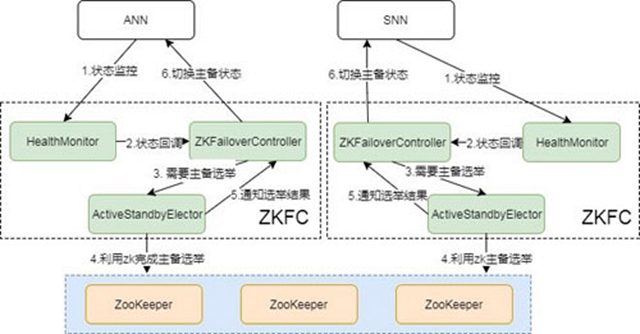
[ 圖6.Failover流程圖 ]
從圖中可以看出,整個切換過程是由ZKFC來控制的,具體又可分為HealthMonitor、ZKFailoverController和ActiveStandbyElector三個組件。
- ZKFailoverController: 是HealthMontior和ActiveStandbyElector的母體,執行具體的切換操作
- HealthMonitor: 監控NameNode健康狀態,若狀態異常會觸發回調ZKFailoverController進行自動主備切換
- ActiveStandbyElector: 通知ZK執行主備選舉,若ZK完成變更,會回調ZKFailoverController相應方法進行主備狀態切換
在故障切換期間,ZooKeeper主要是發揮什么作用呢,有以下幾點:
- 失敗保護:集群中每一個NameNode都會在ZooKeeper維護一個持久的session,機器一旦掛掉,session就會過期,故障遷移就會觸發
- Active NameNode選擇:ZooKeeper有一個選擇ActiveNN的機制,一旦現有的ANN宕機,其他NameNode可以向ZooKeeper申請排他成為下一個Active節點
- 防腦裂: ZK本身是強一致和高可用的,可以用它來保證同一時刻只有一個活動節點
那在哪些場景會觸發自動切換呢,從HDFS-2185中歸納了以下幾個場景:
- ActiveNN JVM奔潰:ANN上HealthMonitor狀態上報會有連接超時異常,HealthMonitor會觸發狀態遷移至SERVICE_NOT_RESPONDING, 然后ANN上的ZKFC會退出選舉,SNN上的ZKFC會獲得Active Lock, 作相應隔離后成為Active結點。
- ActiveNN JVM凍結:這個是JVM沒奔潰,但也無法響應,同奔潰一樣,會觸發自動切換。
- ActiveNN 機器宕機:此時ActiveStandbyElector會失去同ZK的心跳,會話超時,SNN上的ZKFC會通知ZK刪除ANN的活動鎖,作相應隔離后完成主備切換。
- ActiveNN 健康狀態異常: 此時HealthMonitor會收到一個HealthCheckFailedException,并觸發自動切換。
- Active ZKFC奔潰:雖然ZKFC是一個獨立的進程,但因設計簡單也容易出問題,一旦ZKFC進程掛掉,雖然此時NameNode是OK的,但系統也認為需要切換,此時SNN會發一個請求到ANN要求ANN放棄主結點位置,ANN收到請求后,會觸發完成自動切換。
- ZooKeeper奔潰:如果ZK奔潰了,主備NN上的ZKFC都會感知斷連,此時主備NN會進入一個NeutralMode模式,同時不改變主備NN的狀態,繼續發揮作用,只不過此時,如果ANN也故障了,那集群無法發揮Failover, 也就不可用了,所以對于此種場景,ZK一般是不允許掛掉到多臺,至少要有N/2+1臺保持服務才算是安全的。
五、總結
上面介紹了下關于HadoopHA機制,歸納起來主要是兩塊:元數據同步和主備選舉。元數據同步依賴于QJM共享存儲,主備選舉依賴于ZKFC和Zookeeper。整個過程還是比較復雜的,如果能理解Paxos協議,那也能更好的理解這個。希望這篇文章能讓大家更深入了解關于HA方面的知識。