大數(shù)據(jù)關(guān)鍵技術(shù)分析
古代,人們用牛來(lái)拉重物,當(dāng)一頭牛拉不動(dòng)一根圓木時(shí),他們不曾想過(guò)培育更大更壯的牛。同樣,在面對(duì)計(jì)算能力不足時(shí),我們也應(yīng)嘗試著結(jié)合使用更多的計(jì)算機(jī)系統(tǒng)。
Hadoop就是基于這樣的理念設(shè)計(jì)。Hadoop是一個(gè)由Apache基金會(huì)所開(kāi)發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu),計(jì)算分析處理所涉及的框架,允許多臺(tái)設(shè)備一起工作,充分利用集群的威力進(jìn)行高速運(yùn)算和存儲(chǔ),共同完成一項(xiàng)任務(wù),而對(duì)于用戶來(lái)說(shuō)這些設(shè)備是感知不到了,Hadoop技術(shù)屏蔽了底層的細(xì)節(jié)。
據(jù)關(guān)鍵技術(shù)分析")
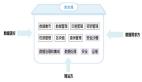
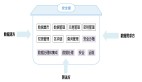
Hadoop***層是HDFS,也就是Hadoop文件系統(tǒng),這個(gè)是分布式文件系統(tǒng),由多臺(tái)設(shè)備提供統(tǒng)一的存儲(chǔ)空間,而用戶感覺(jué)不到多臺(tái)設(shè)備,只看到一個(gè)統(tǒng)一的存儲(chǔ)空間,這也是云存儲(chǔ)技術(shù)的基礎(chǔ)。構(gòu)建于HDFS的Hbase是天然的分布式數(shù)據(jù)庫(kù);MapReduce提供了云計(jì)算框架,它的數(shù)據(jù)來(lái)源也是分布式的,可以是HDFS,也可以是Hbase。
HBase是分布式數(shù)據(jù)產(chǎn)品,多臺(tái)設(shè)備共同提供類似數(shù)據(jù)庫(kù)的服務(wù),但是這種服務(wù)是分布式,由多臺(tái)設(shè)備來(lái)提供的,用戶也完全感覺(jué)不到設(shè)備的存在,只知道有一個(gè)數(shù)據(jù)庫(kù)給他們服務(wù)。這個(gè)也就是大數(shù)據(jù)庫(kù)的基礎(chǔ)。
在HBase之上,有MapReduce服務(wù)框架,也就是并行分析計(jì)算服務(wù)框架,可以支持各種分析應(yīng)用并發(fā)的在多臺(tái)設(shè)備上執(zhí)行,完成一個(gè)共同的任務(wù),原來(lái)1個(gè)人需要10天完成的任務(wù),現(xiàn)在可以10個(gè)人1天完成,大大提升了數(shù)據(jù)分析的效率,這個(gè)也就是分布式計(jì)算的基礎(chǔ)。
Pig、Hive等是數(shù)據(jù)分析的引擎,提供快速的數(shù)據(jù)分析接口和能力。
Hadoop主要有以下幾個(gè)優(yōu)點(diǎn):
一是高可靠性。Hadoop按位存儲(chǔ)和處理數(shù)據(jù)的能力值得人們信賴。
二是高擴(kuò)展性。Hadoop是在可用的計(jì)算機(jī)集簇間分配數(shù)據(jù)并完成計(jì)算任務(wù)的,這些集簇可以方便地?cái)U(kuò)展到數(shù)以千計(jì)的節(jié)點(diǎn)中。
三是高效性。Hadoop能夠在節(jié)點(diǎn)之間動(dòng)態(tài)地移動(dòng)數(shù)據(jù),并保證各個(gè)節(jié)點(diǎn)的動(dòng)態(tài)平衡,因此處理速度非常快。
四是高容錯(cuò)性。Hadoop能夠自動(dòng)保存數(shù)據(jù)的多個(gè)副本,并且能夠自動(dòng)將失敗的任務(wù)重新分配。
五是低成本。與一體機(jī)、商用數(shù)據(jù)倉(cāng)庫(kù)以及QlikView、Yonghong Z-Suite等數(shù)據(jù)集市相比,hadoop是開(kāi)源的,項(xiàng)目的軟件成本因此會(huì)大大降低。