OpenAI開(kāi)源最新工具包,模型增大10倍只需額外增加20% 計(jì)算時(shí)間
近日,OpenAI 在 GitHub 上開(kāi)源***工具包 gradient-checkpointing,該工具包通過(guò)設(shè)置梯度檢查點(diǎn)(gradient-checkpointing)來(lái)節(jié)省內(nèi)存資源。據(jù)悉,對(duì)于普通的前饋模型,可以在計(jì)算時(shí)間只增加 20% 的情況下,在 GPU 上訓(xùn)練比之前大十多倍的模型。雷鋒網(wǎng)(公眾號(hào):雷鋒網(wǎng)) AI 研習(xí)社將該開(kāi)源信息編譯整理如下:
通過(guò)梯度檢查點(diǎn)(gradient-checkpointing)來(lái)節(jié)省內(nèi)存資源
訓(xùn)練非常深的神經(jīng)網(wǎng)絡(luò)需要大量?jī)?nèi)存,利用 Tim Salimans 和 Yaroslav Bulatov 共同開(kāi)發(fā)的 gradient-checkpointing 包中的工具,可以犧牲計(jì)算時(shí)間來(lái)解決內(nèi)存過(guò)小的問(wèn)題,讓你更好地針對(duì)模型進(jìn)行訓(xùn)練。
對(duì)于普通的前饋模型,可以在計(jì)算時(shí)間只增加 20% 的情況下,在 GPU 上訓(xùn)練比之前大十多倍的模型。
訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)時(shí),損失的梯度是在內(nèi)存密集部分通過(guò)反向傳播(backpropagation)算法來(lái)計(jì)算的。在訓(xùn)練模型時(shí)定義計(jì)算圖中的檢查點(diǎn),并在這些檢查點(diǎn)之間通過(guò)反向傳播算法重新計(jì)算這些圖,可以在降低內(nèi)存的同時(shí)計(jì)算梯度值。
當(dāng)訓(xùn)練一個(gè) n 層的深度前饋神經(jīng)網(wǎng)絡(luò)時(shí),可以利用這種方式將內(nèi)存消耗減少到 O (sqrt (n)),代價(jià)是需要執(zhí)行一個(gè)額外的前向傳遞操作。這個(gè)庫(kù)可以在 Tensorflow 中實(shí)現(xiàn)這一功能——使用 Tensorflow graph editor 來(lái)自動(dòng)重寫(xiě)后向傳遞的計(jì)算圖。
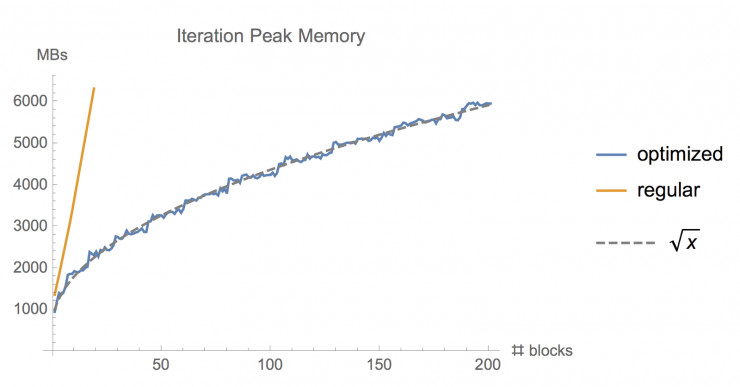
圖:使用常規(guī)的 tf.gradients 函數(shù)和使用這種優(yōu)化內(nèi)存梯度實(shí)現(xiàn)法(memory-optimized gradient implementation)訓(xùn)練不同層數(shù)的 ResNet 模型時(shí)需要的內(nèi)存對(duì)比
大家現(xiàn)在就可以安裝
pip install tf-nightly-gpu
pip install toposort networkx pytest
當(dāng)執(zhí)行這一程序時(shí),需要保證能找到 CUPTI。
這時(shí)可以執(zhí)行
