













RNN和LSTM弱爆了!注意力模型才是王道!
循環神經網絡(RNN),長短期記憶(LSTM),這些紅得發紫的神經網絡——是時候拋棄它們了!LSTM和RNN被發明于上世紀80、90年代,于2014年死而復生。接下來的幾年里,它們成為了解決序列學習、序列轉換(seq2seq)的方式,這也使得語音到文本識別和Siri、Cortana、Google語音助理、Alexa的能力得到驚人的提升。
另外,不要忘了機器翻譯,包括將文檔翻譯成不同的語言,或者是神經網絡機器翻譯還可以將圖像翻譯為文本,文字到圖像和字幕視頻等等。
在接下來的幾年里,ResNet出現了。ResNet是殘差網絡,意為訓練更深的模型。2016年,微軟亞洲研究院的一組研究員在ImageNet圖像識別挑戰賽中憑借驚人的152層深層殘差網絡(deep residual networks),以絕對優勢獲得圖像分類、圖像定位以及圖像檢測全部三個主要項目的冠軍。之后,Attention(注意力)模型出現了。
雖然僅僅過去兩年,但今天我們可以肯定地說:
- “不要再用RNN和LSTM了,它們已經不行了!”
讓我們用事實說話。Google、Facebook、Salesforce等企業越來越多地使用了基于注意力模型(Attention)的網絡。
所有這些企業已經將RNN及其變種替換為基于注意力的模型,而這僅僅是個開始。比起基于注意力的模型,RNN需要更多的資源來訓練和運行。RNN命不久矣。
為什么
記住RNN和LSTM及其衍生主要是隨著時間推移進行順序處理。請參閱下圖中的水平箭頭:
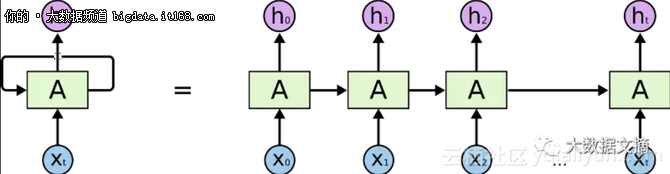
▲RNN中的順序處理
水平箭頭的意思是長期信息需在進入當前處理單元前順序遍歷所有單元。這意味著其能輕易被乘以很多次<0的小數而損壞。這是導致vanishing gradients(梯度消失)問題的原因。
為此,今天被視為救星的LSTM模型出現了,有點像ResNet模型,可以繞過單元從而記住更長的時間步驟。因此,LSTM可以消除一些梯度消失的問題。
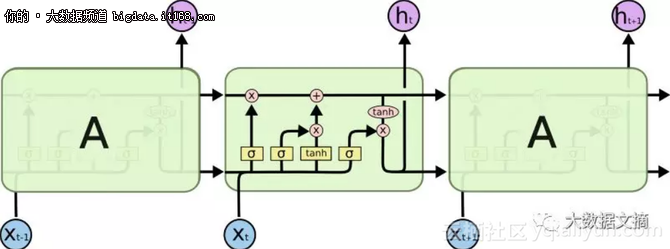
▲LSTM中的順序處理
從上圖可以看出,這并沒有解決全部問題。我們仍然有一條從過去單元到當前單元的順序路徑。事實上,這條路現在更復雜了,因為它有附加物,并且忽略了隸屬于它上面的分支。
毫無疑問LSTM和GRU(Gated Recurrent Uni,是LSTM的衍生)及其衍生能夠記住大量更長期的信息!但是它們只能記住100個量級的序列,而不是1000個量級,或者更長的序列。
還有一個RNN的問題是,訓練它們對硬件的要求非常高。另外,在我們不需要訓練這些網絡快速的情況下,它仍需要大量資源。同樣在云中運行這些模型也需要很多資源。
考慮到語音到文本的需求正在迅速增長,云是不可擴展的。我們需要在邊緣處進行處理,比如Amazon Echo上處理數據。
該做什么?
