老曹的文章:全棧必備 你需要了解的Python編程基礎
據說:
2019年, 浙江信息技術高考可以考python了;
2018年, Python 進入了小學生的教材;
2018年, 全國計算機等級考試,可以考python 了;
據外媒報道,微軟正考慮添加 Python 為官方的一種 Excel 腳本語言
……
Python作為一種編程語言,被稱為“膠水語言”,更被擁躉們譽為“最美麗”的編程語言,從云端到客戶端,再到物聯網終端,無所不在,同時還是人工智能優選的編程語言。
因此,從全棧的角度看, Python 是一門必備的語言,因為它是除了驅動和操作系統外,其他都可以做好。
不積跬步無以至千里,不積小流無以成江海。—— 荀子《勸學》
語法
Python使用空格或制表符縮進的方式分隔代碼,Python 2 僅有31個保留字,而且沒有分號、begin、end等標記。

可以組織成打油詩, 更方便記憶:
- Global is class,def not pass。
- if eilf else, del as break。
- raise in while,import from yield,
- try for print,return and assert。
- exec except with lambda,
- finally or continue……
python中沒有提供定義常量的保留字,可以自己定義一個常量類來實現常量的功能。python中有3種表示字符串類型的方式,即單引號、雙引號、三引號。單引號和雙引號的作用是相同的,python程序員更喜歡用單引號,C/Java程序員則習慣使用雙引號表示字符串。三引號中可以輸入單引號、雙引號或換行等字符。python不支持自增運算符和自減運算符,其他運算符和表達式都是類似的,尤其是分支判斷和循環。
Python的文件類型分為3種,即源代碼、字節代碼和優化代碼。這些都可以直接運行,不需要進行預編譯或連接。
數據類型
Python中的基本數據類型有布爾類型,整數,浮點數和字符串等。
Python 中的數據結構主要有元組(tuple),列表(list)和字典(dictionary)。元組、列表和字符串都屬于序列,是具有索引和切片能力的集合。
元組初始化后不可修改,是寫保護的。元組往往代表一行數據,而元組中的元素代表不同的數據項,可以把元組看做不可修改的數組。
- tuple_name=(“you”,”me”,”him”,”her”)
列表可轉換為元組,是傳統意義上的數組,可以實現添加、刪除和查找操作,元素的值可以被修改。
- list_name=[“you”,”me”,”him”,”her”]
字典是鍵值對,相對于哈希表。
- dict_name={“y”:”you”, “m”:”me”, “hi”:”him”, “he”:”her”}
列表推導(List Comprehensions)是構建列表的快捷方式, 可讀性較好且效率更高. 運用列表生成式,可以快速生成list,例如 得到當前目錄下的所有目錄和文件:
- >>> import os
- >>> [d for d in os.listdir('.')]
