Spring Cloud構(gòu)建微服務架構(gòu):分布式服務跟蹤(收集原理)
在本節(jié)內(nèi)容之前,我們已經(jīng)對如何引入Sleuth跟蹤信息和搭建Zipkin服務端分析跟蹤延遲的過程做了詳細的介紹,相信大家對于Sleuth和Zipkin已經(jīng)有了一定的感性認識。接下來,我們介紹一下關于Zipkin收集跟蹤信息的過程細節(jié),以幫助我們更好地理解Sleuth生產(chǎn)跟蹤信息以及輸出跟蹤信息的整體過程和工作原理。
數(shù)據(jù)模型
我們先來看看Zipkin中關于跟蹤信息的一些基礎概念。由于Zipkin的實現(xiàn)借鑒了Google的Dapper,所以它們有著類似的核心術語,主要有下面幾個內(nèi)容:
- Span:它代表了一個基礎的工作單元。我們以HTTP請求為例,一次完整的請求過程在客戶端和服務端都會產(chǎn)生多個不同的事件狀態(tài)(比如下面所說的四個核心Annotation所標識的不同階段),對于同一個請求來說,它們屬于一個工作單元,所以同一HTTP請求過程中的四個Annotation同屬于一個Span。每一個不同的工作單元都通過一個64位的ID來唯一標識,稱為Span ID。另外,在工作單元中還存儲了一個用來串聯(lián)其他工作單元的ID,它也通過一個64位的ID來唯一標識,稱為Trace ID。在同一條請求鏈路中的不同工作單元都會有不同的Span ID,但是它們的Trace ID是相同的,所以通過Trace ID可以將一次請求中依賴的所有依賴請求串聯(lián)起來形成請求鏈路。除了這兩個核心的ID之外,Span中還存儲了一些其他信息,比如:描述信息、事件時間戳、Annotation的鍵值對屬性、上一級工作單元的Span ID等。
- Trace:它是由一系列具有相同Trace ID的Span串聯(lián)形成的一個樹狀結(jié)構(gòu)。在復雜的分布式系統(tǒng)中,每一個外部請求通常都會產(chǎn)生一個復雜的樹狀結(jié)構(gòu)的Trace。
- Annotation:它用來及時地記錄一個事件的存在。我們可以把Annotation理解為一個包含有時間戳的事件標簽,對于一個HTTP請求來說,在Sleuth中定義了下面四個核心Annotation來標識一個請求的開始和結(jié)束:
cs(Client Send):該Annotation用來記錄客戶端發(fā)起了一個請求,同時它也標識了這個HTTP請求的開始。
sr(Server Received):該Annotation用來記錄服務端接收到了請求,并準備開始處理它。通過計算sr與cs兩個Annotation的時間戳之差,我們可以得到當前HTTP請求的網(wǎng)絡延遲。
ss(Server Send):該Annotation用來記錄服務端處理完請求后準備發(fā)送請求響應信息。通過計算ss與sr兩個Annotation的時間戳之差,我們可以得到當前服務端處理請求的時間消耗。
cr(Client Received):該Annotation用來記錄客戶端接收到服務端的回復,同時它也標識了這個HTTP請求的結(jié)束。通過計算cr與cs兩個Annotation的時間戳之差,我們可以得到該HTTP請求從客戶端發(fā)起開始到接收服務端響應的總時間消耗。
- BinaryAnnotation:它用來對跟蹤信息添加一些額外的補充說明,一般以鍵值對方式出現(xiàn)。比如:在記錄HTTP請求接收后執(zhí)行具體業(yè)務邏輯時,此時并沒有默認的Annotation來標識該事件狀態(tài),但是有BinaryAnnotation信息對其進行補充。
