數據庫高可用方案PK:選擇Oracle還是MySQL?
關于Oracle和MySQL的高可用方案,其實一直想要總結了,今天分為幾個系列簡單說說。通過這樣的對比,會對兩種數據庫架構設計上的細節差異有一個基本的認識。
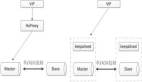
高可用方案概覽
Oracle有一套很成熟的高可用解決方案MAA。用我在OOW上的ppt來看,這個方案自9i開始,到今年已經有16個年頭了。

當然,MAA方案雖好,成本還是有的、復雜度還是有的,所以放眼國內的使用情況,RAC不一定是100%有,電信、證券、壽險、銀行如果用,基本都是全套方案,有些相對保守,RAC也有使用active-passive模式的,互聯網行業如果用,清一色都是單實例和DG結合。
而MySQL因為開源的特點,官方和社區里推出了很更多的解決方案,高可用情況大體如下,僅供參考(數據引用自Percona)。
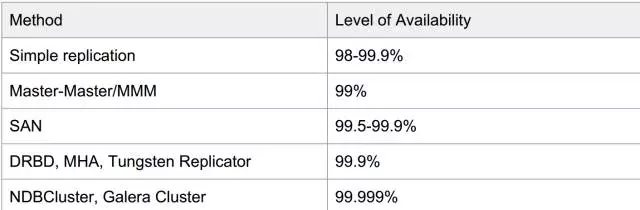
因為時間的原因,MGR剛推出不久,還在觀察期。MGR固然不錯,MySQL Cluster方案也有PXC、Galera等方案,個人還是更傾向于MHA。
基本情況說完了,接下來分為幾個部分來解讀。
Oracle RAC和MySQL MHA
先拿RAC和MHA來做一個基本的對比。
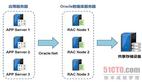
Oracle的解決方案在阿里快速發展時期支撐起了核心業務的需求。大概是這樣的架構體系,看起來很龐大。里面的RAC算是一個貴族,用昂貴的商業存儲,網絡帶寬要求極高,前端大量的小機業務還有不菲的license費用。非常典型的IOE的經典架構。

如果要考慮異地容災,那么資源配置要double,預算翻番。
MySQL的架構方案相對來說更加平民化,普通的PC就可以,但數量級要高,做業務拆分、水平拆分就能夠橫向擴展出非常多的節點,很多大互聯網公司的MySQL集群規模都是幾百幾百的規模,上千都不稀奇。如此之多的服務資源,發生故障的概率還是有的,保證業務服務的可持續性訪問是技術方案的關鍵。如果按照MHA的架構,基本上就是MHA Manager節點來負責整個集群的狀態,好比一個居委會大媽,對住戶的大大小小的事情都了如指掌包打聽。
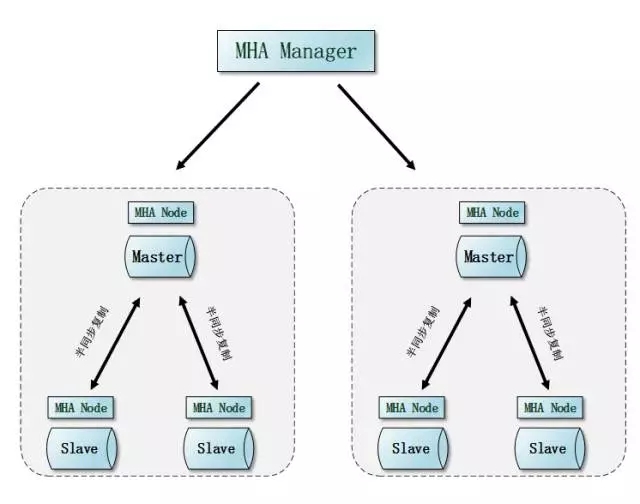
當然上面的架構圖過于籠統,在MHA的高版本里面還使用了binlogServer,我們從一些細節入手。比如先來說說網絡的事情。
Oracle對于網絡的要求還是很嚴格的,一般都是要2塊物理網卡,每臺服務器需要至少3個IP:Public IP、private IP、VIP,除了共享存儲,至少需要2個計算節點。
