













關于Hive數(shù)據倉庫的那些事兒--數(shù)據存儲結構
本篇我們從底層存儲數(shù)據結構出發(fā),講一講Hive是如何組織數(shù)據的。
行式存儲 v.s. 列式存儲
傳統(tǒng)數(shù)據庫大多基于行(Row-based)實現(xiàn)數(shù)據存儲,即一行行的記錄。此類存儲結構對大多數(shù)的傳統(tǒng)數(shù)據工作都是非常有效的,下面我們先來回顧一下數(shù)據庫系統(tǒng)中數(shù)據工作的概念:
- 在線事務處理(OLTP)
OLTP是傳統(tǒng)數(shù)據工作的主要應用,主要是基本的、日常的事務處理,即插入、修改、查詢和刪除等操作。
- 在線分析處理(OLAP)
OLAP是數(shù)據分析和數(shù)據挖掘工作的主要應用。OLAP支持復雜的分析操作,側重決策支持并提供直觀易懂的查詢結果。
在Row-based數(shù)據庫中,一行記錄中的每一列都是緊挨著另一列存放在硬盤中的,行之間也成線性存儲。這樣的模式十分適用于OLTP工作,由于每次操作對象都是某幾行記錄,每次查詢只需要從硬盤中加載最少的數(shù)據。
OLAP更傾向于訪問百萬、千萬甚至上億條記錄。傳統(tǒng)的行式存儲(Row-oriented Storage)使得我們需要花費時間加載每一行,而真正需要的數(shù)據可能僅是每行中的幾個數(shù)據列而已。如果存儲結構基于列(Column-based),那么單列查詢就只需要加載硬盤中的最小列塊,這種方式在磁盤IO上是比較高效的。正是如此,我們可以說OLAP促成了列式存儲(Columnar Storage)的出現(xiàn)。
下圖展示了Row-oriented Storage和Columnar Storage的原理:
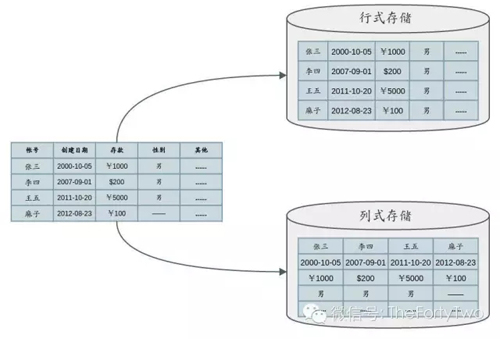
當然,列式存儲也并非***。單純給Column-based數(shù)據表加索引,并不能使其在OLTP工作流上表現(xiàn)高效。就刪改記錄等需求而言,查詢任務需要加載磁盤中的很多列塊才能整合一條完整的記錄。如果一個數(shù)據表的列項過于豐富,那么Columnar Storage反而會加重OLTP工作流的磁盤I/O負載。相比而言,Row-oriented Storage則更適合對單一整行記錄的處理。
如何選擇存儲結構取決于你的企業(yè)對OLTP/OLAP業(yè)務的需求。目前還有一些行列混合存儲技術結合了兩種架構的優(yōu)勢。例如針對Columnar Storage提出的列組(Column Group)概念,多個列形成一個組。如果訪問的列屬于同一組,查詢工作流就可以避免多個數(shù)據列的合并。這種結構能夠同時滿足OLTP和OLAP的查詢需求。
Columnar Storage從一開始就是面向大數(shù)據環(huán)境下數(shù)據倉庫的數(shù)據分析而產生的。下文我們就從Hive的實際應用中介紹Columnar Storage的優(yōu)點。
Hive的數(shù)據格式
目前Hive所支持的數(shù)據格式如下:
