從Chrome源碼看DNS解析過程
DNS解析的作用是把域名解析成相應的IP地址,因為在廣域網上路由器需要知道IP地址才知道把報文發給誰。DNS是Domain Name System域名系統的縮寫,它是一個協議,在RFC 1035具體描述了這個協議。具體過程如下圖所示:
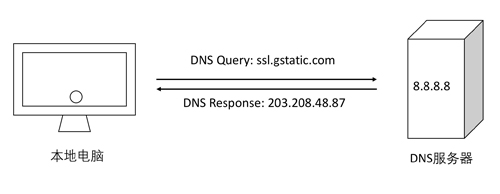
這個過程看似簡單,但是有幾個問題:
(1)瀏覽器是怎么知道DNS解析服務器,如上圖的8.8.8.8這臺?
(2)一個域名可以解析成多個IP地址嗎,如果只有一個IP地址,在并發量很大的情況下,那臺服務器可能會爆?
(3)把域名綁了host之后,是不是就不用域名解析了直接用的本地host指定的IP地址?
(4)域名解析的有效時間為多長,即過了多久后同一個域名需要再次進行解析?
(5)什么是域名解析的A記錄、AAAA記錄、CNAME記錄?
其實域名解析和Chrome沒有直接關系,即使是最簡單的curl命令也需要進行域名解析,但是我們可以通過Chrome源碼來看一下這個過程是怎么樣的,并且回答上面的問題。
首先***個問題,瀏覽器是怎么知道DNS解析服務器的,在本機的網絡設置里面可以看到當前的DNS服務器IP,如我電腦的:
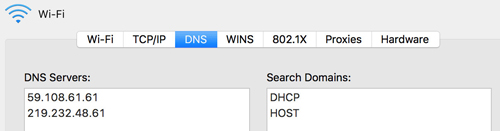
這兩個DNS Server是我家接的某正寬帶提供的:
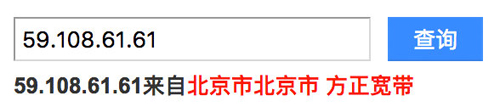
一般寬帶服務商都會提供DNS服務器,谷歌還為公眾提供了兩個免費的DNS服務,分別為8.8.8.8和8.8.4.4,取這兩個IP地址是為了容易記住,當你的DNS服務不好用的時候,可以嘗試改成這兩個。
入網的設備是怎么獲取到這些IP地址的呢?是通過動態主機配置協議(DHCP),當一臺設備連到路由器之后,路由器通過DHCP給它分配一個IP地址,并告訴它DNS服務器,如下路由器的DHCP設置:
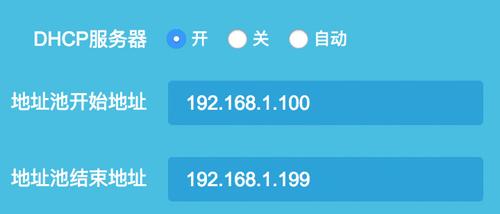
通過wireshark抓包可以觀察到這個過程:
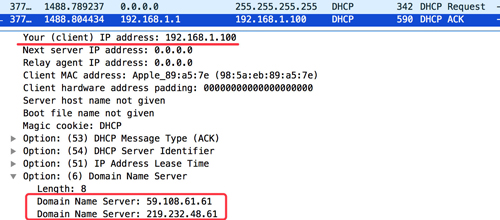
當我的電腦連上wifi的時候,會發一個DHCP Request的廣播,路由器收到這個廣播后就會向我的電腦分配一個IP地址并告知DNS服務器。
這個時候系統就有DNS服務器了,Chrome是調res_ninit這個系統函數(Linux)去獲取系統的DNS服務器,這個函數是通過讀取/etc/resolver.conf這個文件獲取DNS:
- #
- # Mac OS X Notice
- #
- # This file is not used by the host name and address resolution
- # or the DNS query routing mechanisms used by most processes on
- # this Mac OS X system.