如果要避免順序處理,那么我們可以找到“前進”或更好“回溯”單元,因為大部分時間我們處理實時因果數據,我們“回顧過去”并想知道其對未來決定的影響(“影響未來”)。在翻譯句子或分析錄制的視頻時并非如此,例如,我們擁有完整的數據,并有足夠的處理時間。這樣的回溯/前進單元是神經網絡注意力(Neural Attention)模型組。
為此,通過結合多個神經網絡注意力模型,“分層神經網絡注意力編碼器”出現了,如下圖所示:
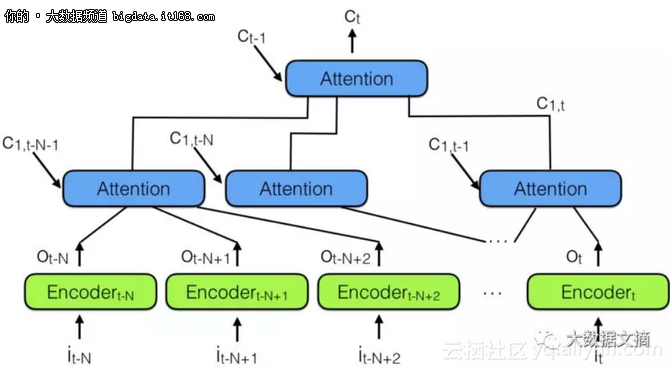
▲分層神經網絡注意力編碼器
“回顧過去”的更好方式是使用注意力模型將過去編碼向量匯總到語境矢量 CT中。
請注意上面有一個注意力模型層次結構,它和神經網絡層次結構非常相似。這也類似于下面的備注3中的時間卷積網絡(TCN)。
在分層神經網絡注意力編碼器中,多個注意力分層可以查看最近過去的一小部分,比如說100個向量,而上面的層可以查看這100個注意力模塊,有效地整合100 x 100個向量的信息。這將分層神經網絡注意力編碼器的能力擴展到10,000個過去的向量。
這才是“回顧過去”并能夠“影響未來”的正確方式!
但更重要的是查看表示向量傳播到網絡輸出所需的路徑長度:在分層網絡中,它與log(N)成正比,其中N是層次結構層數。這與RNN需要做的T步驟形成對比,其中T是要記住的序列的***長度,并且T >> N。
跳過3-4步追溯信息比跳過100步要簡單多了!
這種體系結構跟神經網絡圖靈機很相似,但可以讓神經網絡通過注意力決定從內存中讀出什么。這意味著一個實際的神經網絡將決定哪些過去的向量對未來決策有重要性。
但是存儲到內存怎么樣呢?上述體系結構將所有先前的表示存儲在內存中,這與神經網絡圖靈機(NTM)不同。這可能是相當低效的:考慮將每幀的表示存儲在視頻中——大多數情況下,表示向量不會改變幀到幀,所以我們確實存儲了太多相同的內容!
我們可以做的是添加另一個單元來防止相關數據被存儲。例如,不存儲與以前存儲的向量太相似的向量。但這確實只是一種破解的方法,***的方法是讓應用程序指導哪些向量應該保存或不保存。這是當前研究的重點
看到如此多的公司仍然使用RNN/LSTM進行語音到文本的轉換,我真的十分驚訝。許多人不知道這些網絡是如此低效和不可擴展。
訓練RNN和LSTM的噩夢
RNN和LSTM的訓練是困難的,因為它們需要存儲帶寬綁定計算,這是硬件設計者最糟糕的噩夢,最終限制了神經網絡解決方案的適用性。簡而言之,LSTM需要每個單元4個線性層(MLP層)在每個序列時間步驟中運行。
線性層需要大量的存儲帶寬來計算,事實上,它們不能使用許多計算單元,通常是因為系統沒有足夠的存儲帶寬來滿足計算單元。而且很容易添加更多的計算單元,但是很難增加更多的存儲帶寬(注意芯片上有足夠的線,從處理器到存儲的長電線等)。
因此,RNN/LSTM及其變種不是硬件加速的良好匹配,我們在這里之前和這里都討論過這個問題。一個解決方案將在存儲設備中計算出來,就像我們在FWDNXT上工作的一樣。
總而言之,拋棄RNN吧。注意力模型真的就是你需要的一切!






















