如何優(yōu)雅的分析 Redis 里存了啥?
運(yùn)維 Redis 的苦惱
我們都知道 Redis 是互聯(lián)網(wǎng)產(chǎn)品開發(fā)中不可缺少的常備武器,速度快、數(shù)據(jù)結(jié)構(gòu)豐富、簡單易用是它的優(yōu)點(diǎn),但同時(shí)也是因?yàn)樘菀子昧耍覀兊拈_發(fā)同學(xué)不管什么數(shù)據(jù)、不管這數(shù)據(jù)有多大、不管數(shù)據(jù)有多少通通塞進(jìn)去,要查的時(shí)候通通一把梭全取出來,你說這是多么信任 Redis 啊,運(yùn)維 Redis 的同學(xué)聽到這種說法一定會(huì)露出下邊這種表情:
為了更好的了解我們?cè)谌绾问褂?Redis 除了對(duì) Redis 做一些使用規(guī)范,還需要對(duì)線上使用的 Redis 的有充分的了解。那么問題來了:一個(gè) Redis 的實(shí)例用了那么大的內(nèi)存,里邊到底存了啥?都有那些 Key?每個(gè) Key 用了多少空間?Redis 內(nèi)存使用越來越大,卻不知道里面都存了啥,想要分析一次費(fèi)時(shí)費(fèi)力,一個(gè)搞不好還容易影響業(yè)務(wù)。
那有沒有什么辦法讓我們安全高效的看到 Redis 內(nèi)存消耗的詳細(xì)報(bào)表呢?就像這樣又直觀又漂亮:

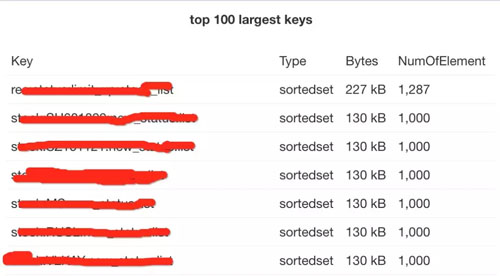
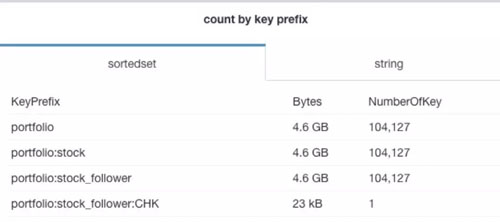
辦法總比問題多,有需求就有解決方案。上面就是雪球 SRE 團(tuán)隊(duì)做出來的 Redis 數(shù)據(jù)可視化平臺(tái) RDR (Redis Data Reveal)。RDR 可以非常方便的對(duì) Reids 的內(nèi)存進(jìn)行分析了解一個(gè) Reids 里都有那些 Key,那些 Key 占用的空間是多少,占比如何,非常直觀業(yè)。那么接下來聊聊我們是如何設(shè)計(jì)并實(shí)現(xiàn)它的。
設(shè)計(jì)思路
首先想有什么辦法可以拿到 Redis 的所有數(shù)據(jù)呢?
