AI開發(fā)者看過來,主流移動(dòng)端深度學(xué)習(xí)框架大盤點(diǎn)
移動(dòng)設(shè)備相較于 PC ,攜帶便攜,普及率高。近年來,隨著移動(dòng)設(shè)備的廣泛普及與應(yīng)用,在移動(dòng)設(shè)備上使用深度學(xué)習(xí)技術(shù)的需求開始涌現(xiàn)。
作者 dangbo 在《移動(dòng)端深度學(xué)習(xí)展望》一文中對(duì)現(xiàn)階段的移動(dòng)端深度學(xué)習(xí)做了相關(guān)展望。作者認(rèn)為,現(xiàn)階段的移動(dòng)端 APP 主要通過以下兩種模式來使用深度學(xué)習(xí):
- online 方式:移動(dòng)端做初步預(yù)處理,把數(shù)據(jù)傳到服務(wù)器執(zhí)行深度學(xué)習(xí)模型,優(yōu)點(diǎn)是這個(gè)方式部署相對(duì)簡(jiǎn)單,將現(xiàn)成的框架(Caffe,Theano,MXNet,Torch) 做下封裝就可以直接拿來用,服務(wù)器性能大, 能夠處理比較大的模型,缺點(diǎn)是必須聯(lián)網(wǎng)。
- offline 方式:在服務(wù)器上進(jìn)行訓(xùn)練的過程,在手機(jī)上進(jìn)行預(yù)測(cè)的過程。

當(dāng)前移動(dòng)端的三大框架(Caffe2、TensorFlow Lite、Core ML)均使用 offline 方式,該方式可在無需網(wǎng)絡(luò)連接的情況下確保用戶數(shù)據(jù)的私密性。
各主流移動(dòng)端深度學(xué)習(xí)框架誕生時(shí)間如下:
- 2017 年 3 月,XMART LABS 在 GitHub 上開源 Bender
- 2017 年 4 月 19 日,F(xiàn)acebook 在 F8 開發(fā)者大會(huì)上推出 Caffe2
- 2017 年 5 月 17 日,在 Google I/O 2017 大會(huì)上,移動(dòng)端深度學(xué)習(xí)框架 TensorFlow Lite 誕生
- 2017 年 6 月 6 日,蘋果在 WWDC 大會(huì)上推出 Core ML
- 2017 年 9 月 25 日,百度開源移動(dòng)端深度學(xué)習(xí)框架 mobile-deep-learning(MDL)
- ......
接下來,將介紹當(dāng)前主流的移動(dòng)端深度學(xué)習(xí)框架,其中包括移動(dòng)端三大框架——Facebook、谷歌、蘋果三大巨頭發(fā)布的 Caffe2、TensorFlow Lite、Core ML,新秀 Bender,國產(chǎn)百度 MDL 以及支持移動(dòng)端的 MXNet,以便剛剛?cè)肟拥拈_發(fā)者們對(duì)這些框架有初步的了解和認(rèn)識(shí)。
Facebook 開源 Caffe2,最終將其并入 PyTorch

2017 年 4 月 19 日的 F8 年度開發(fā)者大會(huì)上,F(xiàn)acebook 發(fā)布了一款全新的開源深度學(xué)習(xí)框架——Caffe2,按照 Caffe2 官網(wǎng)介紹,它最大的特點(diǎn)就是輕量、模塊化和可擴(kuò)展性,即一次編碼,到處運(yùn)行(和 Java 的宣傳語類似)。說得更直白一點(diǎn),就是 Caffe2 可以方便地為手機(jī)等移動(dòng)終端設(shè)備帶來 AI 加持,讓 AI 從云端走向終端。