也可以通過一個list推導出另一個list,代碼簡潔,例如 將一個列表中的元素都變成小寫:
- >>> L = ['Hello', 'World', 'IBM', 'Apple']
- >>> [s.lower() for s in L]
通過這些基本類型,可以組成更有針對性需求的數據結構,例如字典嵌套形成的樹等, 針對更復雜的數據結構, Python 中提供了大量的庫。
類與繼承
python用class來定義一個類,當所需的數據結構不能用簡單類型來表示時,就需要定義類,然后利用定義的類創建對象。當一個對象被創建后,包含了三方面的特性,即對象的句柄、屬性和方法。創建對象的方法:
- abel = Abel()
- Abel.do()
類的方法同樣分為公有方法和私有方法。私有函數不能被該類之外的函數調用,私有的方法也不能被外部的類或函數調用。python使用函數”staticmethod()“或”@ staticmethod“的方法把普通的函數轉換為靜態方法,相當于全局函數。python的構造函數名為init,析構函數名為del。繼承的使用方法:
- class AbelApp(abel):
- def …
Python 中的變量名解析遵循LEGB原則,本地作用域(Local),上一層結構中的def或Lambda的本地作用域(Enclosing),全局作用域(Global),內置作用域(Builtin),按順序查找。
和變量解析不同,Python 會按照特定的順序遍歷繼承樹,就是方法解析順序(Method Resolution Order,MRO)。類都有一個名為mro 的屬性,值是一個元組,按照方法解析順序列出各個超類,從當前類一直向上,直到 object 類。
Python 中有一種特殊的類是元類(metaclass)。元類是由“type”衍生而出,所以父類需要傳入type,元類的操作都在 new中完成。通過元類創建的類,第一個參數是父類,第二個參數是metaclass。
包與模塊
python程序由包(package)、模塊(module)和函數組成。包是由一系列模塊組成的集合。包必須含有一個init.py文件,它用于標識當前文件夾是一個包。
模塊是處理某一類問題的函數和類的集合。模塊把一組相關的函數或代碼組織到一個文件中,一個文件即是一個模塊。模塊由代碼、函數和類組成。導入模塊使用import語句,不過模塊不限于此,還可以被 import 語句導入的模塊共有以下四類:
- 使用Python寫的程序( .py文件)
- C或C++擴展(已編譯為共享庫或DLL文件)
- 包(包含多個模塊)
- 內建模塊(使用C編寫并已鏈接到Python解釋器內)
Python 提供內建函數__import__動態加載 module,import 本質上是調用 __import__加載 module 的, 函數原型如下:
- __import__(name, globals={}, locals={}, fromlist=[], level=-1)
例如,加載名為 abel的目錄下所有模塊:
- def loadModules():
- res = {}
- import os
- lst = os.listdir("abel")
- dir = []
- for d in lst:
- s = os.path.abspath("abel") + os.sep + d
- if os.path.isdir(s) and os.path.exists(s + os.sep + "__init__.py"):
- dir.append(d)
- # load the modules
- for d in dir:
- res[d] = __import__("abel." + d, fromlist = ["*"])
- return res
需要注意的是,如果輸入的參數如果帶有 “.”,采用 __import__直接導入 module 容易造成意想不到的結果。 OpenStack 的 oslo.utils 封裝了 __import__,支持動態導入 class, object 等。
命名規范
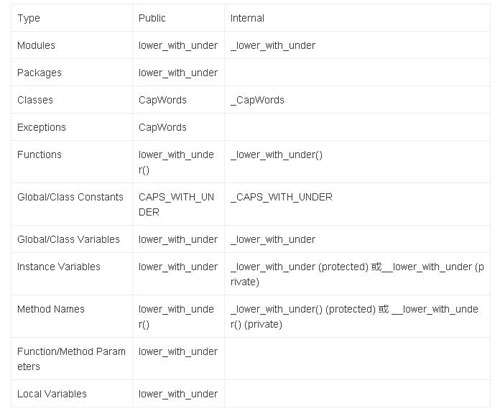
Python 中的naming convention 以及 coding standard 有很多好的實踐,例如Google 的Python 編程規范等。 就命名規范而言, 可以參見Python之父Guido推薦的規范,見下表:
迭代器
迭代是數據處理的基礎, 采用一種惰性獲取數據的方式, 即按需一次獲取一個數據,這就是迭代器模式. 迭代器是一個帶狀態的對象,檢查一個對象 a 是否是迭代對象, 最準確的方法是調用 iter(a) , 如果不可迭代, 則拋出 TypeError 異常.
標準的迭代器接口有兩個方法:
- __next__: 返回下一個可用元素, 如沒有, 拋出StopIteration 異常.
- __iter__: 返回self , 以便在應該使用可迭代對象的地方使用迭代器.
可迭代對象一定不能是自身的迭代器. 也就是說, 可迭代對象必須實現 __iter__方法, 但不能實現 __next__ 方法.