private IP是節點間互信的,Public IP和VIP在一個網段,簡單來說,VIP是對外的,是public IP所在網絡的漂移IP,在10g里面都是通過VIP來做負載均衡的,11g開始有了scan-IP,原來的VIP還是保留,所以Oracle里面的網絡配置要求還是很高的。拋開共享存儲,搭建的核心就是網絡配置了,網絡通則通。
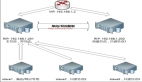
scan-IP還可以繼續擴展,最多支持3個scan-ip,如下圖所示:[[208772]]
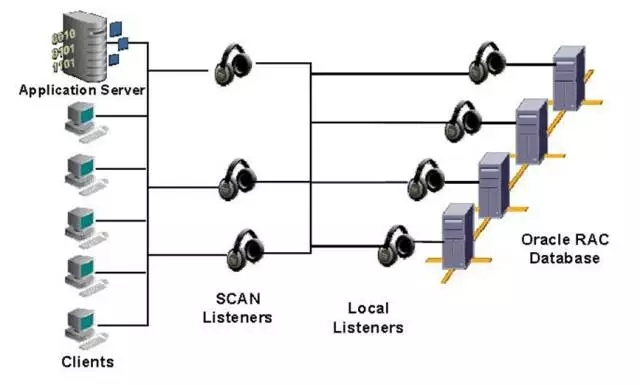
當然網絡層面不只是這些,我們還有必要了解下TAF(Transparent Application Failover)。TAF是Oracle中對應用透明的故障轉移,在RAC環境中使用尤其廣泛。在RAC中Load Balance這塊確實做了很大的改進,從10g版本開始的多個VIP地址的Load Balance,到11g版本中的SCAN,做了很大的簡化。
而在Failover的實現中,還是有一定的使用限定,比如11g中默認的SCAN-IP的實現其實默認沒有Failover的選項,如果兩個節點中的其中一個節點掛了,那么原有的連接中繼續查詢就會提示session已經斷開,需要重新連接。客戶端TAF主要會討論Failover Method和Failover Type的一些簡單內容。
(1)Failover Method
Failover Method的主要思路就是換取故障轉移時間,或者換取資源來實現。
可以這樣來理解,假設我們存在兩個節點,如果某個session連接到了節點2,然而節點2突然掛了,為了更快處理Failover這種情況,Failover Method有preconnect和basic兩種。
- preconnect這種預連接方式還是會占用較多的資源使用,在各個節點上會預先占用一部分額外的資源,在切換時會相對更加平滑,速度更快。
- basic這種方式,則在發生Failover時,再去切換對應的資源,中間會有一些卡頓,但是對于資源的消耗相對來說要小很多。
簡單來說,basic方式會在故障發生時才去判斷,而preconnect則是未雨綢繆;從實際的應用來說,basic這種方式更加通用,也是默認的故障轉移方式。
(2)Failover Type
Failover Type實現更加豐富而且靈活,非常強大。這時控制粒度可以針對用戶SQL的執行情況進行控制,有select和session兩種;通過一個小例子說明一下。
比如,我們有個很大的查詢在節點2上進行,結果節點2突然宕機了,對于正在執行的查詢,比如說有10 000條數據,結果剛好故障發生的時候查出了8 000條,那么剩下的2 000該怎么處理。