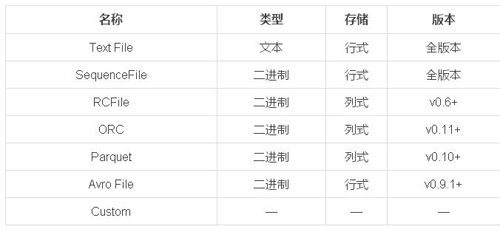
我們根據Hive文檔的描述,簡單介紹幾類Columnar Storage的數(shù)據格式。
RCFile
RCFile(Record Columnar File)是為基于MapReduce的數(shù)據倉庫系統(tǒng)設計的一個列式存儲結構。Hive在0.6.0版本后納入了RCFile。
RCFile采用二進制的key/value對來存儲數(shù)據。首先,它在行上進行水平分塊,然后每塊又以列式的方式垂直切割。RCFile將一個數(shù)據塊的metadata作為一條記錄的key,而數(shù)據塊本身作為value。這樣結合行式和列式的優(yōu)點,滿足了高效的數(shù)據加載和查詢處理,以及有效利用存儲空間等需求。下圖為RCFile的數(shù)據分塊原理:
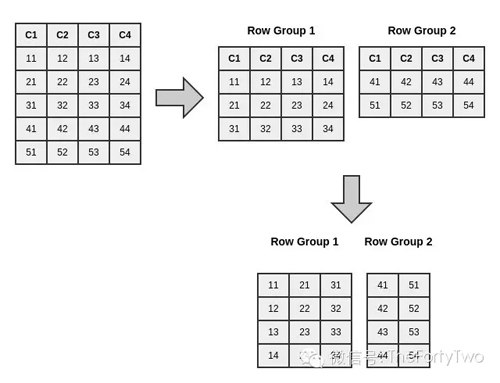
- 作為Row-oriented Storage,RCFile保證同一行的數(shù)據都在同一個節(jié)點上。
- 作為Columnar Storage,RCFile又能利用列式的優(yōu)勢進行高效壓縮,減少不必要的數(shù)據讀取。
ORC
ORC(Optimized Row Columnar)在RCFile基礎上改進,提供了更加高效的數(shù)據存取格式。和RCFile相比,ORC有如下優(yōu)勢:
- 單個Hive Task輸出單個文件,減小文件系統(tǒng)負載。
- 支持datetime、decimal和其他復雜類型(struct、list、map和union)。
- 文件內含輕量級索引。減少不必要的掃描,高效定位記錄。
- 基于數(shù)據類型的塊模式壓縮。例如String和Integer可以采用不同的壓縮方式。
- 同一文件可以利用多個RecordReader并發(fā)讀取。
- 支持免掃描進行文件分塊。
- 讀寫文件時,綁定I/O所需的***內存空間。
- 文件的metadata采取Protocol Buffers格式,允許靈活的屬性增刪。
Parquet
Apache基金會的Parquet是在Hadoop生態(tài)圈中受到廣泛支持的列式存儲格式。Parquet借鑒Dremel文章中提到的Shredding and assembly算法,將復雜、嵌套的數(shù)據結構展開來存儲。同時它還支持非常高效的壓縮方法和編碼格式。目前很多實際應用也證實了這種壓縮和編碼的優(yōu)越性能。下面是Parquet目前所支持的項目和數(shù)據描述語言:
- 項目
MapReduce、Hive、Drill、Impala、Crunch、Pig、Cascading、Spark
- 數(shù)據描述語言
Avro、Thrift、Google Protocol Buffers
Hive 0.13后,Parquet已經被作為原生態(tài)支持而正式加入Apache Hive項目。在之前的版本中,你需要將parquet-hive-bundle.jar作為第三方支持包加載到Hive中方可使用Parquet。
Why Columnar Storage?