實現一個斐波那契數列的迭代器例子如下:
- class Fibonacci:
- def __init__(self):
- self.prevous = 0
- self.current = 1
- def __iter__(self):
- return self
- def __next__(self):
- value = self.current
- self.current = self.prevous + self.current
- self.prevous = value
- return value
迭代器就是實現了工廠模式的對象,有很多關于迭代器的例子,比如itertools函數返回的都是迭代器對象。
生成器
生成器算得上是Python中最吸引人的特性之一,生成器其實是一種特殊的迭代器,但不需要寫__iter__()和__next__()方法了,只需要一個yiled關鍵字即可。python中的 yield 關鍵字, 用于構建生成器(generator), 其作用與迭代器一樣. 還以斐波那契數列為例:
- def Fibonacci():
- prevous, current = 0, 1
- while True:
- yield current
- prevous, current = current, current + prevous
所有的生成器都是迭代器, 都實現了迭代器的接口。 一般地,只要python函數的定義體中使用了 yield 關鍵字, 該函數就是生成器函數. 調用生成器函數時, 會返回一個生成器對象。也就是說, 生成器函數是生成器工廠。
生成器函數會創建一個生成器對象, 包裝生成器函數的定義體. 把生成器傳給 next(…) 函數時, 生成器函數會向前執行函數體中下一個 yield 語句, 返回產出的值, 并在函數定義體的當前位置暫停.
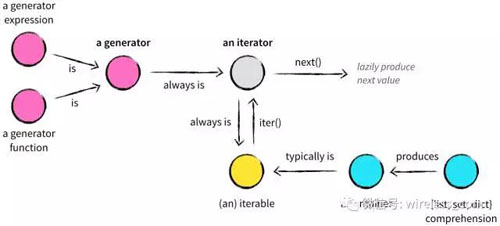
(圖片來自http://nvie.com/posts/iterators-vs-generators/)
需要注意的是, 在協程中, yield 通常出現在表達式的右邊(data = yield), 可以產出值, 也可以不產出(如果yield后面沒有表達式, 那么會出None)。 協程可能會從調用方接收數據, 調用方把數據提供給協程使用 通過的是 .send(data) 方法. 而不是 next(…) . 通常, 調用方會把值推送給協程.
生成器調用方是一直獲取數據, 而協程調用方可以向它傳入數據, 協程也不一定要產出數據。不管數據如何流動, yield 都是一種流程控制工具, 使用它可以實現寫作式多任務即,協程可以把控制器讓步給中心調度程序, 從而激活其他的協程.
描述符
描述符是一種創建托管屬性的方法,托管屬性還可用于保護屬性不受修改,或自動更新某個依賴屬性的值。描述符是一種在多個屬性上重復利用同一個存取邏輯的方式,能劫持那些本應對于self.__dict__的操作。在其他編程語言中,描述符被稱作 setter 和 getter,用于獲得 (Get) 和設置 (Set) 一個私有變量。Python 沒有私有變量的概念,而描述符可以作為一種 Python 的方式來實現與私有變量類似的功能。
靜態方法、類方法、property都是構建描述符的類。創建描述符的方式主要有3種:
1.創建一個類并覆蓋任意一個描述符方法:__set__、__ get__ 和 __delete__。當需要某個描述符跨多個不同的類和屬性的時候,例如類型驗證,則使用該方法,例如:
- class MyNameDescriptor(object):
- def __init__(self):
- self._myname = ''
- def __get__(self, instance, owner):
- return self._myname def __set__(self, instance, myname):
- self._myname = myname.getText() def __delete__(self, instance):
- del self._myname
2.使用屬性類型可以更加簡單、靈活地創建描述符。通過使用 property(),可以輕松地為任意屬性創建可用的描述符。
- class Student(object):
- def __init__(self):
- self._sname = ''
- def fget(self):
- return self._sname def fset(self, value):
- self._sname = value.title() def fdel(self):
- del self._sname
- name = property(fget, fset, fdel, "This is the property.")