- #
- # This file is automatically generated.
- #
- search DHCP HOST
- nameserver 59.108.61.61
- nameserver 219.232.48.61
search選項的作用是當一個域名不可解析時,就會嘗試在后面添加相應的后綴,如ping hello,無法解析就會分別ping hello.DHCP/hello.HOST,結果***都無法解析。
Chrome在啟動的時候根據不同的操作系統去獲取DNS服務器配置,然后把它放到DNSConfig的nameservers:
- // List of name server addresses.
- std::vector<IPEndPoint> nameservers;
Chrome還會監聽網絡變化同步改變配置。
然后用這個nameservers列表去初始化一個socket pool即套接字池,套接字是用來發請求的。在需要做域名解析的時候會從套接字池里面取出一個socket,并傳遞想要用的server_index,初始化的時候是0,即取***個DNS服務IP地址,一旦解析請求兩次都失敗了,則server_index + 1使用下一個DNS服務。
- unsigned server_index =
- (first_server_index_ + attempt_number) % config.nameservers.size();
- // Skip over known failed servers.
- // ***attempts數為2,在構造DnsConfig設定的
- server_index = session_->NextGoodServerIndex(server_index);
如果所有的nameserver都失敗了,那么它會取最早失敗的nameserver.
Chrome在啟動的時候除了會讀取DNS server之外,還會去取讀取和解析hosts文件,放到DNSConfig的hosts屬性里面,它是一個哈希map:
- // Parsed results of a Hosts file.
- //
- // Although Hosts files map IP address to a list of domain names, for name
- // resolution the desired mapping direction is: domain name to IP address.
- // When parsing Hosts, we apply the "first hit" rule as Windows and glibc do.
- // With a Hosts file of:
- // 300.300.300.300 localhost # bad ip
- // 127.0.0.1 localhost
- // 10.0.0.1 localhost
- // The expected resolution of localhost is 127.0.0.1.
- using DnsHosts = std::unordered_map<DnsHostsKey, IPAddress, DnsHostsKeyHash>;
hosts文件在linux系統上是在/etc/hosts:
- const base::FilePath::CharType kFilePathHosts[] =
- FILE_PATH_LITERAL("/etc/hosts");
讀取這個文件沒有什么技巧,需要一行行地去處理,并做一些非法情況的判斷,如上面代碼的注釋。
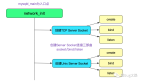
這樣DNSConfig里面就有兩個配置了,一個是hosts,另一個是nameservers,DNSConfig是組合到DNSSession,它們的組合關系如下圖所示:
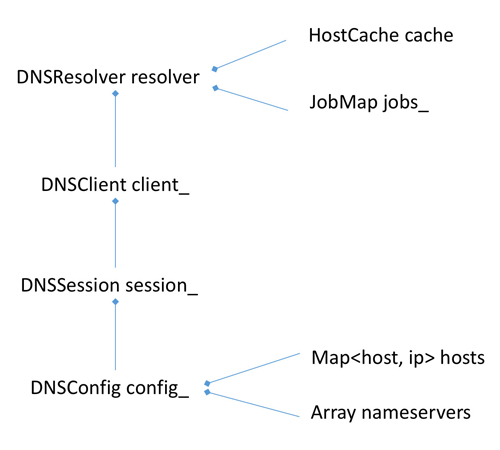
resolver是負責解析的驅動類,它組合了一個client,client創建一個session,session層有一個很大的作用是用來管理server_index和socket pool如分配socket等,session初始化config,config用來讀取本地綁的hosts和nameservers兩個配置。這幾層各有各的職責。
resolver有一個重要的功能,它組合了一個job,用來創建任務隊列。resolver還組合了一個Hostcache,它是放解析結果的緩存,如果緩存緩存***的話,就不用去解析了,這個過程是這樣的,外部調rosolver提供的HostResolverImpl::Resolve接口,這個接口會先判斷在本地是否能處理:
- int net_error = ERR_UNEXPECTED;
- if (ServeFromCache(*key, info, &net_error, addresses, allow_stale,
- stale_info)) {
- source_net_log.AddEvent(NetLogEventType::HOST_RESOLVER_IMPL_CACHE_HIT,
- addresses->CreateNetLogCallback());
- // |ServeFromCache()| will set |*stale_info| as needed.