Caffe2 在此前流行的開源框架 Caffe 基礎(chǔ)上進(jìn)行了重構(gòu)和升級(jí),一方面集成了諸多新出現(xiàn)的算法和模型,另一方面在保證運(yùn)算性能和可擴(kuò)展性的基礎(chǔ)上,重點(diǎn)加強(qiáng)了框架在輕量級(jí)硬件平臺(tái)的部署能力。它可以部署在包括 iOS,Android,英偉達(dá) Tegra X1 和樹莓派(Raspberry Pi)等在內(nèi)的各種移動(dòng)平臺(tái)上。用戶只需要加載 Caffe2 框架,然后通過幾行簡(jiǎn)單的 API 接口調(diào)用(Python 或 C++),就能在手機(jī) APP 上實(shí)現(xiàn)圖像識(shí)別、自然語言處理和計(jì)算機(jī)視覺等各種 AI 功能。此外,Caffe2 還對(duì) Caffe 平臺(tái)的另一項(xiàng)核心競(jìng)爭(zhēng)力:Model Zoo 社區(qū)方面提供了完整的支持。
除了框架自身,Caffe2 還獲得了一系列的云平臺(tái)支持,例如亞馬遜 AWS 旗下的 Deep Learning AMI和微軟 Azure 旗下 Data Science Virtual Machine (DSVM),另外也獲得了英偉達(dá)和高通的硬件平臺(tái)支持。目前,Caffe2 框架已經(jīng)被 Facebook 內(nèi)部采用,開發(fā)者和研究人員們正在使用該框架提供的各種工具訓(xùn)練大型的機(jī)器學(xué)習(xí)模型,并為 Facebook 旗下的移動(dòng)應(yīng)用提供 AI 智能體驗(yàn)。
現(xiàn)在 Caffe2 代碼也已正式并入 PyTorch,來使 Facebook 能在大規(guī)模服務(wù)器和移動(dòng)端部署時(shí)更流暢地進(jìn)行 AI 研究、訓(xùn)練和推理。
- Caffe2 官網(wǎng):http://Caffe2.ai/
- GitHub 地址:https://github.com/Caffe2/Caffe2
- Caffe2go 移動(dòng)端項(xiàng)目 Github 鏈接: https://github.com/Caffe2/Caffe2
谷歌移動(dòng)端深度學(xué)習(xí)框架 TensorFlow Lite,有望成為移動(dòng)端模型部署推薦解決方案
谷歌于美國時(shí)間 2017 年 11 月 14 日正式發(fā)布 TensorFlow Lite 預(yù)覽版,這一框架主要用于移動(dòng)端和嵌入式設(shè)備,顧名思義,相較于 TensorFlow,TensorFlow Lite 是一個(gè)輕量化版本。這個(gè)開發(fā)框架專門為機(jī)器學(xué)習(xí)模型的低延遲推理做了優(yōu)化,專注于更少的內(nèi)存占用以及更快的運(yùn)行速度。
TensorFlow Lite 具備以下三個(gè)重要功能:
- 輕量級(jí)(Lightweight):支持機(jī)器學(xué)習(xí)模型的推理在較小二進(jìn)制數(shù)下進(jìn)行,能快速初始化/啟動(dòng)
- 跨平臺(tái)(Cross-platform):可以在許多不同的平臺(tái)上運(yùn)行,現(xiàn)在支持 Android 和 iOS
- 快速(Fast):針對(duì)移動(dòng)設(shè)備進(jìn)行了優(yōu)化,包括大大減少了模型加載時(shí)間、支持硬件加速
結(jié)構(gòu)