收集機制
在理解了Zipkin的各個基本概念之后,下面我們結(jié)合前面章節(jié)中實現(xiàn)的例子來詳細介紹和理解Spring Cloud Sleuth是如何對請求調(diào)用鏈路完成跟蹤信息的生產(chǎn)、輸出和后續(xù)處理的。
首先,我們來看看Sleuth在請求調(diào)用時是怎么樣來記錄和生成跟蹤信息的。下圖展示了我們在本章節(jié)中實現(xiàn)示例的運行全過程:客戶端發(fā)送了一個HTTP請求到trace-1,trace-1依賴于trace-2的服務,所以trace-1再發(fā)送一個HTTP請求到trace-2,待trace-2返回響應之后,trace-1再組織響應結(jié)果返回給客戶端。
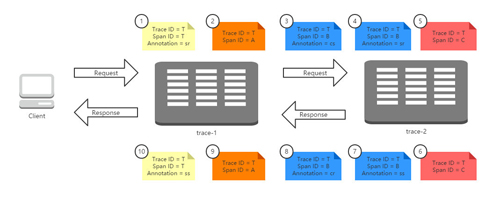
在上圖的請求過程中,我們?yōu)檎麄€調(diào)用過程標記了10個標簽,它們分別代表了該請求鏈路運行過程中記錄的幾個重要事件狀態(tài),我們根據(jù)事件發(fā)生的時間順序我們?yōu)檫@些標簽做了從小到大的編號,1代表請求的開始、10代表請求的結(jié)束。每個標簽中記錄了一些我們上面提到過的核心元素:Trace ID、Span ID以及Annotation。由于這些標簽都源自一個請求,所以他們的Trace ID相同,而標簽1和標簽10是起始和結(jié)束節(jié)點,它們的Trace ID與Span ID是相同的。
根據(jù)Span ID,我們可以發(fā)現(xiàn)在這些標簽中一共產(chǎn)生了4個不同ID的Span,這4個Span分別代表了這樣4個工作單元:
- Span T:記錄了客戶端請求到達trace-1和trace-1發(fā)送請求響應的兩個事件,它可以計算出了客戶端請求響應過程的總延遲時間。
- Span A:記錄了trace-1應用在接收到客戶端請求之后調(diào)用處理方法的開始和結(jié)束兩個事件,它可以計算出trace-1應用用于處理客戶端請求時,內(nèi)部邏輯花費的時間延遲。
- Span B:記錄了trace-1應用發(fā)送請求給trace-2應用、trace-2應用接收請求,trace-2應用發(fā)送響應、trace-1應用接收響應四個事件,它可以計算出trace-1調(diào)用trace-2的總體依賴時間(cr - cs),也可以計算出trace-1到trace-2的網(wǎng)絡延遲(sr - cs),也可以計算出trace-2應用用于處理客戶端請求的內(nèi)部邏輯花費的時間延遲(ss - sr)。
- Span C:記錄了trace-2應用在接收到trace-1的請求之后調(diào)用處理方法的開始和結(jié)束兩個事件,它可以計算出trace-2應用用于處理來自trace-1的請求時,內(nèi)部邏輯花費的時間延遲。
在圖中展現(xiàn)的這個4個Span正好對應了Zipkin查看跟蹤詳細頁面中的顯示內(nèi)容,它們的對應關系如下圖所示:
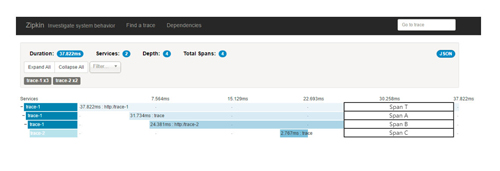
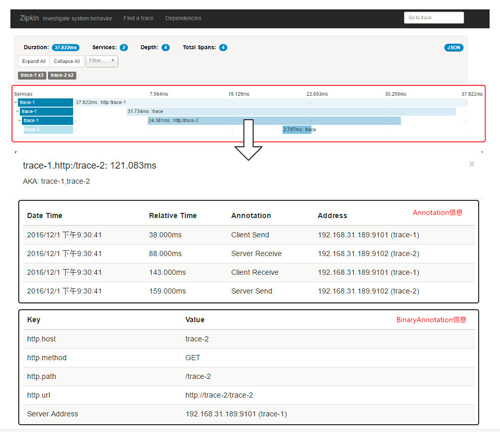
仔細的讀者可能還有這樣一個疑惑:我們在Zipkin服務端查詢跟蹤信息時(如下圖所示),在查詢結(jié)果頁面中顯示的spans是5,而點擊進入跟蹤明細頁面時,顯示的Total Spans又是4,為什么會出現(xiàn)span數(shù)量不一致的情況呢?