- return net_error;
- }
- // TODO(szym): Do not do this if nsswitch.conf instructs not to.
- // http://crbug.com/117655
- if (ServeFromHosts(*key, info, addresses)) {
- source_net_log.AddEvent(NetLogEventType::HOST_RESOLVER_IMPL_HOSTS_HIT,
- addresses->CreateNetLogCallback());
- MakeNotStale(stale_info);
- return OK;
- }
- return ERR_DNS_CACHE_MISS;
上面代碼先調serveFromCache去cache里面看有沒有,如果cache***的話則返回,否則看hosts是否***,如果都不***則返回CACHE_MISS的標志位。如果返回值不等于CACHE_MISS,則直接返回:
- if (rv != ERR_DNS_CACHE_MISS) {
- LogFinishRequest(source_net_log, info, rv);
- RecordTotalTime(info.is_speculative(), true, base::TimeDelta());
- return rv;
- }
否則創建一個job,并看是否能立刻執行,如果job隊列太多了,則添加到job隊列后面,并傳遞一個成功的回調處理函數。
所以這里和我們的認知基本上是一樣的,先看下cache有沒有,然后再看hosts有沒有,如果沒有的話再進行查詢。在cache查詢的時候如果這個cache已經過時了即staled,也會返回null,而判斷是否stale的標準如下:
- bool is_stale() const {
- return network_changes > 0 || expired_by >= base::TimeDelta();
- }
即網絡發生了變化,或者expired_by大于0,則認為是過時的cache。這個時間差是用當前時間減掉當前cache的過期時間:
- stale.expired_by = now - expires_;
而過期時間是在初始化的時候使用now + ttl的值,而這個ttl是使用上一次請求解析的時候返回的ttl:
- uint32_t ttl_sec = std::numeric_limits<uint32_t>::max();
- ttl_sec = std::min(ttl_sec, record.ttl);
- *ttl = base::TimeDelta::FromSeconds(ttl_sec);
上面代碼做了一個防溢出處理。在wireshark的dns response可以直觀地看到這個ttl:
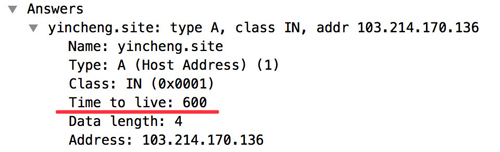
當前域名的TTL值為600s即10分鐘。這個可以在買域名的提供商進行設置:

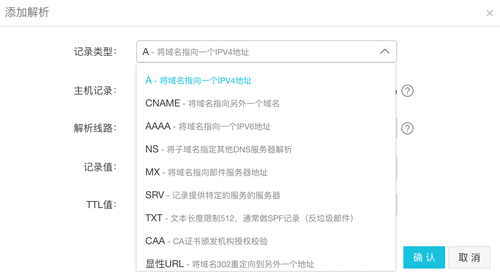
另外可以看到這個記錄類型是A的,什么是A呢,如下圖所示:
在添加解析的時候可以看到,A就是把域名解析到一個IPv4地址,而AAAA是解析到IPv6地址,CNAME是解析到另外一個域名。使用CNAME的好處是當很多其它域名指向一個CNAME時,當需要改變IP地址時,只要改變這個CNAME的地址,那么其它的也跟著生效了,但是得做二次解析。
如果域名在本地不能解析的話,Chrome就會去發請求了。操作系統提供了一個叫getaddrinfo的系統函數用來做域名解析,但是Chrome并沒有使用,而是自己實現了一個DNS客戶端,包括封裝DNS request報文以及解析DNS response報文。這樣可能是因為靈活度會更大一點,例如Chrome可以自行決定怎么用nameservers,順序以及失敗嘗試的次數等。
在resolver的startJob里面啟動解析。取到下一個queryId,然后構建一個query,再構建一個DnsUDPAttempt,再執行它的start,因為DNS客戶端查詢使用的是UDP報文(輔域名服務器向主域名服務器查詢是用的TCP):