3.使用屬性描述符,它結合了屬性類型方法和 Python裝飾器。
- class Student(object):
- def __init__(self):
- self._sname = ''
- @property
- def name(self):
- return self._sname @name.setter
- def name(self, value):
- self._sname = value.title() @name.deleter
- def name(self):
- del self._sname
另外,還可以在運行時動態創建描述符。 描述符有很多經典的應用,例如Protobuf。
裝飾器
裝飾器(Decorator)是可調用的對象, 其參數是另一個函數(被裝飾的函數). 裝飾器可能會處理被裝飾的函數, 然后把它返回, 或者將其替換成另一個函數或可調用對象.實際上裝飾器就是一個高階函數,它接收一個函數作為參數,然后返回一個新函數。
裝飾器有兩大特征:
- 把被裝飾的函數替換成其他函數
- 裝飾器在加載模塊時立即執行
python內置了三個用于裝飾方法的函數: property、classmethod 和 staticmethod. 當裝飾器不關心被裝飾函數的參數,或是被裝飾函數的參數多種多樣的時候,可變參數非常適合使用。
如果一個函數被多個裝飾器修飾,其實應該是該函數先被最里面的裝飾器修飾,變成另一個函數后,再次被裝飾器修飾。例如:
- def second(func):
- print "running 2nd decorator"
- def wrapper():
- func()
- return wrapper
- def fisrt(func):
- print "running 1st decorator"
- def wrapper():
- func()
- return wrapper
- @second
- @first
- def myfunction():
- print "running myfunction"
就擴展功能而言,裝飾器模式比子類化更加靈活。
在設計模式中,具體的裝飾器實例要包裝具體組件的實例,即裝飾器和所裝飾的組件接口一致,對使用該組件的客戶端透明,并將客戶端的請求轉發給該組件,并且可能在轉發前后執行一些額外的操作,透明性使得可以遞歸嵌套多個裝飾器,從而可以添加任意多個功能。裝飾器模式和Python裝飾器之間并不是一對一的等價關系,Python裝飾器函數更為強大,不僅僅可以實現裝飾器模式。
Lambda
Python 不是純萃的函數式編程語言,但本身提供了一些函數式編程的特性,像 map、reduce、filter等都支持函數作為參數,lambda 函數函數則是函數式編程中的翹楚。
Lambda 函數又稱匿名函數,在某種意義上,return語句隱含在lambda中。和其他很多語言相比,Python 的 lambda 限制很多,最嚴重的是它只能由一條表達式組成。lambda規范必須包含只有一個表達式,表達式必須返回一個值,由lambda創建一個匿名函數隱式地返回表達式的返回值。
在PySpark 中經常會用到使用Lambda 的操作,例如:
li = [1, 2, 3, 4, 5]
### 列表中國年的每個元素加5
map(lambda x: x+5, li)
### 返回其中的偶數
filter(lambda x: x % 2 == 0, li) # [2, 4]
### 返回所有元素的乘積
reduce(lambda x, y: x * y, li)
lambda 可以接收任意多個參數 (包括可選參數) 并且返回單個表達式的值。
本質上,Lambda 函數是一個只與輸入參數有關的抽象代碼樹片段。在很多語言里,lambda 函數的調用會被套上一層接口,還會形成閉包,在 lambda 函數構造的同時就可以完成,之后 lambda 函數內部就是完全靜態的。而一般的函數還要加上存儲局部變量的區域,對外部環境的操作,以及命名,大部分語言強制了一般函數必須與名字綁定。
線程
python是支持多線程的, python的線程就是C語言的一個pthread,并通過操作系統調度算法進行調度。 python 的thread模塊是輕量級的,而threading模塊是對thread做了一些封裝,方便使用。threading 經常和Queue結合使用,Queue模塊中提供了同步的、線程安全的隊列類,包括FIFO隊列,LIFO隊列,和優先級隊列等。這些隊列都實現了鎖,能夠在多線程中直接使用,可以使用隊列來實現線程間的同步。
運行線程(線程中包含name屬性)的兩種常用方式如下:
- 在構造函數中傳入用于線程運行的函數
- 在子類中重寫threading.Thread基類中run()方法(只需重寫init()和run()方法)
實現一個守護線程的簡單例子如下:
- class MyThread(threading.Thread):
- def run(self):
- time.sleep(30)
- print 'thread %s finished.' % self.name
- def MyDaemons():
- print 'start thread:'
- for i in range(5):
- t = MyThread()
- t.setDaemon(1)
- t.start()
- print 'end thread.'