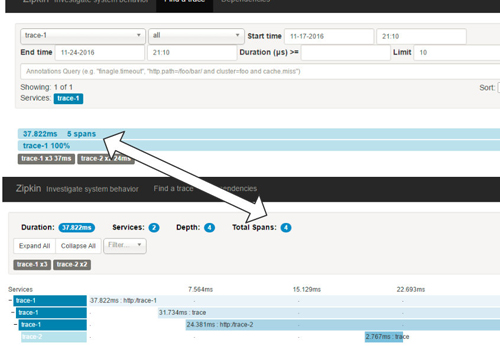
實際上這兩邊的span數(shù)量內(nèi)容有不同的含義,在查詢結(jié)果頁面中的5 spans代表了總共接收的Span數(shù)量,而在詳細頁面中的Total Span則是對接收Span進行合并后的結(jié)果,也就是前文中我們介紹的4個不同ID的Span內(nèi)容。下面我們來詳細研究一下Zipkin服務端收集客戶端跟蹤信息的過程,看看它到底收到了哪些具體的Span內(nèi)容,從而來理解Zipkin中收集到的Span總數(shù)量。
為了更直觀的觀察Zipkin服務端的收集過程,我們可以對之前實現(xiàn)的消息中間件方式收集跟蹤信息的程序進行調(diào)試。通過在Zipkin服務端的消息通道監(jiān)聽程序中增加斷點,我們就能清楚的知道客戶端都發(fā)送了一些什么信息到Zipkin的服務端。在spring-cloud-sleuth-zipkin-stream依賴包中的代碼并不多,我們很容易的就能找到定義消息通道監(jiān)聽的實現(xiàn)類:org.springframework.cloud.sleuth.zipkin.stream.ZipkinMessageListener。它的具體實現(xiàn)如下所示,其中SleuthSink.INPUT定義了監(jiān)聽的輸入通道,默認會使用名為sleuth的主題,我們也可以通過Spring Cloud Stream的配置對其進行修改。
- @MessageEndpoint
- @Conditional(NotSleuthStreamClient.class)
- public class ZipkinMessageListener {
- final Collector collector;
- @ServiceActivator(inputChannel = SleuthSink.INPUT)
- public void sink(Spans input) {
- List<zipkin.Span> converted = ConvertToZipkinSpanList.convert(input);
- this.collector.accept(converted, Callback.NOOP);
- }
- ...
- }
從通道監(jiān)聽方法的定義中我們可以看到Sleuth與Zipkin在整合的時候是有兩個不同的Span定義的,一個是消息通道的輸入對象org.springframework.cloud.sleuth.stream.Spans,它是sleuth中定義的用于消息通道傳輸?shù)腟pan對象,每個消息中包含的Span信息定義在org.springframework.cloud.sleuth.Span對象中,但是真正在zipkin服務端使用的并非這個Span對象,而是zipkin自己的zipkin.Span對象。所以,在消息通道監(jiān)聽處理方法中,對sleuth的Span做了處理,每次接收到sleuth的Span之后就將其轉(zhuǎn)換成Zipkin的Span。
下面我們可以嘗試在sink(Spans input)方法實現(xiàn)的***行代碼中加入斷點,并向trace-1發(fā)送一個請求,觸發(fā)跟蹤信息發(fā)送到RabbitMQ上。此時我們通過DEBUG模式可以發(fā)現(xiàn)消息通道中都接收到了兩次輸入,一次來自trace-1,一次來自trace-2。下面兩張圖分別展示了來自trace-1和trace-2輸出的跟蹤消息,其中trace-1的跟蹤消息包含了3條span信息,trace-2的跟蹤消息包含了2條span信息,所以在這個請求調(diào)用鏈上,一共發(fā)送了5個span信息,也就是我們在Zipkin搜索結(jié)果頁面中看到的spans數(shù)量信息。
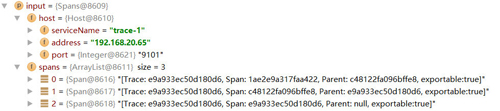

點開一個具體的Span內(nèi)容,我們可以看到如下所示的結(jié)構(gòu),它記錄了Sleuth中定義的Span詳細信息,包括該Span的開始時間、結(jié)束時間、Span的名稱、Trace ID、Span ID、Tags(對應Zipkin中的BinaryAnnotation)、Logs(對應Zipkin中的Annotation)等我們之前提到過的核心跟蹤信息。