第一種方式就是使用select;即會完成故障切換,繼續把剩下的2 000條記錄返回,當然中間會有一些上下文環境的切換,對于用戶是透明的。
第二種方式是session;即直接斷開連接,要求重新查詢。
在10g版本中借助于VIP的配置達到Load Balance+Failover的配置如下:
racdb=
(DESCRIPTION =
(ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.101)(PORT= 1521))
(ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.201)(PORT= 1521))
(LOAD_BALANCE = yes)
(FAILOVER = ON)
(CONNECT_DATA =
(SERVER= DEDICATED)
(SERVICE_NAME = racdb)
(FAILOVER_MODE =
(TYPE= SELECT)
(METHOD= BASIC)
(RETRIES = 30)
(DELAY = 5))))如果11g的SCAN-IP也想進一步擴展Failover,同樣也需要設置failover_mode和對應的類型。
RACDB =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = rac-scan)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = RACDB)
)
)從這個角度來看,Oracle的方案真是精細。
再來看看MySQL的方案。
分布式的方案,讓MySQL看起來像一把瑞士軍刀,對于網絡層面的要求,幾乎可以說MySQL沒有什么要求,申請一主一從的架構,那么就只需要4個IP即可(主、從、VIP、MHA_Manager(考慮一個manager節點)),一主兩從是5個。
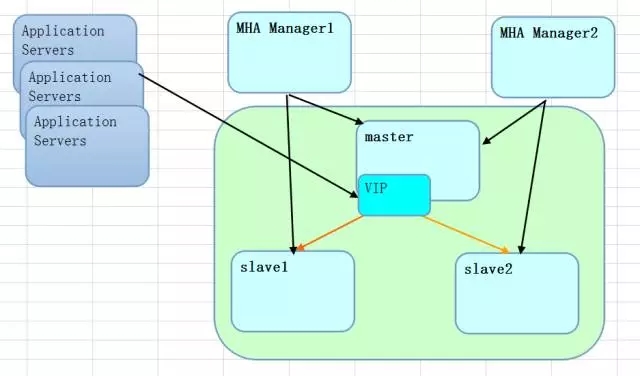
這一點上,MySQL原生并不支持所謂的負載均衡(這里說的不是讀寫分離),可以通過前端的業務來分流,比如使用中間件proxy,或者持續的拆分,達到一定的粒度后,通過架構設計的方式來滿足需求。因為基于邏輯的復制,很容易擴展,一主多從都是很常見的,代價也不高,延遲不能說沒有,只是很低,能夠適應絕大部分的互聯網業務需求。
而說到觸發MHA切換的條件,從網絡層面來看,如下的紅點都是潛在的隱患,有的是網絡的中斷,有的是網絡的延遲,發生故障時,保數據還是保性能穩定,都可以基于自己的需求來定制。從這一點上來說,丟失數據的概率是有的。絕對不是強一致性的無損復制。