- uint16_t id = session_->NextQueryId();
- std::unique_ptr<DnsQuery> query;
- query.reset(new DnsQuery(id, qnames_.front(), qtype_, opt_rdata_));
- DnsUDPAttempt* attempt =
- new DnsUDPAttempt(server_index, std::move(lease), std::move(query));
- int rv = attempt->Start(
- base::Bind(&DnsTransactionImpl::OnUdpAttemptComplete,
- base::Unretained(this), attempt_number,
- base::TimeTicks::Now()));
具體解析的過程拆成了幾步,這個代碼組織是這樣的,通過一個state決定執行順序:
- int rv = result;
- do {
- // 最開始的state為STATE_SEND_QUERY
- State state = next_state_;
- next_state_ = STATE_NONE;
- switch (state) {
- case STATE_SEND_QUERY:
- rv = DoSendQuery();
- break;
- case STATE_SEND_QUERY_COMPLETE:
- rv = DoSendQueryComplete(rv);
- break;
- case STATE_READ_RESPONSE:
- rv = DoReadResponse();
- break;
- case STATE_READ_RESPONSE_COMPLETE:
- rv = DoReadResponseComplete(rv);
- break;
- default:
- NOTREACHED();
- break;
- }
- } while (rv != ERR_IO_PENDING && next_state_ != STATE_NONE);
state從***個case執行完之后變成第二個case的state,在第二個case的執行函數里面又把它改成第三個,這樣依次下來,直到變成while循環里面的STATE_DONE,或者是ERR狀態結束當前transaction事務。所以這個代碼組織還是比較有趣的。
***解析成功之后,會把結果放到cache里面:
- if (did_complete) {
- resolver_->CacheResult(key_, entry, ttl);
- RecordJobHistograms(entry.error());
- }
然后生成一個addressList,傳遞給相應的callback,因為DNS解析可能會返回多個結果,如下面這個:
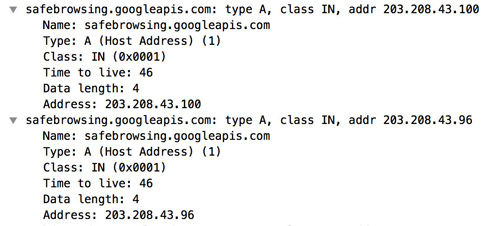
這里我們沒用Chrome打印結果了,都是直接看的wireshark的輸出,因為添加打印函數比較麻煩,直接看wireshark的輸出比較直觀,節省時間。
本文簡單地介紹了DNS解析的過程以及DNS的一些相關概念,相信到這里,應該可以回答上面提出的幾個問題了。總地來說,客戶端向域名解析服務器發起查詢,然后服務器返回響應。DNS服務器nameservers是在設備接入網絡的時候路由器通過DHCP發給設備的,chrome會按照nameservers的順序發起查詢,并將結果緩存,有效時間根據ttl,有效期內兩次查詢直接使用cache。DNS解析的結果有幾種類型,最常見的是A記錄和CNAME記錄,A記錄表示結果是一個IP地址,CNAME表示結果是另外一個域名。
本文沒有很深入詳細地介紹,但是核心的概念和邏輯過程應該是都有涉及了。
【本文是51CTO專欄作者“人人網FED”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】