數據流時代,Teads如何做到每天賦予1000億事件價值?
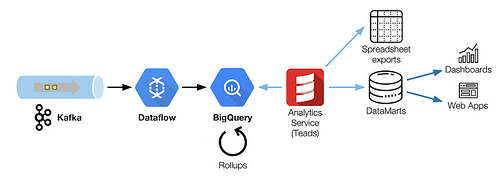
在這篇文章中,我們描述了如何協調Kafka,Dataflow和BigQuery共同采集和轉換大數據流。當增加了模式和延時的約束時,調優和重新排序成了很大的挑戰,下面展示了我們是如何解決它的。
發布者Tead是由Analytics提供支持的web應用之一
在數字廣告中,日常運營產生了許多我們需要跟蹤的事件,以便透明地報道活動的效益。這些事件來自:
用戶與廣告互動,通過瀏覽器發送。這些事件被稱為可以標準化的(開始、完成、暫停、回復等)跟蹤事件,或者使用Teads Studio構建的具有互動創意的自定義事件。我們每天收到大約100億個跟蹤事件。
來自我們的后端這些事件都是關于廣告拍賣的大部分(實時出價流程)細節。在抽樣之前我們每天產生的這些事件超過600億,在2018年這個數字將翻一番。
在這篇文章中,我們聚焦于跟蹤事件,因為它們是我們業務上最關鍵部分的。
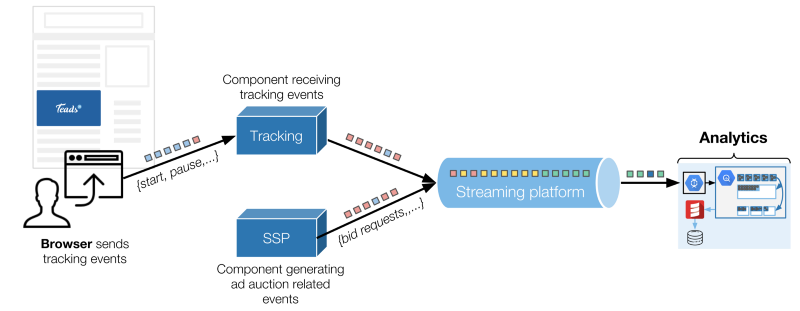
簡單概述了我們技術環境的兩個主要事件源
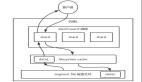
瀏覽器通過HTTP將跟蹤數據發送到一個專用組件,其他的事情都列進了Kafka的topic中。Analytics是這些事件的服務對象之一。
我們用一個Analytics小組,他們的任務是按照如下定義管理這些事件:
- 我們獲取了log的增長量,
- 我們將它們轉化成面向業務的數據
- 我們為每一位顧客提供高效且定制的服務。
為了完成這個任務,我們建立和維護了一系列處理工具和管道。由于公司的有機增長和新產品的需求,我們定期挑戰我們的結構。
為什么我們移向了BigQuery
回顧2016年,我們的Analytics跟蹤基于lambda architecture系統架構(Storm、 Spark和Cassandra項目),并且出現了一些問題:
- 數據的模式使它不可能存放在單一的Cassandra表中,這會妨礙高效的交叉查詢,
- 它是一個復雜的基礎框架,在批處理和速度層都會出現代碼復制,這阻礙了我們新功能的高效發布,
- 最終它將難以發展且不具有成本效益。
這時候,我們有了幾種可能的選擇。首先,我們可以建立一個增強的lambda,但它只能推遲我們要面臨的問題。
我們考慮了幾個有前景的替代品,像Druid何BigQuery。我們最終選擇遷移到BiQuery,因為他有很多強大的功能。
通過BigQuery我們能夠:
- 工作在原始事件,
- 使用SQL作為高效的數據處理語言,
- 使用BigQuery作為處理引擎,
- 使解釋性訪問數據更容易(相比Spark SQL或者Hive)
感謝flat-rate計劃,我們高強度的用法(查詢和存儲方式)是具有高成本效益的。
然而,我們的技術環境不適合BigQuery。我們想用它來存儲和轉換來自多個Kafka topic 的所有事件。我們無法讓我們的Kafka群組移出AWS,也無法使用與Kafka托管等效的Pub/Sub,因為這些群集也被我們托管在AWS上的一些廣告投放組件使用。因此,我們不得不處理來自運營的多云基礎框架的挑戰。
今天,BigQuery是我們的數據倉庫系統,用于我們的跟蹤數據與其他的原始數據的協調核對。
獲取
