













聊一聊用戶畫像如何存儲
0x00 前言
隨便聊一下用戶畫像的存儲。
現(xiàn)在的用戶畫像,動不動就是幾千幾萬個標簽,標簽一多就出現(xiàn)了一些需要克服的難題,比如下面兩個:
- 如何解決頻繁新增和刪除標簽的場景
- 如何解決不同標簽更新時間和頻率不同的問題
0x01 數(shù)據(jù)模型設計
從個人角度來講,在大數(shù)據(jù)領域接觸比較多的的存儲引擎有這幾個:Hive(Hdfs)、Hbase、ES。這也會是我們在選擇存儲系統(tǒng)中幾個主要的備選方案。
優(yōu)缺點就不再分析了。我們切入正題:數(shù)據(jù)模型該怎么設計?
一、橫表
以Hive為例,我們最常用的就是橫表,也就是一個 key,跟上它的所有標簽。比如下面是一個簡單的橫表。
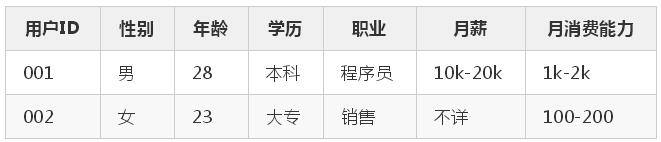
那么用橫表有什么問題嗎?有的,其實也就是前言里面提到的:
- 由于用戶的標簽會非常多,而且隨著用戶畫像的深入,會有很多細分領域的標簽,這就意味著標簽的數(shù)量會隨時增加,而且可能會很頻繁。
- 不同的標簽計算頻率不同,比如說學歷一周計算一次都是可以接收的,但是APP登錄活躍情況卻可能需要每天都要計算。
- 計算完成時間不同,如果是以橫表的形式存儲,那么最終需要把各個小表的計算結果合并,此時如果出現(xiàn)了一部分結果早上3點計算完成,一部分要早上10點才能計算完成,那么橫表最終的生成時間就要很晚。
- 大量空缺的標簽會導致存儲稀疏,有一些標簽會有很多的缺失,這在用戶畫像中很常見。
嗯,上述的問題,主要是當標簽數(shù)量開始快速增多的時候會遇到的問題。標簽量少的時候其實是不用擔心這些的。
那么這些問題該怎么解決呢?這就是下面要聊得豎表。
二、豎表
豎表長下面這個樣子:
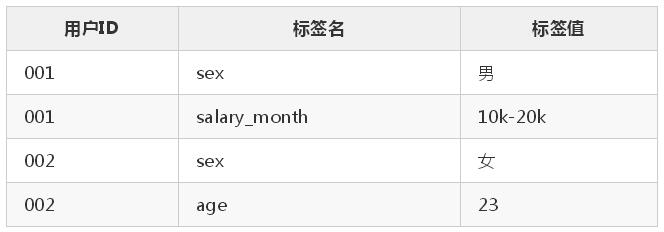
這里就不再列舉全部內(nèi)容了,大概介紹一下,豎表其實就是將標簽都拆開,一個用戶有多少標簽,那么在這里面就會有幾條數(shù)據(jù)。
豎表能比較好地解決上面寬表的問題。但是它也會帶來了新的問題,比如說多標簽組合的查詢需求:“我們想看年齡在23-30之間,月薪在10-20k之間,喜歡聽古典音樂的女性”,這種多標簽查詢條件組合情況在豎表中就不太容易支持。
三、橫表+豎表
如前面所分析,豎表和橫表各有所長和所短,那么能不能兩者結合呢?
這其實也要考慮橫表和豎表的特性,整體來講就是豎表對計算層支持的好,橫表對查詢層支持的好。那么設計的化就可以這樣:
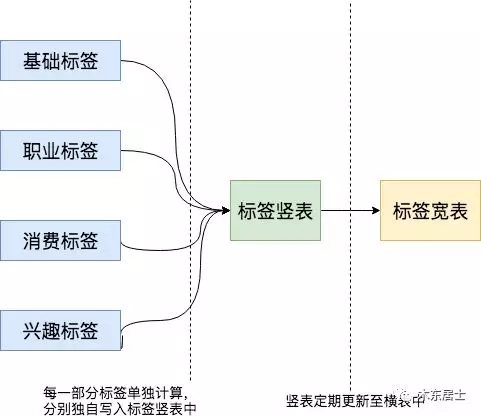
0x02 如何存儲?
關于存儲,我們以前文說的第三種方案為例。
標簽的計算我們可以使用Hive、Spark這些計算引擎,這個沒什么問題,然后就是這些標簽的單獨存儲可以以Hive為主來存儲。
那么在導入標簽豎表的時候可以考慮兩種存儲引擎:Hive(Hdfs)和Hbase,其實筆者更傾向于Hbase,因為如果存在Hbase里的話會更方便查詢。順便再打上一個時間標簽,用起來就更方便了。
***,標簽寬表的話可以考慮ES。另外需要注意的就是,從豎表往寬表到數(shù)據(jù)的時候需要做一層數(shù)據(jù)的加工,而且考慮到數(shù)據(jù)稀疏的情況的話,需要在寬表存儲這里做一些優(yōu)化。
















