如何分析博客中最流行的編程語言
摘要:這篇文章我們將對一些各種各樣的博客的流行度相對于他們在谷歌上的排名進行一個分析。所有代碼可以在 github 上找到。
想法來源
我一直在想,各種各樣的博客每天到底都有多少頁面瀏覽量,以及在博客閱讀受眾中***的是什么編程語言。我也很感興趣的是,它們在谷歌的網站排名是否與它們的受歡迎程度直接相關。
為了回答這些問題,我決定做一個 Scrapy 項目,它將收集一些數據,然后對所獲得的信息執行特定的數據分析和數據可視化。
***部分:Scrapy
我們將使用 Scrapy 為我們的工作,因為它為抓取和對該請求處理后的反饋進行管理提供了干凈和健壯的框架。我們還將使用 Splash 來解析需要處理的 Javascript 頁面。Splash 使用自己的 Web 服務器充當代理,并處理 Javascript 響應,然后再將其重定向到我們的爬蟲進程。
- 我這里沒有描述 Scrapy 的設置,也沒有描述 Splash 的集成。你可以在這里找到 Scrapy 的示例,而這里還有 Scrapy+Splash 指南。
獲得相關的博客
***步顯然是獲取數據。我們需要關于編程博客的谷歌搜索結果。你看,如果我們開始僅僅用谷歌自己來搜索,比如說查詢 “Python”,除了博客,我們還會得到很多其它的東西。我們需要的是做一些過濾,只留下特定的博客。幸運的是,有一種叫做 Google 自定義搜索引擎(CSE)的東西,它能做到這一點。還有一個網站 www.blogsearchengine.org,它正好可以滿足我們需要,它會將用戶請求委托給 CSE,這樣我們就可以查看它的查詢并重復利用它們。
所以,我們要做的是到 www.blogsearchengine.org 網站,搜索 “python”,并在一側打開 Chrome 開發者工具中的網絡標簽頁。這截圖是我們將要看到的:

突出顯示的是 blogsearchengine 向谷歌委派的一個搜索請求,所以我們將復制它,并在我們的 scraper 中使用。
這個博客抓取爬行器類會是如下這樣的:
- class BlogsSpider(scrapy.Spider):
- name = 'blogs'
- allowed_domains = ['cse.google.com']
- def __init__(self, queries):
- super(BlogsSpider, self).__init__()
- self.queries = queries
與典型的 Scrapy 爬蟲不同,我們的方法覆蓋了 __init__ 方法,它接受額外的參數 queries,它指定了我們想要執行的查詢列表。
現在,最重要的部分是構建和執行這個實際的查詢。這個過程放在 start_requests 爬蟲的方法里面執行,我們愉快地覆蓋它:
- def start_requests(self):
- params_dict = {
- 'cx': ['partner-pub-9634067433254658:5laonibews6'],
- 'cof': ['FORID:10'],
- 'ie': ['ISO-8859-1'],
- 'q': ['query'],
- 'sa.x': ['0'],
- 'sa.y': ['0'],
- 'sa': ['Search'],
- 'ad': ['n9'],
- 'num': ['10'],
- 'rurl': [
- 'http://www.blogsearchengine.org/search.html?cx=partner-pub'
- '-9634067433254658%3A5laonibews6&cof=FORID%3A10&ie=ISO-8859-1&'
- 'q=query&sa.x=0&sa.y=0&sa=Search'
- ],
- 'siteurl': ['http://www.blogsearchengine.org/']
- }
- params = urllib.parse.urlencode(params_dict, doseq=True)
- url_template = urllib.parse.urlunparse(
- ['https', self.allowed_domains[0], '/cse',
- '', params, 'gsc.tab=0&gsc.q=query&gsc.page=page_num'])
- for query in self.queries:
- for page_num in range(1, 11):
- url = url_template.replace('query', urllib.parse.quote(query))
- url = url.replace('page_num', str(page_num))
- yield SplashRequest(url, self.parse, endpoint='render.html',
- args={'wait': 0.5})
在這里你可以看到相當復雜的 params_dict 字典,它控制所有我們之前找到的 Google CSE URL 的參數。然后我們準備好 url_template 里的一切,除了已經填好的查詢和頁碼。我們對每種編程語言請求 10 頁,每一頁包含 10 個鏈接,所以是每種語言有 100 個不同的博客用來分析。
在 42-43 行,我使用一個特殊的類 SplashRequest 來代替 Scrapy 自帶的 Request 類。它封裝了 Splash 庫內部的重定向邏輯,所以我們無需為此擔心。十分整潔。
***,這是解析程序:
- def parse(self, response):