- if __name__ == '__main__':
- MyDaemons()
為了避免線程不同步造成數據不同步,可以對資源進行加鎖,也就是訪問資源的線程需要獲得鎖,才能訪問。threading 模塊中提供了一個 Lock 功能。從Python3.X開始,標準庫為提供了concurrent.futures模塊,其中的ThreadPoolExecutor和ProcessPoolExecutor兩個類,實現了對threading和multiprocessing的進一步抽象,對編寫線程池提供了直接支持。
線程在python 被詬病的是,由于GIL的機制致使多線程不能利用機器多核的特性。其實,GIL并不是Python的特性,只是在實現Python解析器(CPython)的時侯所引入的。盡管Python完全支持多線程編程, 但解釋器的C語言實現部分在完全并行執行時并不是線程安全的,解釋器被一個全局鎖即GIL保護著,它確保任何時候都只有一個Python線程執行。
在多線程環境中,Python 虛擬機按以下方式執行:
設置GIL
切換到一個線程去執行
運行指定的字節碼指令集合
線程主動讓出控制
把線程設置完睡眠狀態
解鎖GIL
再次重復以上步驟
因此,Python的多線程在多核CPU上,只對于IO密集型計算產生正面效果;而當有至少有一個CPU密集型線程存在,那么多線程效率會由于GIL而大幅下降。
GC
Python 中的GC為可配置的垃圾回收器提供了一個接口。通過它可以禁用回收器、調整回收頻率以及設置debug選項,也為用戶能夠查看那些無法回收的對象。
需要了解GC 的兩個重要函數是gc.collect() 和 gc.set_threshold()。
gc.collect([generation])觸發回收行為,返回unreachable object的數量。generation可選參數,用于指定回收第幾代垃圾回收,由此也可看出python使用的是分代垃圾回收。如果不提供參數,表示對整個堆進行回收,即Full GC。
gc.set_threshold(threshold0[,threshold1[,threshold2)設置不同代的回收頻率,GC會把生命周期不同的對象分別放到3種代去管理回收,generation 0即傳說中的年輕代,generation 1為老年代等。
一般地,通過比較上次回收之后,比較分配的資源數和釋放的資源數來決定是否啟動回收,比如,當分配的資源減去釋放的資源數超過閾值0時,回收年輕代的對象。相應的,可以通過gc.get_referents(*objs)得到對objs任一對象引用的所有對象列表。
在要求極限性能的情況下,并確保程序不會造成對象循環引用的時候,可以禁掉垃圾回收器。通過使用gc.disable(),可以禁掉自動垃圾回收器。