先通過 keys * 命令,拿到所有的 key,然后根據(jù) key 再獲取所有的內(nèi)容。
優(yōu)點(diǎn):可以不使用 redis 機(jī)器的硬盤,直接網(wǎng)絡(luò)傳輸
缺點(diǎn):如果key數(shù)量特別多,keys 命令可能會(huì)導(dǎo)致 Redis 卡住影響業(yè)務(wù);需要對(duì) Redis 請(qǐng)求非常多次,資源消耗多;遍歷數(shù)據(jù)太慢
開啟 aof,通過 aof 文件獲取到所有數(shù)據(jù)。
優(yōu)點(diǎn):無需影響 Redis 服務(wù),完全離線操作,足夠安全;
缺點(diǎn):有一些 Redis 實(shí)例寫入頻繁,不適合開啟 aof,普適性不強(qiáng);aof 文件有可能特別大,傳輸、解析起來太慢,效率低。
使用 bgsave,獲取 rdb 文件,解析后獲取數(shù)據(jù)。
優(yōu)點(diǎn):機(jī)制成熟,可靠性好;文件相對(duì)小,傳輸、解析效率高
缺點(diǎn):bgsave 雖然會(huì) fork 子進(jìn)程,但還是有可能導(dǎo)致主進(jìn)程卡住一段時(shí)間,對(duì)業(yè)務(wù)有產(chǎn)生影響的風(fēng)險(xiǎn)
以上幾種方式我們?cè)u(píng)估之后,決定采用低峰期在從節(jié)點(diǎn)做 bgsave 獲取 rdb 文件,相對(duì)安全可靠,也可以覆蓋所有業(yè)務(wù)的 Redis 集群。每個(gè)實(shí)例每天在低峰期自動(dòng)生成一個(gè) rdb 文件,即使報(bào)表數(shù)據(jù)有一天的延遲也是可以接受的。
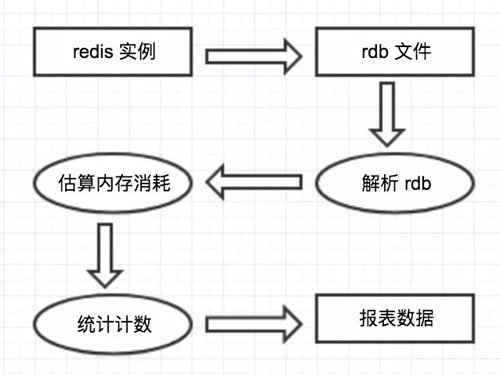
拿到了 rdb 文件就相當(dāng)于拿到了 Redis 實(shí)例的所有數(shù)據(jù),接下來就是生成報(bào)表的過程了。
解析 rdb 文件,獲取到 key 和 value 的內(nèi)容。
根據(jù)相對(duì)應(yīng)的數(shù)據(jù)結(jié)構(gòu)及內(nèi)容,估算內(nèi)存消耗等
統(tǒng)計(jì)并生成報(bào)表
邏輯很簡單,所以設(shè)計(jì)思路很清晰。數(shù)據(jù)流圖如下:
然后我們看下具體該如何實(shí)現(xiàn),雪球 SRE 自研的組件基本都是用 GO 做的后端,所以語言選型沒什么糾結(jié),直接用 GO。
解析 RDB
按照 Redis 的協(xié)議來做就可以了,這個(gè)在 github 上各種語言基本都有相關(guān)的庫,拿過來使用即可。需要注意的是語言本身的性能,對(duì)解析效率有比較大的影響。
估算內(nèi)存消耗
一條記錄會(huì)有哪些內(nèi)存使用呢?
我們知道 Redis 的實(shí)現(xiàn)里面有一些基礎(chǔ)的數(shù)據(jù)結(jié)構(gòu),就是用這些結(jié)構(gòu)來實(shí)現(xiàn)了對(duì)外暴露的各種數(shù)據(jù)類型:比如 sds、dict、intset、zipmap、adlist、ziplist、quicklist、skiplist 等等。只要根據(jù)這條記錄的數(shù)據(jù)類型,找出使用了哪些數(shù)據(jù)結(jié)構(gòu),再計(jì)算出這些基礎(chǔ)數(shù)據(jù)結(jié)構(gòu)的內(nèi)存消耗,再加上數(shù)據(jù)的內(nèi)存使用,以及一些額外開銷比如過期時(shí)間等,就可以估算出一條記錄到底使用了多少內(nèi)存。
但是由于 Redis 做了非常多的優(yōu)化,同樣的一種數(shù)據(jù)類型,在不同場景下使用的數(shù)據(jù)結(jié)構(gòu)有可能是不同的。比如 List ,比較老版本的 Redis,會(huì)根據(jù)list元素的數(shù)量來決定來使用哪種結(jié)構(gòu),較短的時(shí)候使用 adlist,長之后使用 ziplist,數(shù)值可以通過 list-max-ziplist-entries 來配置。3.2 版本以后全都使用了 quicklist。而不同結(jié)構(gòu)對(duì)于內(nèi)存的使用其實(shí)是有區(qū)別的,我們計(jì)算的時(shí)候也沒辦法拿到具體的配置,所以都按默認(rèn)配置來計(jì)算,***得出的值是一個(gè)估算的值,不過也基本可以反應(yīng)使用情況了。如果大家對(duì)于 Redis 使用的各種數(shù)據(jù)結(jié)構(gòu)感興趣,想了解其設(shè)計(jì)及適用場景,可以多搜索一下相關(guān)的資料以及閱讀 Redis 源碼。