- urls = response.css('div.gs-title.gsc-table-cell-thumbnail') \
- .xpath('./a/@href').extract()
- gsc_fragment = urllib.parse.urlparse(response.url).fragment
- fragment_dict = urllib.parse.parse_qs(gsc_fragment)
- page_num = int(fragment_dict['gsc.page'][0])
- query = fragment_dict['gsc.q'][0]
- page_size = len(urls)
- for i, url in enumerate(urls):
- parsed_url = urllib.parse.urlparse(url)
- rank = (page_num - 1) * page_size + i
- yield {
- 'rank': rank,
- 'url': parsed_url.netloc,
- 'query': query
- }
所有 Scraper 的核心和靈魂就是解析器邏輯。可以有多種方法來理解響應頁面的結構并構建 XPath 查詢字符串。您可以使用 Scrapy shell 嘗試并隨時調整你的 XPath 查詢,而不用運行爬蟲。不過我更喜歡可視化的方法。它需要再次用到谷歌 Chrome 開發人員控制臺。只需右鍵單擊你想要用在你的爬蟲里的元素,然后按下 Inspect。它將打開控制臺,并定位到你指定位置的 HTML 源代碼。在本例中,我們想要得到實際的搜索結果鏈接。他們的源代碼定位是這樣的:

在查看這個元素的描述后我們看到所找的
尋找流量數據
下一個任務是估測每個博客每天得到的頁面瀏覽量。得到這樣的數據有各種方式,有免費的,也有付費的。在快速搜索之后,我決定基于簡單且免費的原因使用網站 www.statshow.com 來做。爬蟲將抓取這個網站,我們在前一步獲得的博客的 URL 將作為這個網站的輸入參數,獲得它們的流量信息。爬蟲的初始化是這樣的:
- class TrafficSpider(scrapy.Spider):
- name = 'traffic'
- allowed_domains = ['www.statshow.com']
- def __init__(self, blogs_data):
- super(TrafficSpider, self).__init__()
- self.blogs_data = blogs_data
blogs_data 應該是以下格式的詞典列表:{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}。
請求構建函數如下:
- def start_requests(self):
- url_template = urllib.parse.urlunparse(
- ['http', self.allowed_domains[0], '/www/{path}', '', '', ''])
- for blog in self.blogs_data:
- url = url_template.format(path=blog['url'])
- request = SplashRequest(url, endpoint='render.html',
- args={'wait': 0.5}, meta={'blog': blog})
- yield request
它相當的簡單,我們只是把字符串 /www/web-site-url/ 添加到 'www.statshow.com' URL 中。
現在讓我們看一下語法解析器是什么樣子的:
- def parse(self, response):
- site_data = response.xpath('//div[@id="box_1"]/span/text()').extract()
- views_data = list(filter(lambda r: '$' not in r, site_data))
- if views_data:
- blog_data = response.meta.get('blog')
- traffic_data = {
- 'daily_page_views': int(views_data[0].translate({ord(','): None})),
- 'daily_visitors': int(views_data[1].translate({ord(','): None}))
- }
- blog_data.update(traffic_data)
- yield blog_data
與博客解析程序類似,我們只是通過 StatShow 示例的返回頁面,然后找到包含每日頁面瀏覽量和每日訪問者的元素。這兩個參數都確定了網站的受歡迎程度,對于我們的分析只需要使用頁面瀏覽量即可 。
第二部分:分析
這部分是分析我們搜集到的所有數據。然后,我們用名為 Bokeh 的庫來可視化準備好的數據集。我在這里沒有給出運行器和可視化的代碼,但是它可以在 GitHub repo 中找到,包括你在這篇文章中看到的和其他一切東西。
- 最初的結果集含有少許偏離過大的數據,(如 google.com、linkedin.com、Oracle.com 等)。它們顯然不應該被考慮。即使其中有些有博客,它們也不是針對特定語言的。這就是為什么我們基于這個 StackOverflow 回答 中所建議的方法來過濾異常值。
語言流行度比較
首先,讓我們對所有的語言進行直接的比較,看看哪一種語言在前 100 個博客中有最多的瀏覽量。