下面從實戰(zhàn)角度出發(fā),用一系列的實驗給讀者展示在數(shù)據倉庫中使用Columnar Storage的優(yōu)勢。
我們選擇以下維度作為PB.LZO(LZO壓縮)、RCFile、ORC以及Parquet的性能標準:
- 數(shù)據壓縮比
- 任務執(zhí)行時間
- Map輸入量
- 平均CPU時間開銷
為了達成這些指標的測試,我們選取910GB的文本數(shù)據。這些數(shù)據一方面轉換為PB.LZO格式保存;另一方面采用上述后三種Columnar Storage數(shù)據格式保存,并以Snappy或Gzip/Zlib壓縮。實驗結果如下:
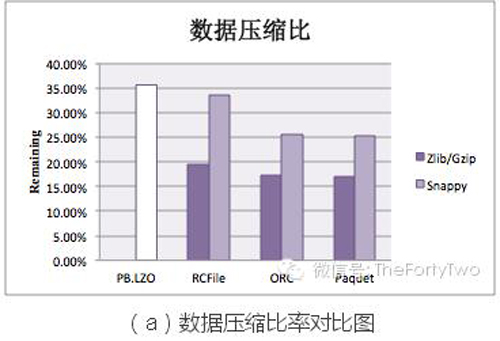
從圖(a)中可以得知,Columnar Storage比Row-oriented Storage具有更高的壓縮比。同一列內的數(shù)據比之不同列之間,具有更高的相似度。所以列塊比行的壓縮效果更加明顯。
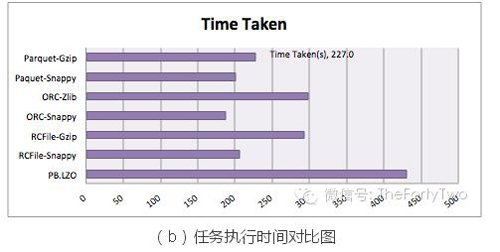
圖(b)表示任務執(zhí)行時間。由于任務執(zhí)行時間受諸多因素(例如集群計算資源閑忙情況、實驗次數(shù)是否能充分消除隨機性、網絡吞吐等等)影響,我們這里只將其作為參考。
復雜查詢會增加Reduce的計算時間,而Columnar Storage技術并不會加速Reduce的業(yè)務邏輯計算。所以我們選擇的測試任務均為:
select count(col1) from table。

圖(c)展示的文件輸入量對比充分顯示了Columnar Storage的優(yōu)勢。相比PB.LZO,采用各類Columnar Storage技術的任務Map輸入量都僅占各自數(shù)據存儲大小的一半以下,是PB.LZO輸入量的約三分之一。Parquet和ORC在這里表現(xiàn)***。值得一提的是,就執(zhí)行select count(*) from table而言,Parquet和ORC可以將Map輸入量縮減到100MB以下,這幾乎不造成太大的網絡I/O開銷。
Columnar Storage如何降低文件輸入量,取決于其列組的分割方式。越細粒度的列組越能降低簡單OLAP工作流的文件讀取量。但是多列交叉查詢就會導致頻繁的數(shù)據列合并,從而降低查詢效率。所以我們需要平衡列式存儲查詢效率和文件吞吐量之間的收益。
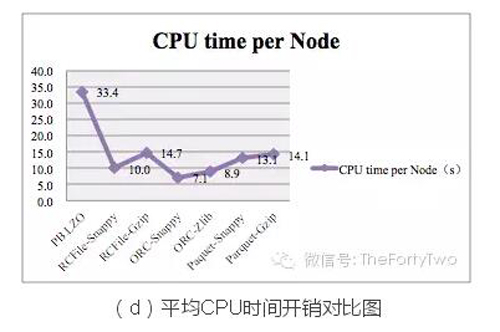
圖(d)中,CPU開銷從小到大依次是:ORC-Snappy > ORC-Zlib > RCFile-Snappy > Paquet-Snappy > Parquet-Gzip >RCFile-Gzip > PB.LZO。實驗中我們通過設置不同的min.split.size調整Mapper數(shù)均為600,***程度降低環(huán)境因素影響。
上述實驗中,以ORC-Snappy為例,性能優(yōu)化比之PB.LZO如下:
- 存儲空間額外壓縮30%;
- 查詢效率提高50%左右;
- 文件輸入減少約66%;
- CPU開銷降低70%以上。
我們可以看到,各類Columnar Storage技術在OLAP工作流上的優(yōu)勢是很明顯的。