舉個(gè)計(jì)算內(nèi)存使用的例子:
假如我們通過解析 rdb,獲取到了一個(gè) key 為 hello,value 為 world,類型為 string ,ttl 為 1440 的一條記錄,它的內(nèi)存使用是這樣的:
一個(gè) dictEntry 的消耗,因?yàn)槭?redis db dict 中的一個(gè)元素
一 個(gè) robj 的消耗,robj 是為了在同一個(gè)dict內(nèi)能夠存儲(chǔ)不同類型的value,而使用的一個(gè)通用的數(shù)據(jù)結(jié)構(gòu),全名是 Redis Object
存儲(chǔ) key 的 sds 消耗,sds 是 Redis 中存儲(chǔ)字符串使用的數(shù)據(jù)結(jié)構(gòu)
存儲(chǔ)過期時(shí)間消耗
存儲(chǔ) value 的 sds 消耗
前四項(xiàng)基本是存儲(chǔ)任何一個(gè) key 都需要消耗的,***一項(xiàng)根據(jù) value 的數(shù)據(jù)結(jié)構(gòu)不同而不同。
一個(gè) dictEntry 有 2 個(gè)指針,一個(gè) int64 的內(nèi)存消耗(https://github.com/antirez/redis/blob/unstable/src/dict.h)
一個(gè) robj 有 1 指針,一個(gè) int,以及幾個(gè)使用位域的字段共消耗 4 字節(jié)(https://github.com/antirez/redis/blob/unstable/src/server.h)
過期時(shí)間也是存儲(chǔ)為一個(gè) dictEntry,時(shí)間戳為 int64(https://github.com/antirez/redis/blob/unstable/src/db.c)
存儲(chǔ) sds 需要存儲(chǔ) header 以及字符串長度 +1 的空間,header 長度根據(jù)字符串長度不同也會(huì)有所不同(https://github.com/antirez/redis/blob/unstable/src/sds.h)
我們根據(jù)以上信息可以算出,向操作系統(tǒng)申請(qǐng)這些內(nèi)存,真正需要多少內(nèi)存。由于 redis 支持多種 malloc 算法,我們就按 jemalloc 的分配方式算,這里也是可能存在誤差的點(diǎn)。
所以*** key 為 hello 的這條記錄在 64 位操作系統(tǒng)上一共會(huì)消耗 92 字節(jié)。

其他類型的計(jì)算也大致是同樣的思路,只不過根據(jù)不同的數(shù)據(jù)結(jié)構(gòu)需要計(jì)算不同的內(nèi)存消耗,計(jì)算的時(shí)候要記得考慮內(nèi)存對(duì)齊的情況。還有由于 zset 的算法涉及到了隨機(jī)生成層數(shù),我們也使用同樣的算法來隨機(jī),但是算出來的值肯定不是精確的,也是一個(gè)誤差點(diǎn)。
統(tǒng)計(jì)計(jì)數(shù)
終于可以拿到任何一個(gè) key 的內(nèi)存使用了,哪些是最有意義最有價(jià)值的數(shù)據(jù)呢?
top N,毫無疑問***的前 N 個(gè) key 一定是要關(guān)注的
不同數(shù)據(jù)類型的 key 數(shù)量元素?cái)?shù)量分布以及內(nèi)存使用情況
按照前綴分類,統(tǒng)一的前綴一般意味著某個(gè)特定的業(yè)務(wù)在使用,計(jì)算各個(gè)分類的 key 數(shù)量及內(nèi)存使用情況
這幾個(gè)需求實(shí)現(xiàn)起來也都很容易:
維護(hù)一個(gè)小頂堆來存儲(chǔ)前 N 個(gè)***的即可,***取出堆中的數(shù)據(jù)即可
計(jì)數(shù)即可
一般都會(huì)有特定的分隔符,比如 :|._ 等字符,按照這些字符切出公共前綴再統(tǒng)計(jì),同時(shí)把所有的數(shù)字都替換為0,便于分類
寫在***
可以每天打開個(gè)網(wǎng)頁就可以看到某個(gè) Redis 實(shí)例的內(nèi)存使用的詳細(xì)情況,是件非常幸福的事情,Redis 的內(nèi)存使用再也不是黑盒。