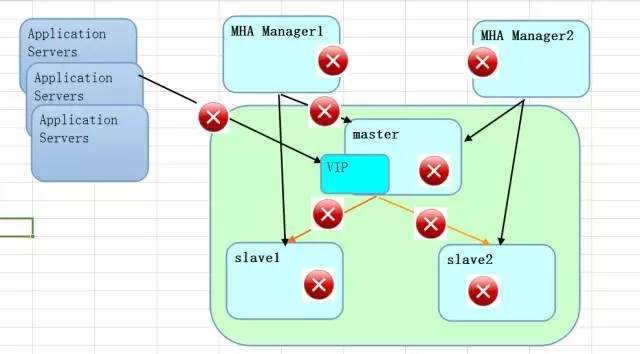
把上面的圖放大,其實會有更多的細節,比如ssh的連接檢測和數據庫的心跳檢測(insert_ping),在整個方案里面要考慮的場景就很多了。對于網絡的切換,目前MHA做的主要是保證數據復制關系,如果要深入使用,還是要做更多的定制,比如結合Proxy的方案,使用ZooKeeper的狀態檢測,使用keepalive或者VIP的網絡層面的切換等。
整體來看兩種方案,RAC是集中共享,除了存儲層面的共享外,網絡層面的組播其實也會提高節點間通信的成本,所以RAC對于網絡的需求很大,如果存在延遲是很危險的,發生了腦裂就很尷尬了。MySQL MHA的方案是分布式的。支持大批量的環境,節點間通信的成本相對來說要低很多。但是從數據架構的角度來說,因為是復制的數據分布方式,所以對于存儲盡管不是共享存儲,對于存儲的成本還是高于RAC(不是說存儲的價格,是存儲的數據量大小)。
Oracle Data Guard和MySQL災備
然后我們來繼續說說災備的部分。我就拿Oracle的DG和MySQL的方案對比。
在災備的概念中,Oracle DBA習慣叫做主備,即為Primary、Standby,而MySQL更喜歡叫做主從,即為Master、Slave,無論怎么叫,說得都是同一個意思。
首先在Oracle中,數據是基于物理復制(此處說的都是physical standby),所以對于數據庫的狀態和角色就很好定位,從庫正常狀況下是無法讀寫的。所以在Oracle中角色轉換的概念就很清晰,failover和switchover,failover就是故障轉義,switchover就是主備切換。在MySQL中failover的概念很好理解,但是switchover相比來說,就會淡化很多。
Oracle因為是基于物理復制,所以一直以來備庫要么就是恢復狀態(recover),要么就是只讀不應用狀態(read_only),直到11g這個問題才解決,就是大名鼎鼎的ADG(read only with apply)。而在MySQL里面這都不是事兒,備庫可以靈活的開關read_only的參數,當然一般是不希望備庫寫入的,讀絕對不是問題,而且還可以擴展著讀,做讀寫分離。
對于Oracle的備庫的理解,我認為除了ADG之外,最有亮點的就是閃回數據庫了,可能很多Oracle DBA都對于閃回數據庫敬而遠之,技術的更新很多,好端端的特性放著不用太可惜了,比如搭建DG,分分鐘DG Broker搞定,使用手工方式不見得有多高效。
閃回的概念在MySQL里面也有,目前來說,可以根據binlog抽取的數據做到DML的閃回,和Oracle里面的閃回差距還很大。Oracle里面的閃回五花八門,零零總總算下,差不多就有這些。

