從0到1:Python爬蟲知識點梳理
做數據分析和任何一門技術一樣,都應該帶著目標去學習,目標就像一座燈塔,指引你前進,很多人學著學著就學放棄了,很大部分原因是沒有明確目標,所以,一定要明確學習目的,在你準備學爬蟲前,先問問自己為什么要學習爬蟲。有些人是為了一份工作,有些人是為了好玩,也有些人是為了實現某個黑科技功能。不過可以肯定的是,學會了爬蟲能給你的工作提供很多便利。
小白入門必讀
作為零基礎小白,大體上可分為三個階段去實現。
- ***階段是入門,掌握必備基礎知識,比如Python基礎、網絡請求的基本原理等;
- 第二階段是模仿,跟著別人的爬蟲代碼學,弄懂每一行代碼,熟悉主流的爬蟲工具,
- 第三階段是自己動手,到了這個階段你開始有自己的解題思路了,可以獨立設計爬蟲系統。
爬蟲涉及的技術包括但不限于熟練一門編程語言(這里以 Python 為例) HTML 知識、HTTP 協議的基本知識、正則表達式、數據庫知識,常用抓包工具的使用、爬蟲框架的使用、涉及到大規模爬蟲,還需要了解分布式的概念、消息隊列、常用的數據結構和算法、緩存,甚至還包括機器學習的應用,大規模的系統背后都是靠很多技術來支撐的。數據分析、挖掘、甚至是機器學習都離不開數據,而數據很多時候需要通過爬蟲來獲取,因此,即使把爬蟲作為一門專業來學也是有很大前途的。
那么是不是一定要把上面的知識全學完了才可以開始寫爬蟲嗎?當然不是,學習是一輩子的事,只要你會寫 Python 代碼了,就直接上手爬蟲,好比學車,只要能開動了就上路吧,寫代碼可比開車安全多了。
用 Python 寫爬蟲
首先需要會 Python,把基礎語法搞懂,知道怎么使用函數、類、list、dict 中的常用方法就算基本入門。接著你需要了解 HTML,HTML 就是一個文檔樹結構,網上有個 HTML 30分鐘入門教程 https://deerchao.net/tutorials/html/html.htm 夠用了。
關于 HTTP 的知識
爬蟲基本原理就是通過網絡請求從遠程服務器下載數據的過程,而這個網絡請求背后的技術就是基于 HTTP 協議。作為入門爬蟲來說,你需要了解 HTTP協議的基本原理,雖然 HTTP 規范用一本書都寫不完,但深入的內容可以放以后慢慢去看,理論與實踐相結合。
網絡請求框架都是對 HTTP 協議的實現,比如著名的網絡請求庫 Requests 就是一個模擬瀏覽器發送 HTTP 請求的網絡庫。了解 HTTP 協議之后,你就可以專門有針對性的學習和網絡相關的模塊了,比如 Python 自帶有 urllib、urllib2(Python3中的urllib),httplib,Cookie等內容,當然你可以直接跳過這些,直接學習 Requests 怎么用,前提是你熟悉了 HTTP協議的基本內容,數據爬下來,大部分情況是 HTML 文本,也有少數是基于 XML 格式或者 Json 格式的數據,要想正確處理這些數據,你要熟悉每種數據類型的解決方案,比如 JSON 數據可以直接使用 Python自帶的模塊 json,對于 HTML 數據,可以使用 BeautifulSoup、lxml 等庫去處理,對于 xml 數據,除了可以使用 untangle、xmltodict 等第三方庫。
爬蟲工具
爬蟲工具里面,學會使用 Chrome 或者 FireFox 瀏覽器去審查元素,跟蹤請求信息等等,現在大部分網站有配有APP和手機瀏覽器訪問的地址,優先使用這些接口,相對更容易。還有 Fiddler 等代理工具的使用。
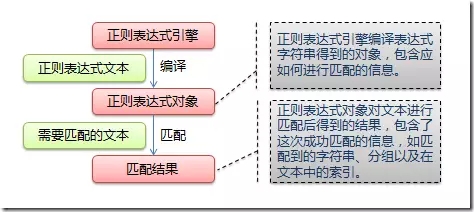
入門爬蟲,學習正則表達式并不是必須的,你可以在你真正需要的時候再去學,比如你把數據爬取回來后,需要對數據進行清洗,當你發現使用常規的字符串操作方法根本沒法處理時,這時你可以嘗試了解一下正則表達式,往往它能起到事半功倍的效果。Python 的 re 模塊可用來處理正則表達式。這里也推薦一個教程:Python正則表達式指南https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
數據清洗
數據清洗完最終要進行持久化存儲,你可以用文件存儲,比如CSV文件,也可以用數據庫存儲,簡單的用 SQLite,專業點用 MySQL,或者是分布式的文檔數據庫 MongoDB,這些數據庫對Python都非常友好,有現成的庫支持,你要做的就是熟悉這些 API 怎么使用。
進階之路
從數據的抓取到清洗再到存儲的基本流程都走完了,也算是基本入門了,接下來就是考驗內功的時候了,很多網站都設有反爬蟲策略,他們想方設法阻止你用非正常手段獲取數據,比如會有各種奇奇怪怪的驗證碼限制你的請求操作、對請求速度做限制,對IP做限制、甚至對數據進行加密操作,總之,就是為了提高獲取數據的成本。這時你需要掌握的知識就要更多了,你需要深入理解 HTTP 協議,你需要理解常見的加解密算法,你要理解 HTTP 中的 cookie,HTTP 代理,HTTP中的各種HEADER。爬蟲與反爬蟲就是相愛相殺的一對,道高一次魔高一丈。
如何應對反爬蟲沒有既定的統一的解決方案,靠的是你的經驗以及你所掌握的知識體系。這不是僅憑21天入門教程就能達到的高度。
進行大規模爬蟲,通常都是從一個URL開始爬,然后把頁面中解析的URL鏈接加入待爬的URL集合中,我們需要用到隊列或者優先隊列來區別對待有些網站優先爬,有些網站后面爬。每爬去一個頁面,是使用深度優先還是廣度優先算法爬取下一個鏈接。每次發起網絡請求的時候,會涉及到一個DNS的解析過程(將網址轉換成IP)為了避免重復地 DNS 解析,我們需要把解析好的 IP 緩存下來。URL那么多,如何判斷哪些網址已經爬過,哪些沒有爬過,簡單點就是是使用字典結構來存儲已經爬過的的URL,但是如果碰過海量的URL時,字典占用的內存空間非常大,此時你需要考慮使用 Bloom Filter(布隆過濾器),用一個線程逐個地爬取數據,效率低得可憐,如果提高爬蟲效率,是使用多線程,多進程還是協程,還是分布式操作,都需要反復實踐。