當處理追蹤事件的時候,你面對的首要問題就是,你必須在不知道延遲的情況下無序地處理他們。
事件實際發生的時間(事件觸發時間,event time)和系統注意到這個事件的時間(處理時間,processing time)之間的時間間隔的范圍涵蓋了從毫秒級到小時級。這些巨大的延遲并不罕見,而且當用戶在瀏覽會話的時間中間連接斷開了或者開啟了飛行模式,就會出現這種情況。
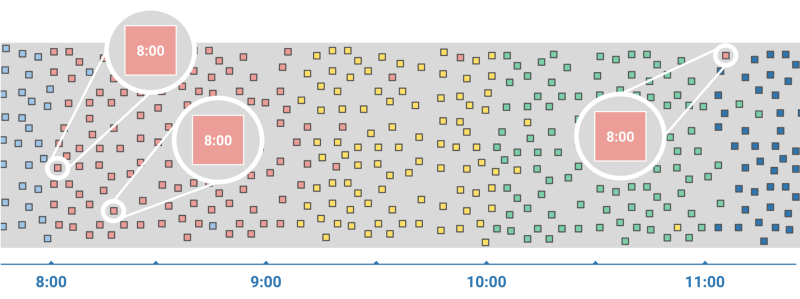
事件觸發時間和處理時間的時間差
如果要獲取流數據處理遇到的問題相關更多信息,我們建議去看Google Cloud Next’17 中Tyler Akidau(Google數據處理技術主管)和 Loïc Jaures(Teads的共同創始人和技術部高級副總裁)討論《批處理和流處理之間的來回轉換》。本文就是受到這個討論的啟發。
流的嚴酷現實
Dataflow是一個管理流系統,為了應對我們面對的事件的混亂本質的挑戰而生。Dataflow有一個統一的流和批處理編程模型,流是它的主推特性。
由于Dataflow的承諾和對流模式的大膽嘗試,我們購買了它。不幸的是,在面對真實生產環境的數據傳輸,我們感到了驚駭:BigQuery的流插入代價。
我們對壓縮數據大小(即,通過網絡的字節的實際數據卷)和非BigQuery的原始數據格式大小已經有了基本估算。幸運的是現在已經為每個數據類型提供了文檔,因此你也可以做計算。
那時候,我們低估了這個額外代價的100倍,這幾乎是我們整個獲取渠道(Dataflow + BigQuery)的兩倍代價。我們也遇到了其他的局限,例如100,000 events/s 速率限制,這已經幾乎接近我們在做的事情了。
好消息是,有一種方法可以完全避免流插入限制:批量加載到BigQuery。
理想情況下,我們希望在流模式中使用Dataflow,在批處理模式下使用BigQuery。在那個時候,Dataflow SDK中沒有用于無限制數據流的BigQuery批處理接收器。
然后我們考慮開發自己的自定義接收器。不幸的是,當時不可能在無限制的數據流中添加一個自定義的接收器(見Dataflow計劃為在將來的版本中增加對編寫無界數據的自定義接收器的支持——現在這是有可能的,Beam是官方的Dataflow SDK)。
我們別無選擇,只能把我們的數據轉換成批處理模式。由于Dataflow的統一模型,這僅僅是幾行代碼的問題。幸運的是,我們可以接收由切換到批處理模式所引入的額外數據處理延遲。
繼續向前推進,我們目前的接入架構是基于Scio,這是一個由Spotify提供的Dataflow開源的Scala API。如前所述,Dataflow原生支持Pub/Sub,但集成Kafka還不太成熟。我們必須擴展Scio以支持檢查點持久性和有效的并行性。
微型的批處理管道
我們的結果處理架構是一個30個節點的Dataflow批處理作業的鏈,按順序排列,讀取Kafka topic,并使用加載作業來寫入BigQuery。
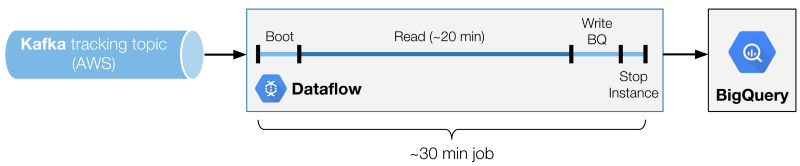
數據流小批量處理的多個階段。
其中一個關鍵是找到理想的分批時間。我們發現在成本和讀取性能之間有一個最佳的平衡點(因此延遲)。調整的變量是Kafka讀取階段的持續時間。