當然常用、實用的不見得這么多,MySQL的DML還算是原生態,可以根據binlog抽取來恢復,或根據第三方工具輔助,但DDL就是難上加難了,目前MariaDB的DDL閃回就是一個突破,從我的理解來說,應該能夠實現一部分的閃回功能,具體的效果我后面測試一下。
所以說閃回是個大寶藏,到底有多好呢,Oracle的備庫方案有了快照數據庫,就是物理備庫可以臨時寫入,帶來的優點就是主庫的碎片,在備庫是完全一樣的。所以在SQL審核方面有著得天獨厚的優勢,我在線上的很多DDL審核中都做過測試和實際應用,效果很贊,而且11g中的閃回可以在線開在線關,所以一般10g里面我建議要慎重使用,11g有條件下備庫端還是推薦的,滿足需求就行。當然閃回數據庫不是萬金油,有個別場景是不支持的,在此就不展開了。
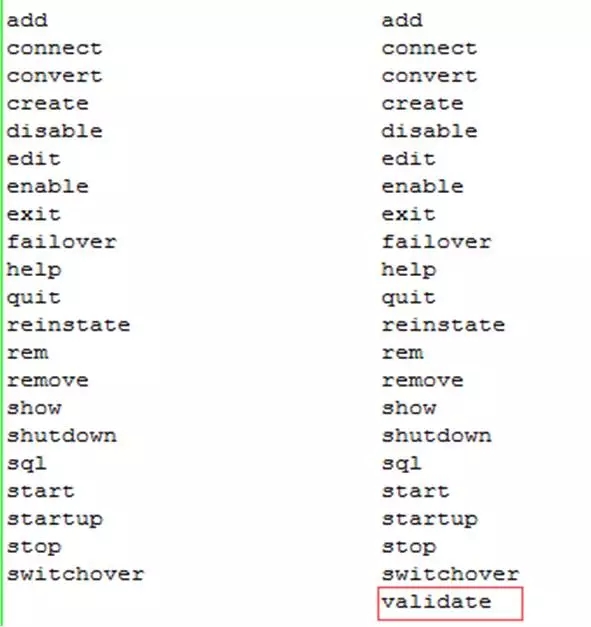
對于災備來說,數據庫的切換是未雨綢繆的事情,那么到底備庫切換的檢查是否OK呢,Oracle里面有了DG Broker這么一個神器,還在新版本中做了很多不錯的選項,比如新版本中有了validate的選項,可以檢測主備切換的條件是否滿足。下面是DG Broker的命令中多出來的validate命令,效果還是不錯的。
此外,從高可用的角度來說,如果在備庫存在連接,做switchover時,會話會持續保持,當然會有短暫的卡頓。這也就是特色的會話保持特性。
Preserving Active Data Guard Application Connections
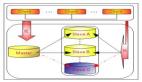
當然在MySQL里面就不可理解了,切換別說會話保持,卡頓的影響都微乎其微。因為Oracle基于物理復制的方式,物理一致性使得復制擴展性很難,當然也不是說完全不能實現,比如cascade standby,可以級聯復制,到了12c改進一版,就是Far Sync,號稱是零數據丟失,對于跨區域的數據中心來說,會把延遲降到最低。
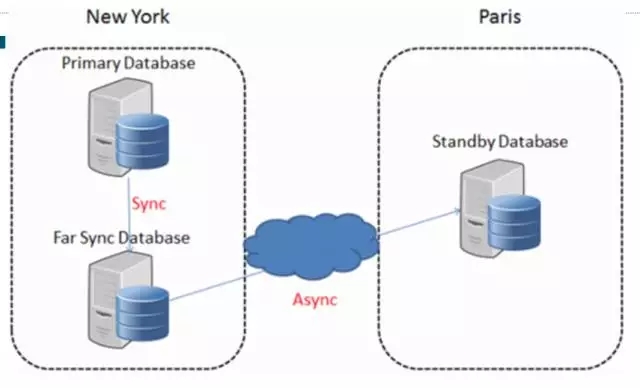
如果從技術架構的角度來看,部署的分布圖類似下面的形式,中間有遠距離的數據傳輸,可以通過中間的節點來轉換,中間這個節點很特別,是不存數據的,只是保持一個內存結構,同步數據。

還有就是延遲,我測試過DG的延遲,和MySQL在基本相似的壓力情況下,Oracle基本上控制在0.1秒左右,MySQL的復制就會有一些延遲的放大。
所以總體看下來,Oracle的方案是一種很專業的解決方案,工具全,架構相對復雜,數據同步是強一致性。所以在涉及交易的業務中對它更加偏愛。
再來看看MySQL方向的改進。我們不比單機性能和延遲了,因為這個確實是有差距,而且硬拼也沒有太大的意義,我們從整體架構角度來考慮,這些又是Oracle難以實現的地方。
