













WOT講師王東:基于實時敏捷大數據理念,構建DBus+Wormhole兩大基礎平臺
原創【51CTO.com原創稿件】七年一劍,華麗蛻變。自2012年起連續6年15場峰會,凝聚大量技術專家,博觀而約取,厚積而薄發。2018WOT全球軟件與運維技術峰會揚帆起航,圍繞12大核心熱點,匯聚海內外60位一線專家,打造高端技術盛宴!
在“大數據處理技術”分論壇現場中,宜信技術研發中心高級架構師王東將給聽眾帶來一場名為《實時敏捷大數據在宜信的實踐及開源平臺DBus+Wormhole》的主題演講。在會前,51CTO記者采訪到了他,請他提前“劇透” ,精彩演講內容就讓我們“先睹為快”吧!

王東,宜信技術研發中心高級架構師,主要負責日志歸集、流式處理和大數據業務產品解決方案,包括實時敏捷大數據技術棧基礎組件——DBus實時數據總線平臺的建設和NLP技術解決方案的建設和探索等。王東擁有多年從事分布式數據庫引擎研發經驗,在加入宜信之前,曾就職于Naver(韓國***搜索引擎公司),擔任中國研發中心資深研發工程師,負責開源項目CUBRID-cluster分布式數據庫開發和CUBRID數據庫引擎開發工作。
用戶對實時敏捷大數據的要求越發強烈
大數據發展到今天,越來越多的實時業務場景涌現,通過流式處理技術實現數據的實時化和從數據中快速發現價值成為趨勢。但是,流式處理的實施存在較大難度,包括:人才短缺、開發成本高、上線周期長等,這就導致實時敏捷大數據的要求越發強烈,如何低成本、快速落地數據產品成為很多公司考慮的問題。
王東告訴記者,宜信也面臨著相同的需求和痛點,遇到了同樣的挑戰。在過去兩年中,宜信通過建設實時敏捷大數據DBus(實時數據總線平臺)和Wormhole(實時數據交換平臺)兩個基礎服務平臺,使得實時數據能力和快速實施數據產品能力得到了大幅提升。
據介紹,實時敏捷大數據技術棧組件DBus和Wormhole已經在宜信公司內部宜人貸、大數據創新中心、技術研發中心等多個一級技術部門作為基礎設施提供服務,并于2017年9月開源。目前,這兩個基礎服務平臺一直在維護和迭代中,一些社區用戶和企業用戶也在試用和使用中。
基于實時敏捷大數據理念構建的兩大基礎平臺
前面提到,用戶對實時敏捷大數據的要求越發強烈。在本次大會中,王東將結合宜信在實時敏捷大數據方面遇到了問題、需求和挑戰等,從多個維度進行分享。
王東表示,大數據應用要快速落地,除了建立大數據思維和數據驅動業務為導向之外,還面臨著諸多挑戰:
一)大數據技術生態體系龐雜,技術門檻高,需要對大數據技術、架構、算法、業務都懂行的復合型人才;
二)傳統商業智能BI應用的失敗教訓多,存在項目周期漫長、成本高、數據用戶參與度低、考驗客戶耐性等諸多問題,且并沒有從BI實施中獲得更多的成功經驗;
三)大數據應用的標準化和產品化問題。數據的動態性、時效性、多樣性怎么進行標準化管理,離線分析、在線分析、實時分析如何融合等。
基于此,宜信對實時敏捷大數據提出了自己的理解:
一)數據是實時計算和實時流轉的;
二)通過組件平臺化的方式,提供平臺服務,讓數據從業者能夠更多介入并釋放數據處理能力,回歸數據和業務本質;
三)通過接口標準化方式,使得數據能夠在不同組件之間輕松流轉;
四)通過可視化的方式進行配置,降低大數據產品開發門檻,同時降低運維成本;
五)基于SQL的方式來實現自助化,能夠快速原型驗證,與需求方形成反饋閉環快速迭代,證明有效,從實踐中快速沉淀大數據產品。
以上,通過實時化、組件化、標準化、可視化和自助化的方式提供技術平臺,實現大數據的快速實施、快速驗證、快速迭代,從而達到讓大數據應用快速落地,實現商業價值。
王東告訴記者,宜信在數據流轉中存在一些問題和痛點,包括數據孤島的問題,數據時效性差、一致性差的問題,無法快速響應業務需求開發數據產品的問題,運維實時數據產品困難等問題。業務方希望方案能夠滿足低延時、高實時性、接入方案侵入性小、能夠快速開發數據產品、運維成本低、數據安全和權限高等。并且,要求方案能夠接受定制化,實現數據存儲多樣化和支持多種目標,例如HDFS、BASE、ES、Mongo、MySQL等。
宜信基于對實時敏捷大數據的理念,構建了DBus實時數據總線平臺 + Wormhole實時流式處理平臺。其中,DBus作為實時數據總線平臺,關注數據的抓取和結構化;Wormhole作為實時流式處理平臺,提供基于配置SQL的方式進行各種流式計算,并支持落庫到各種常見數據目標中。