要得到完整的批處理時間,您必須將寫入操作添加到BigQuery階段也算在里面(不是成比例增加的,而是與讀操作時間密切相關),再加上一個常量,也就是啟動和關閉消耗的時間。
值得一提:
- 讀取階段太短會降低讀取和非讀取階段之間的比例。在一個理想的情況下,1:1的比值意味著你必須能夠以同樣的速度進行讀取和寫入。在上面的例子中,我們有20分鐘的讀取階段,對一個30分鐘的批處理(比值為3:2)。這意味著我們必須能夠在讀取數據時比我們寫入數據的速度快1.5倍。小的比值意味著需要更大的實例。
- 過長的讀取階段將簡單地增加事件的發生時刻與BigQuery中其可用的時刻之間的延遲。
性能調優
為簡便以及更易于失敗管理,數據流作業按順序啟動。這是我們愿意采取的延遲所做的折衷。如果某項作業失敗了,我們只需返回上次所提交的Kafka偏移即可。
我們必須修改我們的Kafka集群的拓撲結構,并增加分區的數量,以便能夠更快地unstack消息。根據你在Dataflow中所進行的轉換,受限的因素很可能是在處理能力或網絡吞吐量上。為了實現高效的并行,你應該始終嘗試保留大量CPU線程,這個數字是你所擁有的分區數量的一個因子(推論:Kafka分區的數量是多因子合數,這是很不錯的)。
在極少數的延遲情況下,我們可以用較長的讀取序列對作業進行微調。通過使用更大的批處理,我們也能夠以延遲為代價來趕上這類延遲。
為了處理大部分情況,我們調整Dataflow使其讀取速度以比實際速度快3倍。用單個n1-highcpu-16實例讀取20分鐘可以unstack 60分鐘的消息。
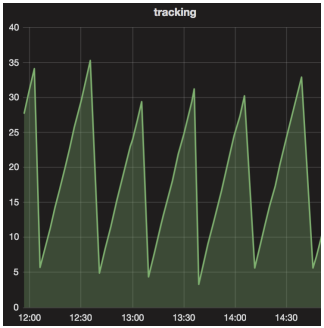
隨著時間變化的攝取延時(單位:分鐘)
在我們的用例中,我們最終得到的鋸齒式延遲,震蕩范圍在3分鐘(Write BQ階段的最小時長)和30分鐘(作業的總時長)之間。
轉換
原始數據是不可避免地體積龐大,我們有太多的事件,并照目前狀態無法查詢它們。我們需要匯總這些原始數據以保持較低的讀取時間和緊湊的體積大小。以下是我們在BigQuery中的做法:
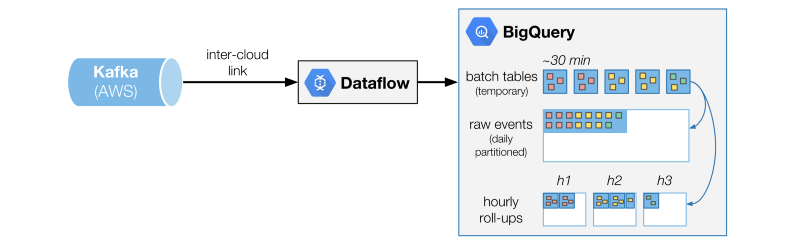
跨AWS和GCP的架構綜述
與傳統ETL過程中數據在加載之前進行轉換不同的是,我們選擇以原始格式首先存儲它(ELT)。
它有兩個主要的好處:
- 它讓我們可以訪問每一個原始事件以進行精確的分析和調試,
- 它通過讓BigQuery用簡單但強大的SQL方言完成轉換來簡化整個鏈。
我們希望直接寫入每天分區的原始事件表。我們不能因為Dataflow批處理就必須使用特定的目標(表或分區)來定義,并且可以包含針對不同分區的數據。我們通過將每個批裝載到一個臨時表中來解決這個問題,然后開始轉換它。
對于這些臨時批處理表,我們運行一組轉換,這些轉換被具體化成SQL查詢,輸出到其他表。其中一個轉換只是將所有數據附加到大型原始事件表,并在白天進行分區。
另一個轉換是rollup:給定一組維度數據的聚合。所有這些轉換都是冪等的,可以在錯誤或需要進行數據再處理的情況下安全地重新運行。
Rollups
直接查詢原始事件表是很好的調試,也有利于深入分析,但是直接查詢原始表不可能達到可接受的性能,更不用說這種操作的成本了。
為了給你一個想法,這個表格只保留了4個月,包含1萬億個事件,大小接近250TB。
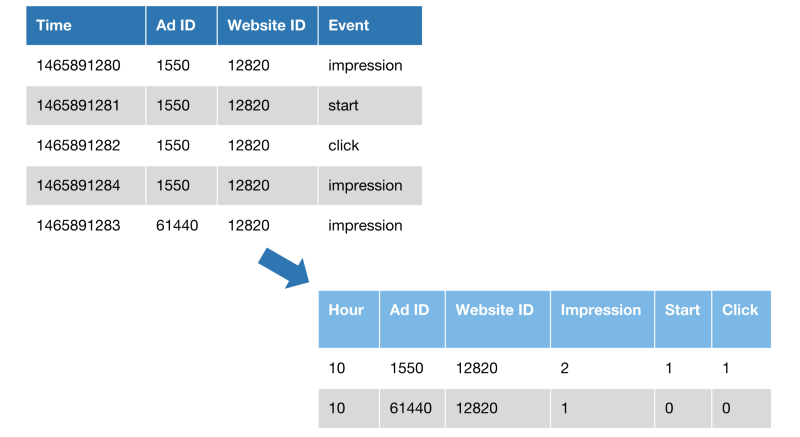
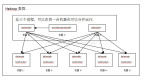