export LD_LIBRARY_PATH="${LD_LIBRARY_PATH}:/usr/local/cuda/extras/CUPTI/lib64
使用方法
這個(gè)庫(kù)提供嵌入式功能,能對(duì) tf.gradients 函數(shù)進(jìn)行替換,可以輸入如下程序來(lái)引入相關(guān)函數(shù):
from memory_saving_gradients import gradients
大家可以像使用 tf.gradients 函數(shù)一樣使用 gradients 函數(shù)來(lái)計(jì)算參數(shù)損失的梯度。
gradients 函數(shù)有一個(gè)額外的功能——檢查點(diǎn)(checkpoints)。
檢查點(diǎn)會(huì)對(duì) gradients 函數(shù)進(jìn)行指示——在計(jì)算圖的前向傳播中,圖中的哪一部分節(jié)點(diǎn)是用戶想要檢查的點(diǎn)。隨后,會(huì)在后向傳播中重新計(jì)算檢查點(diǎn)之間的節(jié)點(diǎn)。
大家可以為檢查點(diǎn)提供一系列張量(gradients (ys,xs,checkpoints=[tensor1,tensor2])),或者可以使用如下幾個(gè)關(guān)鍵詞('collection'、'memory' 、'speed')來(lái)進(jìn)行設(shè)置。
覆蓋 tf.gradients 函數(shù)
使用 gradients 函數(shù)的另一個(gè)方法是直接覆蓋 tf.gradients 函數(shù),方法如下:
import tensorflow as tf
import memory_saving_gradients
# monkey patch tf.gradients to point to our custom version, with automatic checkpoint selection
def gradients_memory (ys, xs, grad_ys=None, **kwargs):
return memory_saving_gradients.gradients (ys, xs, grad_ys, checkpoints='memory', **kwargs)
tf.__dict__["gradients"] = gradients_memory
這樣操作之后,所有調(diào)用 tf.gradients 函數(shù)的請(qǐng)求都會(huì)使用新的節(jié)省內(nèi)存的方法。
測(cè)試
在測(cè)試文件夾中,有已經(jīng)寫(xiě)好的用于測(cè)試代碼準(zhǔn)確性和不同模型占用內(nèi)存的腳本。
大家可以執(zhí)行 ./run_all_tests.sh 來(lái)修改代碼,并著手測(cè)試。
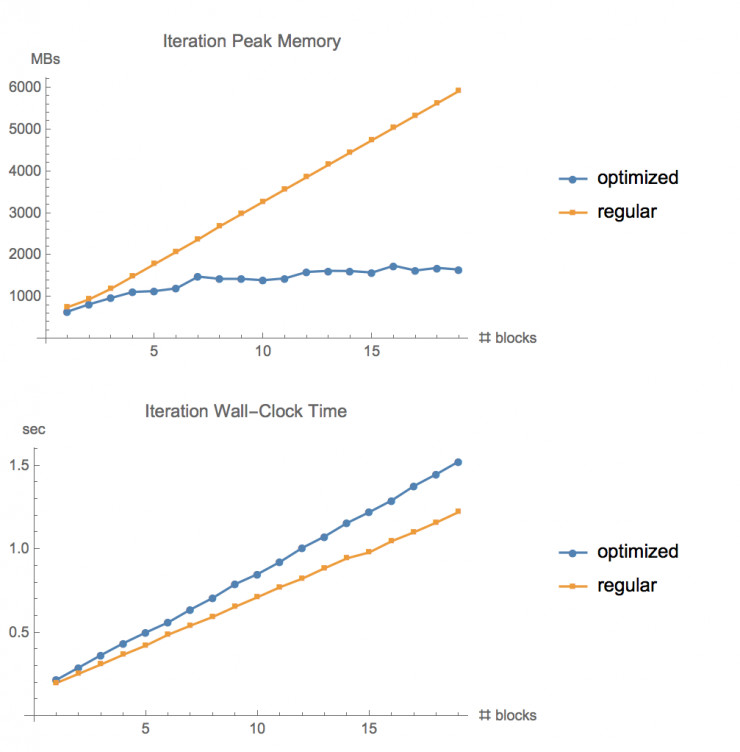
圖:在 CIFAR10 數(shù)據(jù)集上,使用常規(guī)的梯度函數(shù)和使用***的優(yōu)化內(nèi)存函數(shù),在不同層數(shù)的 ResNet 網(wǎng)絡(luò)下的內(nèi)存占用情況和執(zhí)行時(shí)間的對(duì)比
via:GitHub