首先說下主從復制,MySQL是典型的邏輯復制,主庫端可以承載大批量的并發,但是性能瓶頸很明顯,主庫的并發最后落到文件上還是串行的,拋開日志傳輸進程的開銷,最大的瓶頸就在于SQL_Thread的應用延遲。就好比中午大家出去吃飯,前臺可以并發點很多的菜品,但后臺的廚師就好比是SQL_Thread,他得一道菜一道菜做啊。怎么能做得更快呢?比如你叫了5分蓋飯,他可以一次性炒出來,這樣就能夠大大提高效率,所以前臺的小姑娘也會建議你和其他人點一樣的菜,原因就一個字——快。這用在并行復制上就是類似的道理。MySQL 5.6沒法做到細粒度的并行復制,只能在庫級別,而在MySQL 5.7中可以做到表級別更細粒度的,這個改進就很明顯了。
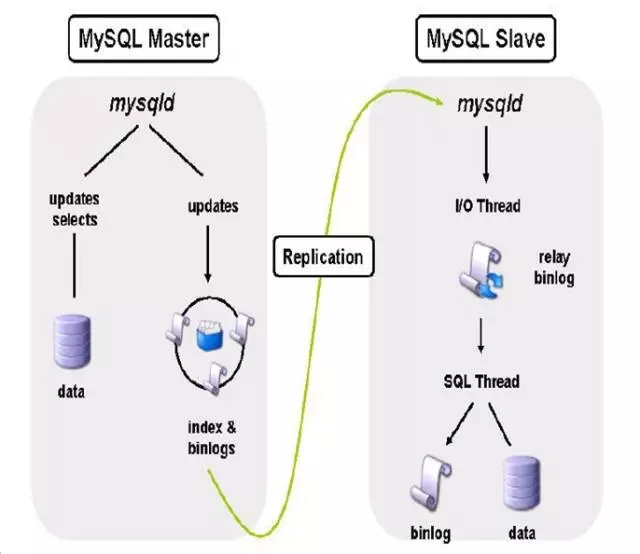
所以延遲的問題能夠解決,后續的擴展就容易多了,MySQL的擴展甚至可以做到指數級的擴展方式,如果允許一些低延時,大量的讀請求就可以逐步分解。所以一主多從的架構方式也是見怪不怪。
值得一提的是MHA的一主多從架構中,如果多個從庫存在延遲,在切換的時候MHA會補齊差異的日志,這是MHA的一大亮點。
而MySQL的級聯復制就更純粹了,和Oracle相比的最大優勢就是一個數據庫可以既是主庫也可以同時是從庫,起到承上啟下的作用。
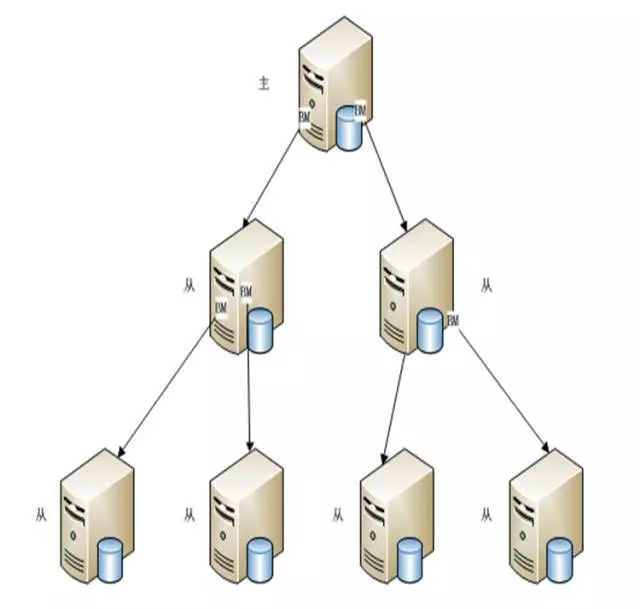
這種擴展方式簡直是酸爽,在一些跨數據中心的場景,允許一定延遲的情況下還是有用武之地。比如你需要從北美讀數據,可以從北美推送數據庫到香港或者新加坡,再推送到北京。有了這種方式就很容易擴展。當然在實時交易中還是存在一些瓶頸和缺陷。
展望和后續補充
如果拋開具體的數據庫,整體來說數據量和業務量到達一定程度都會碰到一系列的問題。這些都是痛點也是難點,常見的問題如下:
- 單臺服務器無法承載已有的壓力
- 數據庫單表容量越來越大
- 大量的讀寫需求無法平衡
- 資源如果擴容,應用改動較大
- 資源的負載沒法拆分,或者不易拆分
這時就需要擴展,就需要匹配的解決方案,比如中間件的方案,有的解決了一些通用的問題,有些側重于某一方面。比如需要考慮sharding來分片,讀寫分離來做分擔讀寫壓力,前端海量訪問可以通過大量的水平擴展來分擔。
從這個角度來說,MySQL是以架構和規模取勝,通過業務拆分和架構拆分能夠實現線性擴展。而Oracle的擴展性雖然沒有那么好,但從架構和業務層面來說也能做,這個后續有機會再細細說一說,可以擬一篇分布式方面的文章。
小結
簡單總結一下,高可用的方案選擇很多,各家有各家的需求,能定制的定制,能開源的開源。大道至簡,只要滿足了需求,系統穩定不背鍋,那就是最好的方案。