下圖是 TensorFlow Lite 的結(jié)構(gòu)設(shè)計(jì):
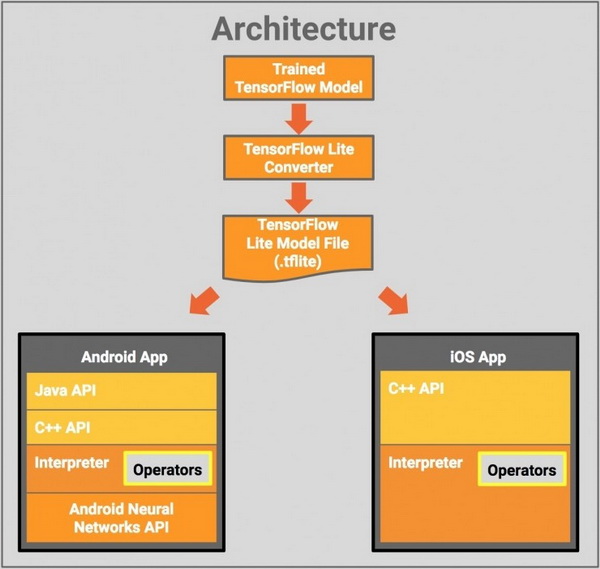
模塊如下:
- TensorFlow Model: 存儲(chǔ)在硬盤上已經(jīng)訓(xùn)練好的 TensorFlow 模型
- TensorFlow Lite Converter: 將模型轉(zhuǎn)換為 TensorFlow Lite 文件格式的程序
- TensorFlow Lite Model File: 基于 FlatBuffers 的模型文件格式,針對(duì)速度和大小進(jìn)行了優(yōu)化。
模型
- TensorFlow Lite 目前支持很多針對(duì)移動(dòng)端訓(xùn)練和優(yōu)化好的模型。
- MobileNet:能夠識(shí)別 1000 種不同對(duì)象類的視覺模型,為實(shí)現(xiàn)移動(dòng)和嵌入式設(shè)備的高效執(zhí)行而設(shè)計(jì)。
- Inception v3:圖像識(shí)別模型,功能與 MobileNet 相似,它提供更高的精度,但相對(duì)來說更大。
- Smart Reply: 設(shè)備對(duì)話模型,可以即時(shí)回復(fù)聊天消息,在 Android Wear 上有使用這一功能。
Inception v3 和 MobileNets 已經(jīng)在 ImageNet 數(shù)據(jù)集上訓(xùn)練了。大家可以利用遷移學(xué)習(xí)來輕松地對(duì)自己的圖像數(shù)據(jù)集進(jìn)行再訓(xùn)練。
TensorFlow Lite 發(fā)布一個(gè)月后,谷歌即宣布與蘋果達(dá)成合作——TensorFlow Lite 將支持 Core ML。TensorFlow Lite 為 Core ML 提供支持后,iOS 開發(fā)者就可以利用 Core ML 的優(yōu)勢(shì)來部署模型。
目前,該框架還在不斷更新與升級(jí)中,隨著 TensorFlow 的用戶群體越來越多,同時(shí)得益于谷歌的背書,假以時(shí)日,TensorFlow Lite 極大可能會(huì)成為在移動(dòng)端和嵌入式設(shè)備上部署模型的推薦解決方案。
- TensorFlow Lite 文檔頁面:http://Tensorflow.org/mobile/tflite
- Core ML 轉(zhuǎn)化器頁面:https://github.com/tf-coreml/tf-coreml
- pypi pip 安裝包地址:https://pypi.python.org/pypi/tfcoreml/0.1.0
蘋果 Core ML:離線狀態(tài)下,隱私與 AI 可兼得。

蘋果在 2017WWDC 大會(huì)更新 iOS 11 時(shí)一并推出了面向開發(fā)者的全新機(jī)器學(xué)習(xí)框架——Core ML,聲稱能讓本地?cái)?shù)據(jù)處理愈加方便快捷。據(jù)介紹,Core ML 提供支持人臉追蹤、人臉檢測(cè)、地標(biāo)、文本檢測(cè)、條碼識(shí)別、物體追蹤、圖像匹配等任務(wù)的 API。
據(jù)了解,Core ML 是一個(gè)基礎(chǔ)機(jī)器學(xué)習(xí)框架,能用于眾多蘋果的產(chǎn)品,包括 Siri、相機(jī)和 QuickType。據(jù)官方介紹,Core ML 帶來了極速的性能提升和機(jī)器學(xué)習(xí)模型的輕松整合,能將眾多機(jī)器學(xué)習(xí)模型集成到 APP 中。它不但有 30 多種層來支持廣泛的深度學(xué)習(xí),而且還支持諸如樹集成、SVM 和廣義線性模型等標(biāo)準(zhǔn)模型。