王東表示,考慮到參會者大都具有技術背景,因此他將從技術層面具體介紹這兩個平臺的內部架構,重點介紹DBus和Wormhole這兩個平臺的關鍵實現原理,例如:DBus 數據增量數據如何生成,全量數據如何切片;Wormhole平臺中數據如何進行流式計算優化,如何高效落庫等。并結合應用場景,對這兩個平臺解決的一些實際問題進行介紹,包括:實時營銷、實時運營和數倉同步等。
結合場景應用的DBus+Wormhole流式處理引擎
大數據處理技術是一個很大的話題,涉及到數據采集、數據流轉、數據處理、數據存儲、數據展示等諸多方面,包含批次、流式、AdHoc 、預算等各種訪問模式。在實時流式計算方面,考慮到各種計算引擎的特點和適合的場景,DBus+Wormhole采用了不同流式處理引擎。
王東表示,業界流式處理的引擎不少,例如:Storm,Spark Stream,Flink,Samza,Kafka Streams 等。如何選擇流式處理引擎,先要考慮各種計算引擎的特點和適合場景。
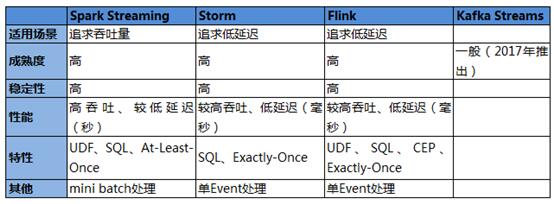
各種流式計算引擎的優缺點
據介紹,自2016年開始,宜信就啟動了兩大平臺的建設,考慮到當時社區比較成熟的情況,DBus和Wormhole兩個平臺各自選擇了不同的流式處理引擎。
DBus關注數據源的數據流出,希望以較低的延遲讓后端用戶更快的消費到***數據,盡可能的保證數據順序性。因此,DBus采用了storm作為處理引擎。Wormhole關注數據的實時流轉和實時落庫。對于數據流轉來說,最早支持SQL比較好的是spark;另外,從落庫的角度來說,以批量的方式落庫比單條落庫效率要高很多。因此,Wormhole采用Spark Streaming作為處理引擎。
在保證數據一致性方面,需要在整個設計過程中考慮計算引擎支持這一要點,否則會出現數據亂序的情況。宜信采用了讓DBus保證輸出的每條日志數據是唯一標示和順序性ums_id的方案。為了做到這一點,DBus采用了物理文件編號和日志偏移量作為基礎,保證了即便DBus重做數據的ums_id_,都不會改變。此外,Ums_id_的唯一性和順序性帶來了諸多好處,比如Wormhole落庫時,通過比較ums_id_就能知道哪條數據更新過,哪條數據會被覆蓋等。
另外,作為流式Extract-Transform-Load 工具,DBus和Wormhole還做出許多額外的努力。首先,作為數據的采集方(Extract), DBus為了減少對數據源端的侵入性和實時性,沒有用trigger或時間戳的方式抽取增量數據,采用了通過讀取數據庫備庫日志的方式獲得增量數據。為此,不同的數據源采用了不同的解決方案。同時,DBus還實現了數據源端schema變更自動感知的能力,區分兼容性變更和非兼容性變更,自動將變更體現在UMS的版本上,并提供郵件通知報警的功能。
對于數據的實時轉換(Transform),為了提高流上Spark SQL Join性能低下和Join不到的問題,Wormhole重新實現了流上join的邏輯,大幅提高了流上join的性能。并且,引入了時間窗口的概念,對于沒有lookup到的數據選擇在時間窗內,隨同下一批mini batch的數據再次進行join,最終提高join的成功率。
為了更有效的落庫裝載(Load),Wormhole首先基于主鍵對batch數據進行repartition,這樣合并了不需要的寫入,減少了寫入量的同時也避免了死鎖。另外,采用基于batch和基于預讀的邏輯,大幅提高了batch的寫入性能。
***,在流式處理過程中,如何驗證整個鏈路數據的暢通性、時效性,在沒有數據的情況下如何知道整條鏈路是正常工作的?DBus從源端引入了心跳機制,通過定時向源端插入心跳數據,并沿路進行實時捕獲。整條鏈路從抓取到轉換和最終落庫,都提供實時監控和預警,保證在即使沒有任何用戶數據的情況下,心跳數據也在實時探活和自我證明,進行自我預警和實時監控。
5 月 18 - 19日,北京•粵財JW萬豪酒店,全球最值得關注的IT技術盛宴與您不見不散。2018WOT全球軟件與運維技術峰會一定是您發現全新思路、挖掘***思想、拓展人脈的重要平臺。
目前我們的各項票種已全面發售。需要提醒您的是,購票越早,折扣越大!與KOL零距離交流,呈現不一樣的“英雄盛宴”!
點擊官網了解詳情:wot.51cto.com
7折預售中,搶票從速。






















