













Apache Hadoop 3.0.0 GA版正式發布,可以部署到線上
日前Apache Hadoop 3.0.0 GA 版本正式發布,這意味著我們就可以正式在線上使用 Hadoop 3.0.0 了!這個版本是 Apache Hadoop 3.0.0 的***個穩定版本,有很多重大的改進,比如支持 EC、支持多于2個的NameNodes、Intra-datanode均衡器等等。下面是關于 Apache Hadoop 3.0.0 GA 的正式介紹。
Java最低版本要求從Java7 更改成Java8
所有的Hadoop JARs都是針對Java 8 編譯的。仍在使用Java 7 或更低版本的用戶必須升級至Java 8。
HDFS支持糾刪碼(Erasure Coding)
與副本相比糾刪碼是一種更節省空間的數據持久化存儲方法。標準編碼(比如Reed-Solomon(10,4))會有
1.4 倍的空間開銷;然而HDFS副本則會有3倍的空間開銷。因為糾刪碼額外開銷主要是在重建和執行遠程讀,它傳統用于存儲冷數據,即不經常訪問的數據。當部署這個新特性時用戶應該考慮糾刪碼的網絡和CPU 開銷。更多關于HDFS的糾刪碼可以參見http://hadoop.apache.org/docs/r3.0.0-beta1/hadoop-project-dist/hadoop-hdfs/HDFSErasureCoding.html 。
YARN Timeline Service v.2
本版本引入了Yarn時間抽服務v.2,主要用于解決2大挑戰:改善時間軸服務的可伸縮性和可靠性,通過引入流和聚合增強可用性。
YARN Timeline Service v.2 alpha 1可以讓用戶和開發者測試以及反饋,以便使得它可以替換現在的Timeline Service v.1.x。請在測試環境中使用。更多關于YARN Timeline Service v.2的知識請參見http://hadoop.apache.org/docs/r3.0.0-beta1/hadoop-yarn/hadoop-yarn-site/TimelineServiceV2.html
Shell腳本重寫
Hadoop的Shell腳本被重寫解決了之前很多長期存在的bug,并且引入了一些新的特性。絕大部分都保持兼容性,不過仍有些變化可能使得現有的安裝不能正常運行。不兼容的改變可以參見HADOOP-9902。更多內容請參見Unix Shell Guide文檔。即使你是資深用戶,也建議看下這個文檔,因為其描述了許多新的功能,特別是與可擴展性有關的功能。
Shaded client jars
在 Hadoop 2.x 版本,hadoop-client Maven artifact將 Hadoop 所有的依賴都加到 Hadoop 應用程序的環境變量中,這樣會可能會導致應用程序依賴的類和 Hadoop 依賴的類有沖突。這個問題在 HADOOP-11804 得到了解決。
支持 Opportunistic Containers 和分布式調度
Opportunistic Container引入新 Opportunistic 類型的 Container 后,這種 Container 可以利用節點上已分配但未真正使用的資源。原有 Container 類型定義為 Guaranteed 類型。相對于 Guaranteed 類型Container, Opportunistic 類型的Container優先級更低。
MapReduce任務級本地優化
MapReduce添加了Map輸出collector的本地實現。對于shuffle密集型的作業來說,這將會有30%以上的性能提升。更多內容請參見 MAPREDUCE-2841
支持多于2個的NameNodes
最初的HDFS NameNode high-availability實現僅僅提供了一個active NameNode和一個Standby NameNode;并且通過將編輯日志復制到三個JournalNodes上,這種架構能夠容忍系統中的任何一個節點的失敗。然而,一些部署需要更高的容錯度。我們可以通過這個新特性來實現,其允許用戶運行多個Standby NameNode。比如通過配置三個NameNode和五個JournalNodes,這個系統可以容忍2個節點的故障,而不是僅僅一個節點。HDFS high-availability文檔已經對這些信息進行了更新,我們可以閱讀這篇文檔了解如何配置多于2個NameNodes。