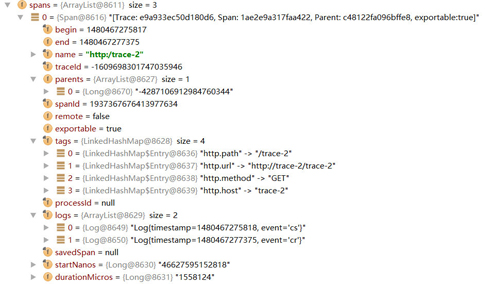
介紹到這里仔細的讀者可能會有一個這樣的疑惑,在明細信息中展示的Trace ID和Span ID的值為什么與列表展示的概要信息中的Trace ID和Span ID的值不一樣呢?實際上,Trace ID和Span ID都是使用long類型存儲的,在DEBUG模式下查看其明細時自然是long類型,也就是它的原始值,但是在查看Span對象的時候,我們看到的是通過toString()函數(shù)處理過的值,從sleuth的Span源碼中我們可以看到如下定義,在輸出Trace ID和Span ID時都調(diào)用了idToHex函數(shù)將long類型的值轉(zhuǎn)換成了16進制的字符串值,所以在DEBUG時我們會看到兩個不一樣的值。
- public String toString() {
- return "[Trace: " + idToHex(this.traceId) + ", Span: " + idToHex(this.spanId)
- + ", Parent: " + getParentIdIfPresent() + ", exportable:" + this.exportable + "]";
- }
- public static String idToHex(long id) {
- return Long.toHexString(id);
- }
在接收到Sleuth之后我們將程序繼續(xù)執(zhí)行下去,可以看到經(jīng)過轉(zhuǎn)換后的Zipkin的Span內(nèi)容,它們保存在一個名為converted的列表中,具體內(nèi)容如下所示:


上圖展示了轉(zhuǎn)換后的Zipkin Span對象的詳細內(nèi)容,我們可以看到很多熟悉的名稱,也就是之前我們介紹的關于zipkin中的各個基本概念,而這些基本概念的值我們也都可以在之前sleuth的原始span中找到,其中annotations和binaryAnnotations有一些特殊,在sleuth定義的span中沒有使用相同的名稱,而是使用了logs和tags來命名。從這里的詳細信息中,我們可以直觀的看到annotations和binaryAnnotations的作用,其中annotations中存儲了當前Span包含的各種事件狀態(tài)以及對應事件狀態(tài)的時間戳,而binaryAnnotations則存儲了對事件的補充信息,比如上圖中存儲的就是該HTTP請求的細節(jié)描述信息,除此之外,它也可以存儲對調(diào)用函數(shù)的詳細描述(如下圖所示)。

下面我們再來詳細看看通過調(diào)試消息監(jiān)聽程序接收到的這5個Span內(nèi)容。首先,我們可以發(fā)現(xiàn)每個Span中都包含有3個ID信息,其中除了標識Span自身的ID以及用來標識整條鏈路的traceId之外,還有一個之前沒有提過的parentId,它是用來標識各Span父子關系的ID(它的值來自與上一步執(zhí)行單元Span的ID) ,通過parentId的定義我們可以為每個Span找到它的前置節(jié)點,從而定位每個Span在請求調(diào)用鏈中的確切位置。在每條調(diào)用鏈路中都有一個特殊的Span,它的parentId為null,這類Span我們稱它為Root Span,也就是這條請求調(diào)用鏈的根節(jié)點。為了弄清楚這些Span之間的關系,我們可以從Root Span開始來整理出整條鏈路的Span內(nèi)容。下表展示了我們從Root Span開始,根據(jù)各個Span的父子關系***整理出的結(jié)果:
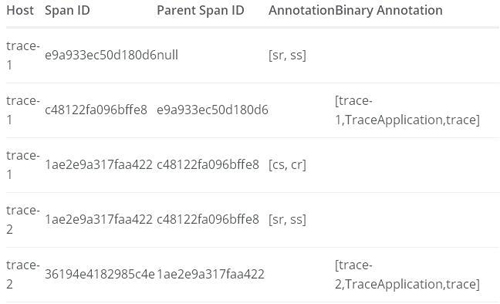
上表中的Host代表了該Span是從哪個應用發(fā)送過來的;Span ID是當前Span的唯一標識;Parent Span ID代表了上一執(zhí)行單元的Span ID;Annotation代表了該Span中記錄的事件(這里主要用來記錄HTTP請求的四個階段,表中內(nèi)容作了省略處理,只記錄了Annotation名稱(sr代表服務端接收請求,ss代表服務端發(fā)送請求,cs代表客戶端發(fā)送請求,cr代表客戶端接收請求),省略了一些其他細節(jié)信息,比如服務名、時間戳、IP地址、端口號等信息);Binary Annotation代表了事件的補充信息(Sleuth的原始Span記錄更為詳細,Zipkin的Span處理后會去掉一些內(nèi)容,對于有Annotation標識的信息,不再使用Binary Annotation補充,在上表中我們只記錄了服務名、類名、方法名,同樣省略了一些其他信息,比如:時間戳、IP地址、端口號等信息)。