1. gc.enable():激活GC
2. gc.disable():禁用GC
3. gc.isenabled():檢查是否激活
同時,可以用gc.set_debug(gc.DEBUG_LEAK)來調試有內存泄露的程序。除此之外,還有DEBUG_SAVEALL,該選項能夠讓被回收的對象保存在gc.garbage里面,以便檢查。
調試
iPDB是一個不錯的工具,通過 pip install ipdb 安裝該工具,然后在你的代碼中import ipdb; ipdb.set_trace(),然后在程序運行時,會獲得一個交互式提示,每次執行程序的一行并且檢查變量。示例代碼如下:
- import ipdb
- ipdb.set_trace()
- ipdb.set_trace(context=5) # will show five lines of code
- # instead of the default three lines
- ipdb.pm()
- ipdb.run('x[0] = 3')
- result = ipdb.runcall(function, arg0, arg1, kwarg='foo')
- result = ipdb.runeval('f(1,2) - 3')
另外,python內置了一個很好的追蹤模塊,當希望搞清其他程序的內部構造的時候,這個功能非常有用。
- python -m trace --trace tracing.py
在一些場合,可以使用pycallgraph來追蹤性能問題,它可以創建函數調用時間和次數的圖表。同時,objgraph對于查找內存泄露非常有用。
當然, 在Python 程序員八榮八恥中談到“以打印日志為榮 , 以單步跟蹤為恥“,日志在很多時候都是調試的不二法門。
性能優化中的雕蟲小技
從時空的角度看,優化通常包含兩方面的內容:減小代碼的體積,提高代碼的運行效率。
一個良好的算法往往對性能起到關鍵作用,因此性能改進的首要點是對算法的改進。在算法的時間復雜度排序上依次是:
O(1) -> O(log n) -> O(n) -> O(n log n) -> O(n^2) -> O(n^3) -> O(n^k) -> O(k^n) -> O(n!)
因此能在時間復雜度上對算法進行一定的改進,對性能的提高不言而喻。
Python 字典中查找操作的復雜度為O(1),而list 實際是個數組,在list 中查找需要遍歷整個表,其復雜度為O(n),因此對成員的讀操作字典要比列表 更快。在需要多數據成員進行頻繁訪問的時候,字典是一個較好的選擇。set的union, intersection,difference操作要比list的迭代要快。因此如果涉及到求list交集,并集或者差的問題可以轉換為set來操作。