這是能進行這個任務的函數:
- def get_languages_popularity(data):
- query_sorted_data = sorted(data, key=itemgetter('query'))
- result = {'languages': [], 'views': []}
- popularity = []
- for k, group in groupby(query_sorted_data, key=itemgetter('query')):
- group = list(group)
- daily_page_views = map(lambda r: int(r['daily_page_views']), group)
- total_page_views = sum(daily_page_views)
- popularity.append((group[0]['query'], total_page_views))
- sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
- languages, views = zip(*sorted_popularity)
- result['languages'] = languages
- result['views'] = views
- return result
在這里,我們首先按語言(詞典中的關鍵字“query”)來分組我們的數據,然后使用 python 的 groupby 函數,這是一個從 SQL 中借來的奇妙函數,從我們的數據列表中生成一組條目,每個條目都表示一些編程語言。然后,在第 14 行我們計算每一種語言的總頁面瀏覽量,然后添加 ('Language', rank) 形式的元組到 popularity 列表中。在循環之后,我們根據總瀏覽量對流行度數據進行排序,并將這些元組展開到兩個單獨的列表中,然后在 result 變量中返回它們。
- 最初的數據集有很大的偏差。我檢查了到底發生了什么,并意識到如果我在 blogsearchengine.org 上查詢“C”,我就會得到很多無關的鏈接,其中包含了 “C” 的字母。因此,我必須將 C 排除在分析之外。這種情況幾乎不會在 “R” 和其他類似 C 的名稱中出現:“C++”、“C”。
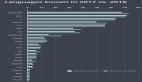
因此,如果我們將 C 從考慮中移除并查看其他語言,我們可以看到如下圖:

評估結論:Java 每天有超過 400 萬的瀏覽量,PHP 和 Go 有超過 200 萬,R 和 JavaScript 也突破了百萬大關。
每日網頁瀏覽量與谷歌排名
現在讓我們來看看每日訪問量和谷歌的博客排名之間的聯系。從邏輯上來說,不那么受歡迎的博客應該排名靠后,但這并沒那么簡單,因為其他因素也會影響排名,例如,如果在人氣較低的博客上的文章更新一些,那么它很可能會首先出現。
數據準備工作以下列方式進行:
- def get_languages_popularity(data):
- query_sorted_data = sorted(data, key=itemgetter('query'))
- result = {'languages': [], 'views': []}
- popularity = []
- for k, group in groupby(query_sorted_data, key=itemgetter('query')):
- group = list(group)
- daily_page_views = map(lambda r: int(r['daily_page_views']), group)
- total_page_views = sum(daily_page_views)
- popularity.append((group[0]['query'], total_page_views))
- sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
- languages, views = zip(*sorted_popularity)
- result['languages'] = languages
- result['views'] = views
- return result
該函數接受爬取到的數據和需要考慮的語言列表。我們對這些數據以語言的流行程度進行排序。后來,在類似的語言分組循環中,我們構建了 (rank, views_number) 元組(從 1 開始的排名)被轉換為 2 個單獨的列表。然后將這一對列表寫入到生成的字典中。
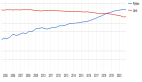
前 8 位 GitHub 語言(除了 C)是如下這些:


評估結論:我們看到,所有圖的 PCC (皮爾遜相關系數)都遠離 1/-1,這表示每日瀏覽量與排名之間缺乏相關性。值得注意的是,在大多數圖表(8 個中的 7 個)中,相關性是負的,這意味著排名的降低會導致瀏覽量的減少。
結論
因此,根據我們的分析,Java 是目前***的編程語言,其次是 PHP、Go、R 和 JavaScript。在日常瀏覽量和谷歌排名上,排名前 8 的語言都沒有很強的相關性,所以即使你剛剛開始寫博客,你也可以在搜索結果中獲得很高的評價。不過,成為熱門博客究竟需要什么,可以留待下次討論。
這些結果是相當有偏差的,如果沒有更多的分析,就不能過分的考慮這些結果。首先,在較長的一段時間內收集更多的流量信息,然后分析每日瀏覽量和排名的平均值(中值)值是一個好主意。也許我以后還會再回來討論這個。