2018數據庫技術發展趨勢
當前,正由IT時代進入DT時代,隨著移動互聯網、物聯網的發展,企業正產生大量的數據,而數據的存儲和組織離不開數據庫技術,更多的公司意識到了數據能夠為公司帶來商業利益,于是如何管理和利用好數據已經變得越來越重要。
挖掘數據的價值,對數據進行分析,讓數據指導決策已經成為很多公司最重要的工作之一,因此選擇合適的數據庫系統對公司的技術發展至關重要。
筆者曾經在某大型互聯網公司負責Hadoop平臺及部分MySQL數據庫的管理,工作中涉及到對DBMS的選型、管理及優化等工作內容,筆者認為,未來數據庫發展將有三大趨勢:
一、數據庫管理技術正在向AI方向發展
由于DBMS的發展越來越快,功能越來越多,需要優化的參數內容也相對更多,而各個公司的應用場景不同,對數據庫的要求也各有特點。傳統DBMS對管理人員要求專業性高,成本也很高,DBMS可以處理大量的數據和復雜的負載工作,但是卻難以管理,因為它們具有數百個配置選項,用于控制諸如用于緩存的內存量以及將數據寫入存儲器等因素。
基于這些原因,一些DBMS與AI的結合相繼出現,例如Oracle提出的自治數據庫的概念,以及“OtterTune”,OtterTune是亞馬遜和卡內基梅隆大學一起開發的機器學習自動化調整DBMS的系統,并公布起設計論文和開源項目,重點解決DBMS長期存在的一些問題:
1、對管理人員專業性要求高;
2、管理成本高;
3、無法實現配置資源***化等一系列問題。
據了解,OtterTune可以自動為DBMS的配置選項找到***的設置方法。
OtterTune目標是使任何人都更容易部署數據庫管理系統,即使是那些在數據庫管理方面沒有任何專業知識的人也可以使用它。
OtterTune與其他DBMS配置工具不同,因為它利用從先前的DBMS部署調整中學到知識。大大減少了調整新的DBMS部署所需的時間和資源。
為此,OtterTune維護了從以前的調優會話收集的調優數據庫。它使用此數據構建機器學習(ML)模型,以捕獲DBMS如何響應不同的配置。OtterTune使用這些模型來指導新應用程序的實驗,推薦改進目標參數的設置(例如,減少延遲或提高吞吐量)。
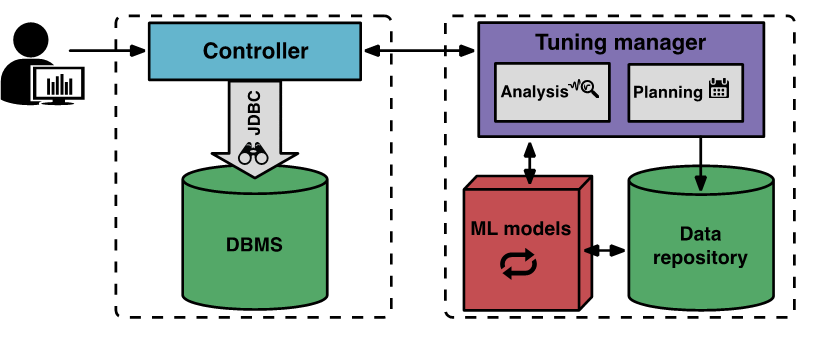
AI與DBMS的結合目前已經開始嘗試,隨著技術的發展,未來應該會變的更加成熟,然而,我并不以為,AI的出現會讓DBA失業,DBA的工作對于數據庫的管理依然非常必要,并且各類AI工具的研發和使用通常也是由經驗豐富的DBA來完成。
例如,我在工作中也曾經通過客戶服務器的硬件配置及業務場景來自動生成大數據系統的配置文件,這在某種意義上也是一種AI的實現,而這個工具的實現是基于DBA平時對系統參數調整的經驗才實現的。
因此,我認為作為DBA應該積極的擁抱技術的變化,嘗試用各種手段來簡化和優化數據庫管理的工作,讓AI等技術成為一個未來的DBA所必備的知識。
二、經歷了NoSQL,NewSQL時代正在到來,融合OLTP和OLAP的HTAP發展迅速。