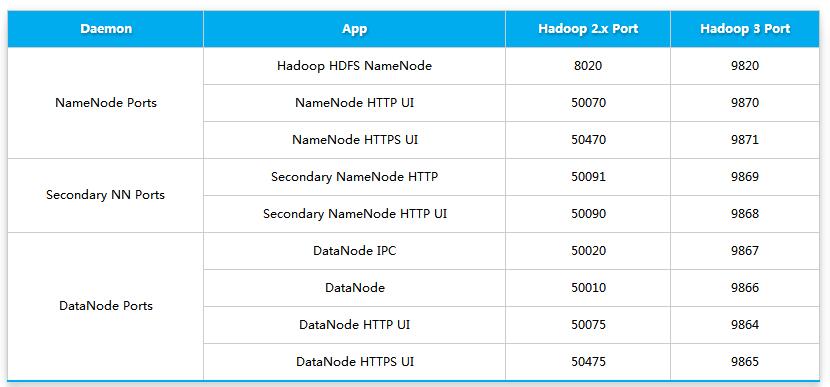
多個服務的默認端口被改變
在此之前,多個Hadoop服務的默認端口都屬于Linux的臨時端口范圍(32768-61000)。這就意味著我們的服務在啟動的時候可能因為和其他應用程序產生端口沖突而無法啟動。現在這些可能會產生沖突的端口已經不再屬于臨時端口的范圍,這些端口的改變會影響NameNode, Secondary NameNode, DataNode以及KMS。與此同時,官方文檔也進行了相應的改變,具體可以參見 HDFS-9427以及HADOOP-12811。下面表格列出了端口變化的情況
支持Microsoft Azure Data Lake filesystem連接器
Hadoop現在支持集成Microsoft Azure Data Lake,并作為替代Hadoop默認的文件系統。
Intra-datanode均衡器
一個DataNode可以管理多個磁盤,正常寫入操作,各磁盤會被均勻填滿。然而,當添加或替換磁盤時可能導致此DataNode內部的磁盤存儲的數據嚴重內斜。這種情況現有的HDFS balancer是無法處理的。這種情況是由新intra-DataNode平衡功能來處理,通過hdfs diskbalancer CLI來調用。更多請參考HDFS Commands Guide
重寫守護進程以及任務的堆內存管理
Hadoop守護進程和MapReduce任務的堆內存管理發生了一系列變化。
- HADOOP-10950:介紹了配置守護集成heap大小的新方法。主機內存大小可以自動調整,HADOOP_HEAPSIZE 已棄用。
- MAPREDUCE-5785:map和reduce task堆大小的配置方法,所需的堆大小不再需要通過任務配置和Java選項實現。已經指定的現有配置不受此更改影響。
- S3Guard:S3A文件系統客戶機的一致性和元數據緩存
HADOOP-13345 里面為 Amazon S3 存儲系統的 S3A 客戶端引入了一個新的可選特性,也就是可以使用 DynamoDB 表作為文件和目錄元數據的快速一致的存儲。
HDFS Router-Based Federation
HDFS Router-Based Federation 添加了一個 RPC路由層,提供了多個 HDFS 命名空間的聯合視圖。與現有 ViewFs 和 HDFS Federation 功能類似,不同之處在于掛載表(mount table)由服務器端(server-side)的路由層維護,而不是客戶端。這簡化了現有 HDFS客戶端 對 federated cluster 的訪問。 詳細請參見:HDFS-10467
基于API來配置 Capacity Scheduler 隊列的配置
OrgQueue 擴展了 capacity scheduler ,通過 REST API 提供了以編程的方式來改變隊列的配置,This enables automation of queue configuration management by administrators in the queue’s administer_queue ACL.。詳細請參見:YARN-5734
YARN Resource Types
YARN 資源模型(YARN resource model)已被推廣為支持用戶自定義的可數資源類型(support user-defined countable resource types),不僅僅支持 CPU 和內存。比如集群管理員可以定義諸如 GPUs、軟件許可證(software licenses)或本地附加存儲器(locally-attached storage)之類的資源。YARN 任務可以根據這些資源的可用性進行調度。