蘋果在 Core ML 開發(fā)文檔中如此介紹:
- 使用 Core ML,你可以將訓(xùn)練好的模型整合進(jìn)自己開發(fā)的 APP 中。Core ML 支持用于圖像分析的 Vision、用于自然語言處理的 Foundation(如 NSLinguisticTagger 類)和用于評(píng)估已經(jīng)學(xué)習(xí)到的決策樹的 GameplayKit。Core ML 構(gòu)建在 Accelerate、BNNS 和 Metal Performance Shaders 之上。

Core ML 在設(shè)備上嚴(yán)格運(yùn)行,確保了用戶隱私數(shù)據(jù),在無網(wǎng)絡(luò)連接的情況下依然能夠響應(yīng)用戶操作。
CORE ML 相關(guān)技術(shù)
Metal 是針對(duì) iPhone 和 iPad 中 GPU 編程的高度優(yōu)化的框架,Metal 相較 OpenGL ES 能耗顯著降低。另外,Metal 可以預(yù)估 GPU 狀態(tài)來避免多余的驗(yàn)證和編譯
Metal Performance Shader 是蘋果推出的一套借助 Metal 在 iOS 上實(shí)現(xiàn)深度學(xué)習(xí)的工具,它主要封裝了 MPSImage 來存儲(chǔ)數(shù)據(jù)管理內(nèi)存,實(shí)現(xiàn)了 Convolution、Pooling、Fullconnetcion、ReLU 等常用的卷積神經(jīng)網(wǎng)絡(luò)中的 Layer
可以在 iPhone 內(nèi)置應(yīng)用中利用 Core ML 的優(yōu)勢(shì),提升或?qū)崿F(xiàn)如 Siri 語音識(shí)別、相機(jī)應(yīng)用中識(shí)別人臉、QuickType 打字聯(lián)想等新特性。Core ML+Vision 應(yīng)用場(chǎng)景如下所示:
- 在相機(jī)或給定圖像中檢測(cè)人臉
- 檢測(cè)眼睛和嘴巴的位置、頭部形狀等人臉面部詳細(xì)特征
- 錄制視頻過程中追蹤移動(dòng)的對(duì)象和確定地平線的角度
- 轉(zhuǎn)換兩個(gè)圖像,使其內(nèi)容對(duì)齊,識(shí)別圖像中的文本
- 檢測(cè)和識(shí)別條形碼
- ......
另外,還可以使用 Vision 驅(qū)動(dòng) Core ML,即在使用 Core ML 進(jìn)行機(jī)器學(xué)習(xí)時(shí),用 Vision 框架進(jìn)行一些數(shù)據(jù)預(yù)處理。
Core ML 文檔地址:https://developer.apple.com/documentation/coreml
Bender:基于 Metal 的機(jī)器學(xué)習(xí)框架

2017 年 3 月份左右,XMART LABS 在 GitHub 上開源了 Bender,它是一個(gè)基于 Metal 的機(jī)器學(xué)習(xí)框架,它允許你在 IOS APP 上輕松地定義和運(yùn)行神經(jīng)網(wǎng)絡(luò),該框架在底層使用了蘋果的 Metal Performance Shaders。
XMART LABS 在 Github 上對(duì) Bender 進(jìn)行了這樣的描述:
- Bender 是 MetalPerformanceShaders 之上的一個(gè)可用來操作神經(jīng)網(wǎng)絡(luò)的抽象層(abstraction layer)的工具。Bender 允許你使用卷積、池化、全連接以及一些規(guī)范化等最常見的 layer 來輕松地定義和運(yùn)行神經(jīng)網(wǎng)絡(luò)。XMART LABS 還想加載在其他框架(TensorFlow 或者 Caffe2 等框架)上訓(xùn)練好的模型,現(xiàn)在的 Bender 已經(jīng)內(nèi)置了一個(gè) TensorFlow 適配器(其可加載帶有變量的圖,并將其「翻譯」成 Bender 的 layer),并計(jì)劃將其功能大大增強(qiáng)。
優(yōu)勢(shì)
- Bender 支持選擇 Tensorflow、 Keras、Caffe 等框架來運(yùn)行已訓(xùn)練的模型,無論是在將訓(xùn)練好的模型 freeze,還是將權(quán)重導(dǎo)至 files(官方表示該支持特性即將到來)
- 可直接從支持的平臺(tái)導(dǎo)入一個(gè) frozen graph 或者重新定義神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)并加載權(quán)重。這兩項(xiàng)操作均只需花費(fèi)幾分鐘
- Bender 支持最常用的機(jī)器學(xué)習(xí)節(jié)點(diǎn)和 layer,同時(shí)其也具有可擴(kuò)展性,因而你可以編寫自己的可定義函數(shù)
使用 Bender 開發(fā) APP 的示例如下:
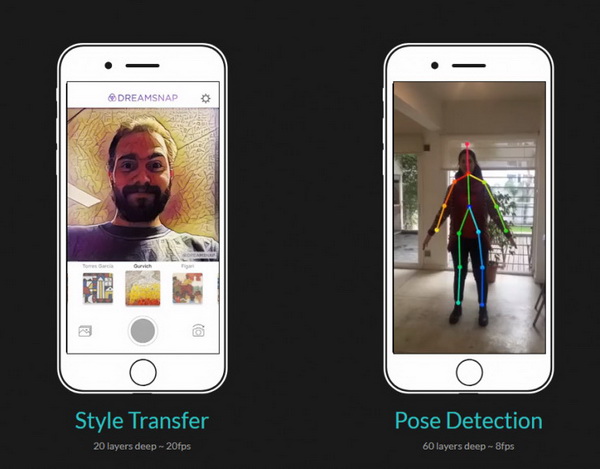
Bender 有何優(yōu)勢(shì)?
- Bender 能解決 MetalPerformanceShaders(iOS 中可使用的框架)中對(duì)開發(fā)者不太友好導(dǎo)致需要大量重復(fù)代碼的問題
- TensorFlow 雖然可為 iOS 進(jìn)行編譯,但它并不支持在 GPU 上運(yùn)行,而 Bender 的適配器則可以將 TF graph 解析并翻譯成 Bender layer
Bender 頁面網(wǎng)址:https://xmartlabs.github.io/Bender/
Github 地址:https://github.com/xmartlabs/Bender
百度開源移動(dòng)端深度學(xué)習(xí)框架 MDL,可在蘋果安卓系統(tǒng)自由切換
2017 年 9 月,百度在 GitHub 上開源了移動(dòng)端深度學(xué)習(xí)框架 mobile-deep-learning(MDL)的全部代碼以及腳本,這項(xiàng)研究旨在讓卷積神經(jīng)網(wǎng)絡(luò)(CNNC)能更簡(jiǎn)單和高速的部署在移動(dòng)端,支持 iOS GPU,目前已經(jīng)在百度 APP 上有所使用。
MDL 具有體積小和速度快的特點(diǎn)。
- 大小:340k+(在 arm v7 上)
- 速度:對(duì)于 iOS Metal GPU Mobilenet,速度是 40ms,對(duì)于 Squeezenet,速度是 30ms
特征
- 一鍵部署,可以通過修改參數(shù)在 iOS 和 Android 端之間轉(zhuǎn)換
- iOS GPU 上支持運(yùn)行 MobileNet 和 Squeezenet 模型