對循環的優化所遵循的原則是盡量減少循環過程中的計算量,有多重循環的盡量將內層的計算提到上一層。 在循環的時候使用 xrange 而不是 range,因為 xrange() 在序列中每次調用只產生一個整數元素。而 range() 將直接返回完整的元素列表,用于循環時會有不必要的開銷。另外,while 1 要比 while True 更快。另外,要充分利用Lazy if-evaluation的特性,也就是說如果存在條件表達式if x and y,在 x 為false的情況下y表達式的值將不再計算。
python中的字符串對象是不可改變的,因此對任何字符串的操作如拼接,修改等都將產生一個新的字符串對象,而不是基于原字符串,因此這種持續的copy會在一定程度上影響python的性能。因此,在字符串連接的使用盡量使用join()而不是+,當對字符串處理的時候,首選內置函數,對字符進行格式化比直接串聯讀取要快,盡量使用列表推導和生成器表達式。
優化的前提是需要了解性能瓶頸在什么地方,對于比較復雜的代碼可以借助一些工具來定位,如profile。profile的使用非常簡單,只需要在使用之前進行import即可。對于profile的剖析數據,如果以二進制文件的時候保存結果的時候,可以通過pstats模塊進行文本報表分析,它支持多種形式的報表輸出,是文本界面下一個較為實用的工具。
Python性能優化除了改進算法,選用合適的數據結構之外,還可以將關鍵python代碼部分重寫成C擴展模塊,或者選用在性能上更為優化的解釋器等。
強大的庫
Python最棒的地方之一,就是大量的第三方庫,覆蓋之廣,令人驚嘆。Python 庫有一個缺陷就是默認會進行全局安裝。為了使每個項目都有一個獨立的環境,需要使用工具virtualenv,再用包管理工具pip和virtualenv配合工作。
盡管都可以求助于google或者baidu,但還要不自量力,按照個人認知給出一個列表,如下:
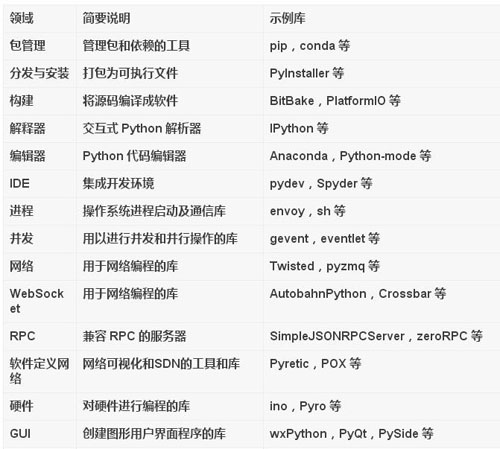
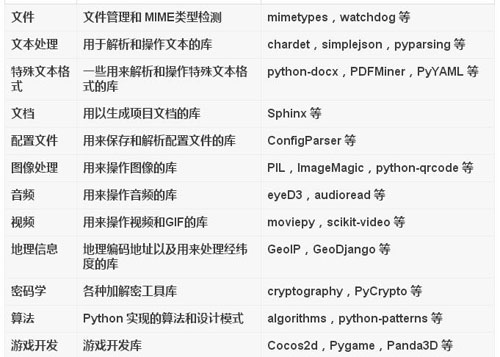
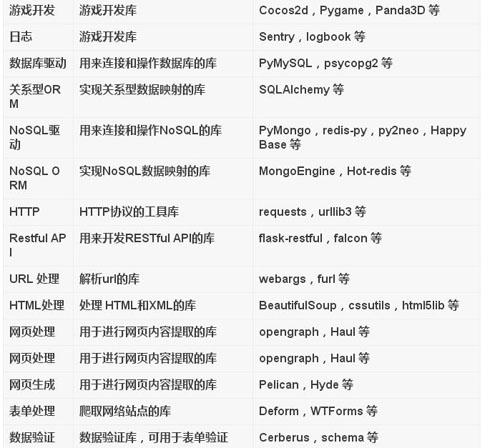
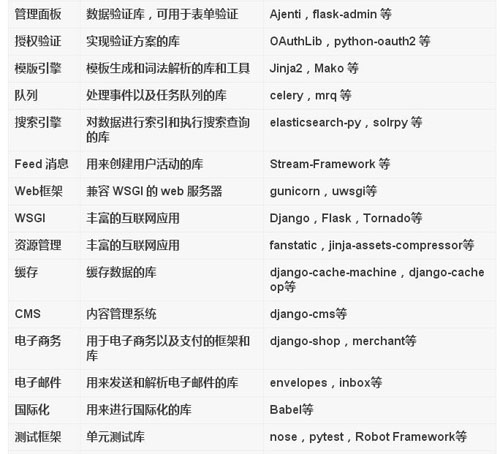
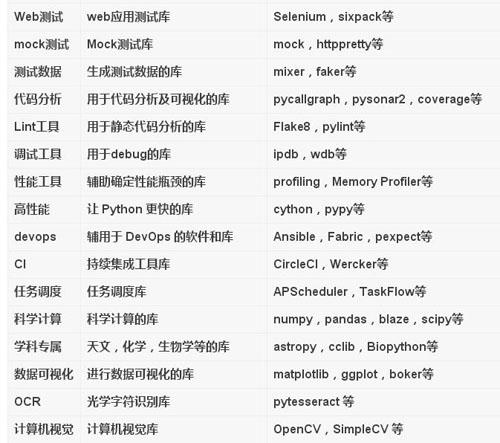
雖然羅列很多,但終歸是滄海一粟,重要的是,這些都是開源的。
不是小結的小結
語法數據,類與繼承;
包與模塊,規范命名;
描述裝飾,迭代生成;
Lambda GC, 并發線程;
調試優化,類庫無窮;
人生苦短,Python 編程。
【本文來自51CTO專欄作者“老曹”的原創文章,作者微信公眾號:喔家ArchiSelf,id:wrieless-com】