rollup轉換的示例。
在上面的示例中,我們將事件計數設置為3個維度:小時、Ad ID、網站ID。事件也被旋轉并轉換為列。該示例顯示了2.5x的減少,而實際情況則接近70x。
在BigQuery大型并行上下文中,查詢運行時不會受到太大影響,改進是根據使用的槽數來衡量的。
Rollups還讓我們將數據劃分為小塊:事件被分組到小的表中,每一個小時(事件時間的小時,而不是處理時間)。因此,如果您需要查詢給定小時的數據,您將查詢單個表(<10M行,<10GB)。
Rollups是一種通用的聚合,我們可以更有效地查詢所有事件,給定了大量的維度。還有一些其他的用例,我們希望對數據有專門的視圖。它們每個都可以實現一組特定的轉換,最終得到一個專門的和優化的表。
管理服務的限制
BigQuery,雖然功能很強大但是也存在限制:
- BigQuery不允許查詢具有不同模式(即使查詢沒使用不同的字段)的多個表。當我們需要添加一個字段,我們用一個腳本來做上百個表的批量更新。
- BigQuery不支持列刪除。沒什么大不了的,因為這對技術而言沒什么負擔。
- 查詢多個小時:BigQuery的表名支持通配符,但是性能非常差,我們生成查詢的時候,需要使用UNION ALL來明確要查詢的每張表。
- 我們總是需要連接帶有托管在其他數據庫(例如,給事件提供更多的廣告活動信息)上數據的這些事件,但是BigQuery也不支持這個。我們現在不得不定期把完整的表拷貝到BigQuery上,以便能在單個查詢中做數據連接。
云間數據傳輸的樂趣
通過在AWS中Teads的廣告投放基礎設施和Kafka群組來與其它組件共享,我們別無選擇,只能在AWS和GCP云之間移動大量數據,當然這不容易,無疑也不會便宜。我們將Dataflow實例(這主要的是GCP的切入點)盡可能靠近放置在我們的AWS基礎設施旁邊。幸運的是,AWS和GCP之間的連接足夠好,以至于我們可以簡便的使用托管的VPN。
雖然我們運行這些VPN遇到了一些不穩定性,但我們想辦法整理出了一個簡單的腳本,用來再一次的打開和關閉VPN。我們從未面對過一個足夠巨大的問題來證明專用鏈路的成本。
又一次,費用成了你不得不密切關注的事情,出口是令人擔憂的,在你看到賬單之前費用是難以估計的。為了壓縮成本,你需要仔細選擇壓縮數據的方法。
只有一半
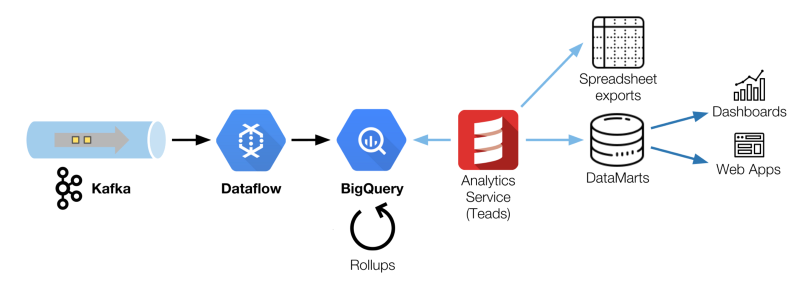
分析大局
在BigQuery中所擁有的這些事件是不夠的。為了給業務帶來價值,數據必須與不同的規則和度量相結合。此外,BigQuery不適合實時用例。
由于并發限制和不可壓縮的查詢延遲3到5秒(可接受和固有的設計),BigQuery必須與其他工具混合,以服務應用程序(指示板、web ui等)。
這個任務由我們的分析服務來執行,它是一個Scala組件,它利用BigQuery來生成按需報告(電子表格)和定制的數據集市(每日或每小時更新)。
我們選擇了AWS Redshift來存儲和服務我們的數據集市。盡管服務于面向用戶的應用程序似乎不是一個清晰的選擇,但Redshift對我們很適用,因為我們的并發用戶數量是有限的。
另外,使用鍵/值存儲器需要更多的開發工作。通過保持中間的關系數據庫,數據集市的消費變得更容易了。
關于如何規劃化地構建、維護和查詢這些數據集市,這會有很多話題,但他們將成為另一篇文章的主題。