過去幾年,起源于Google三大基礎設施論文(GFS,Mapreduce和Bigtable),誕生了開源的Hadoop系統,通常用作公司對于海量非結構化數據和結構化數據的存儲及分析,得益于開源社區的貢獻和各大互聯網公司的應用,Hadoop生態系統迅速發展,已經成為了OLAP方面對海量數據處理的事實標準,盡管Hadoop生態系統已經日趨成熟并被業界廣泛認可,然而作為一個離線數據分析系統,Hadoop無法實時對數據的分析提供結果,因此通常用作業務數據庫之外構建一個新的數據倉庫,并且通常僅提供OLAP也就是數據分析方面的支撐,這就要求在傳統的數據庫和Hadoop之間構建一套ETL系統,用作兩者之間數據的導入導出,這就使得數據庫和數據倉庫的管理更加的復雜。
Hadoop系統作為一個龐大的開源系統,往往需要很多組件才能滿足業務的需求,所以我通常認為基于Hadoop構建數據倉庫滿足OLAP的需求目前仍存很多不足,而NoSQL數據庫的不斷發展,也為很多大數據量業務的發展帶來了福音。
例如可以通過Hbase來管理近千億的url數據,并且NoSQL數據庫通常是可以動態擴容并且支持容錯,但是NoSQL系統的缺點也非常的明顯,例如應用場景相對簡單,通常無法兼容傳統的sql語句,多表關聯以及事物等需求也通常無法滿足。對于開發人員還需要重新學習NoSQL的API和使用方式,帶來了額外的代價。
基于上述原因,出現了融合OLTP和OLAP的一種提法HTAP,意味著可以通過一個數據庫系統同時滿足事務性需求和分析型需求,而***代表性的就是Google的Spanner+F1的論文,產生了一批NewSQL系統。
例如CockroachDB和國內PingCAP團隊開發的TiDB,以TiDB為例,TiDB采用Raft實現分布式協議,并且完全兼容MySQL的客戶端,這對筆者本人也非常有吸引力,即可以用熟悉的MySQL的接口,又不需要對數據庫進行分庫分表,既實現了分布式,又減輕了用戶的學習成本,對于企業來講,可以通過構建一套分布式數據庫系統,同時滿足事務性和分析型需求,減輕系統復雜性的同時也提高了效率。
在這里向TiDB團隊致敬,在數據庫領域作出了***的開源項目,可以說是具備里程碑的意義。HTAP將成為未來的數據庫的主流發展趨勢。
三、 時序數據庫正在崛起
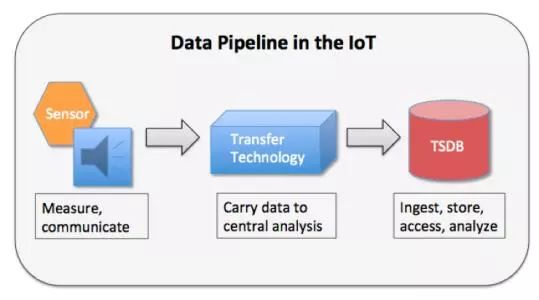
物聯網發展勢頭迅猛,互聯網和傳統公司也爭相布局,隨著物聯網的發展,傳感器等產生了大量的數據,而這些數據往往都是時間順序,在其他一些應用場景,例如金融領域的,股票交易,匯率等以及Devops的監控數據,都是屬于時序數據。
基于這些場景產生了時序數據庫的概念,時序數據庫可以對時間屬性進行特殊的索引,實現數據的快速查詢以及更高的壓縮,例如InfluxDB項目,InfluxDB是一個使用Go語言開發的分布式時序、時間和指標數據庫,無需外部依賴。特別適合處理和分析資源監控數據。
筆者在物聯網項目已經嘗試使用了InfluxDB,用于存儲大型中央空調設備產生的數據,目前項目已經穩定運行半年,與傳統DBMS相比,InflluxDB的存儲空間減少了近70%,存儲和查詢效率也有大幅度提升,并且通過InfluxDB集成的聚合函數和連續查詢功能,可以自動生成數據的日報表、月報表、年報表,極大減輕了開發成本和系統復雜度。
同樣,國內由陶建輝領銜的濤思數據(TAOS Data)團隊也正在做時序數據庫產品TDengine,目前已經開放測試,希望更多的國內團隊做出屬于我們自己的優秀數據庫產品。
四、結語
數據庫作為IT技術架構的核心,新技術層出不窮,隨著物聯網及人工智能時代的到來,數據庫技術迎來高速發展期,DBMS與AI的結合,HTAP以及時序數據庫將解決企業海量數據增長帶來的各種需求及問題。