- 在 MobileNet、GoogLeNet v1 和 Squeezenet 模型下都很穩(wěn)定
- 占用空間極小(4M),不需要依賴第三方的庫
- 支持從 32 比特 float 到 8 比特 unit 轉(zhuǎn)化
- 接下來會(huì)與與 ARM 相關(guān)的算法團(tuán)隊(duì)進(jìn)行線上線下溝通,優(yōu)化 ARM 平臺(tái)
- NEON 使用涵蓋了所有的卷積、歸一化、池化等
- 利用循環(huán)展開,可以讓性能更加優(yōu)化,防止不必要的 CPU 損失
- 對(duì)于 overhead 進(jìn)程,可以轉(zhuǎn)發(fā)大量繁重的計(jì)算任務(wù)
GitHub 地址:https://github.com/baidu/mobile-deep-learning
MXNet: AWS 官方深度學(xué)習(xí)框架,支持移動(dòng)端開發(fā)
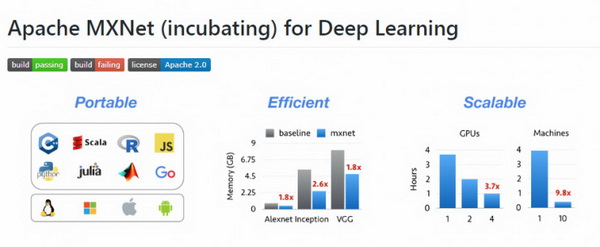
MXNet 是一款開源的、輕量級(jí)、可移植的、靈活的深度學(xué)習(xí)庫,它讓用戶可以混合使用符號(hào)編程模式和指令式編程模式來最大化效率和靈活性,目前已經(jīng)是 AWS 官方推薦的深度學(xué)習(xí)框架。
MXNet 的核心是一個(gè)動(dòng)態(tài)的依賴調(diào)度器,支持自動(dòng)將計(jì)算任務(wù)并行化到多個(gè) GPU 或分布式集群(支持 AWS、Azure、Yarn 等)。它上層的計(jì)算圖優(yōu)化算法可以讓符號(hào)計(jì)算執(zhí)行得非常快,而且節(jié)約內(nèi)存,開啟 mirror 模式會(huì)更加省內(nèi)存,甚至可以在某些小內(nèi)存 GPU 上訓(xùn)練其他框架因顯存不夠而訓(xùn)練不了的深度學(xué)習(xí)模型。
MXNet 支持在移動(dòng)設(shè)備(Android、iOS)上運(yùn)行基于深度學(xué)習(xí)的圖像識(shí)別等任務(wù),它的性能如下:
- 依賴少,內(nèi)存要求少,對(duì)于 Android 性能變化大的手機(jī),通用性更高
- MXNet 需要先使用 ndk 交叉編譯項(xiàng)目中的 amalgamation,可以根據(jù)自己的需求,修改 jni 中的接口,然后,編譯好的動(dòng)態(tài)鏈接庫替換掉 Android demo 中的
- MXNet 提供了對(duì) Caffe 模型的支持,通過提供的工具將 Caffe 訓(xùn)練好的模型進(jìn)行轉(zhuǎn)化 json 格式,隨后在移動(dòng)端使用
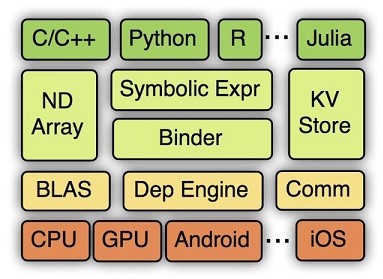
此外,MXNet 的一個(gè)很大的優(yōu)點(diǎn)是支持多語言封裝,比如 C++、Python、R、Julia、Scala、Go、MATLAB 和 JavaScript。在 MXNet 中構(gòu)建一個(gè)網(wǎng)絡(luò)需要的時(shí)間可能比 Keras、Torch 這類高度封裝的框架要長(zhǎng),但是比直接用 Theano 等要快。MXNet 的各級(jí)系統(tǒng)架構(gòu)(下面為硬件及操作系統(tǒng)底層,逐層向上為越來越抽象的接口)如下圖所示。
GitHub:http://github.com/dmlc/MXNet
Apache MXNet 官方網(wǎng)站:https://MXNet.incubator.apache.org/