通過收集到的Zipkin Span詳細信息,我們很容易的可以將它們與本節(jié)開始時介紹的一次調(diào)用鏈路中的10個標簽內(nèi)容聯(lián)系起來:
- Span ID = T的標簽有2個,分別是序號1和10,它們分別表示這次請求的開始和結(jié)束。它們對應了上表中ID為e9a933ec50d180d6的Span,該Span的內(nèi)容在標簽10執(zhí)行結(jié)束后,由trace-1將標簽1和10合并成一個Span發(fā)送給Zipkin Server。
- Span ID = A的標簽有2個,分別是序號2和9,它們分別表示了trace-1請求接收后,具體處理方法調(diào)用的開始和結(jié)束。該Span的內(nèi)容在標簽9執(zhí)行結(jié)束后,由trace-1將標簽2和9合并成一個Span發(fā)送給Zipkin Server。
- Span ID = B的標簽有4個,分別是序號3、4、7、8,該Span比較特殊,它的產(chǎn)生跨越了兩個實例,其中標簽3和8是由trace-1生成的,而標簽4和7則是由trace-2生成的,所以該標簽會拆分成兩個Span內(nèi)容發(fā)送給Zipkin Server。trace-1會在標簽8結(jié)束的時候?qū)撕?和8合并成一個Span發(fā)送給Zipkin Server,而trace-2會在標簽7結(jié)束的時候?qū)撕?和7合并成一個Span發(fā)送給Zipkin Server。
- Span ID = C的標簽有2個,分別是序號5和6,它們分別表示了trace-2請求接收后,具體處理方法調(diào)用的開始和結(jié)束。該Span的內(nèi)容在標簽6執(zhí)行結(jié)束后,由trace-2將標簽2和9合并成一個Span發(fā)送給Zipkin Server。
所以,根據(jù)上面的分析,Zipkin總共會收到5個Span:一個Span T,一個Span A,兩個Span B,一個Span C。結(jié)合之前請求鏈路的標簽圖和這里的Span記錄,我們可以總結(jié)出如下圖所示的Span收集過程,讀者可以參照此圖來理解Span收集過程的處理邏輯以及各個Span之間的關系。
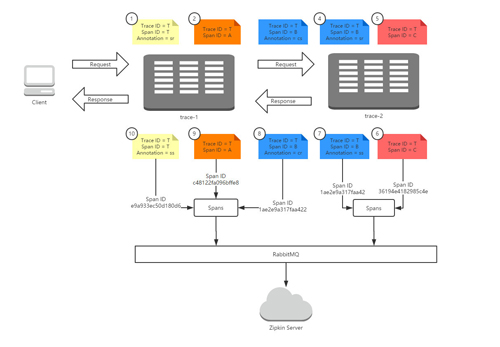
雖然,Zipkin服務端接收到了5個Span,但就如前文中分析的那樣,其中有兩個Span ID=B的標簽,由于它們來自于同一個HTTP請求(trace-1對trace-2的服務調(diào)用),概念上它們屬于同一個工作單元,因此Zipkin服務端在前端展現(xiàn)分析詳情時會將這兩個Span合并了來顯示,而合并后的Span數(shù)量就是在請求鏈路詳情頁面中Total Spans的數(shù)量。
下圖是本章示例的一個請求鏈路詳情頁面,在頁面中顯示了各個Span的延遲統(tǒng)計,其中第三條Span信息就是trace-1對trace-2的HTTP請求調(diào)用,通過點擊它可以查看該Span的詳細信息,點擊后會以模態(tài)框的方式彈出Span詳細信息(如圖下半部分),在彈出框中詳細展示了Span的Annotation和BinaryAnnotation信息,在Annotation區(qū)域我們可以看到它同時包含了trace-1和trace-2發(fā)送的Span信息,而在BinaryAnnotation區(qū)域則展示了該HTTP請求的詳細信息。
完整示例:
讀者可以根據(jù)喜好選擇下面的兩個倉庫中查看trace-1和trace-2兩個項目:
Github:https://github.com/dyc87112/SpringCloud-Learning/
Gitee:https://gitee.com/didispace/SpringCloud-Learning/
【本文為51CTO專欄作者“翟永超”的原創(chuàng)稿件,轉(zhuǎn)載請通過51CTO聯(lián)系作者獲取授權(quán)】