PostgreSQL查詢優(yōu)化器詳解(物理優(yōu)化篇)
繼《PostgreSQL查詢優(yōu)化器詳解(邏輯優(yōu)化篇)》,本文將另以物理優(yōu)化角度,繼續(xù)深入PostgreSQL數(shù)據(jù)庫查詢優(yōu)化器的細枝末節(jié)。為了讓大家通過通俗易懂的方式更好地理解消化其中的晦澀概念,作者別出心裁地撰寫成趣味故事,雖然篇幅稍長,但細細品讀定將收獲匪淺。
關(guān)于統(tǒng)計信息與選擇率
“咚咚咚……”門外傳來了敲門聲,大明打開門一看,原來是同事牛二哥。牛二哥是專門從事數(shù)據(jù)庫查詢優(yōu)化開發(fā)的碼農(nóng),也有十幾年從業(yè)經(jīng)驗了,大明感到非常happy,因為這兩天給小明講查詢優(yōu)化器講得有些吃力,今天牛二哥來了正好可以幫上忙:“牛二同志,我弟弟小明最近學校要做數(shù)據(jù)庫原理實踐,總來問我優(yōu)化器的問題,可我對優(yōu)化器也是一知半解,這下你來了可以幫幫忙不?”
牛二哥痛快地說:“這難不倒我,隨時都可以講。”
小明對牛二哥早有耳聞,接到大明電話后速速趕到,見面不久便吐起了苦水:“我最近正在查看基于代價的優(yōu)化,感覺付出了很多代價,但收獲甚微,期望今天能得到牛二哥的指導(dǎo)。”
牛二哥說:“說到代價,我覺得有個東西是繞不過去的,就是統(tǒng)計信息和選擇率,PostgreSQL的物理優(yōu)化需要計算各種物理路徑的代價,而代價估算的過程嚴重依賴于數(shù)據(jù)庫的統(tǒng)計信息,統(tǒng)計信息是否能準確地描述表中的數(shù)據(jù)分布情況是決定代價準確性的重要條件之一。”
小明說:“大明和我說過,數(shù)據(jù)庫有很多物理路徑,這些物理路徑也叫物理算子。和邏輯算子不同,物理算子是查詢執(zhí)行器的執(zhí)行方法,我們只需要計算物理算子每個步驟的代價,匯總起來就是路徑的代價了,那要統(tǒng)計信息有什么用呢?”
牛二哥說:“是的,我們就是要計算一個物理算子的代價,但是物理算子的計算量并不是一成不變的。”說著他從旁邊的書桌上拿來紙和筆,寫了兩個SQL語句。
- SELECT A+B FROM TEST_A WHERE A > 1;
- SELECT A+B FROM TEST_A WHERE A > 100000000;
然后說:“你看,這兩個語句可以用同樣的物理算子來完成,但是他們的計算量一樣的嗎?”
小明心想:A > 1和A > 1000000000都是過濾條件,經(jīng)過過濾之后,他們產(chǎn)生的數(shù)據(jù)量就不同了,這樣投影中的A+B的計算次數(shù)就不同了,所以它們的代價應(yīng)該是不同的,那它和統(tǒng)計信息有什么關(guān)系呢?小明靈光一閃,馬上說:“我知道了,我在計算物理算子的代價的時候,要知道A > 1之后還剩下多少數(shù)據(jù)或者A > 1000000000之后還剩下多少數(shù)據(jù),如果我們提前對表上的數(shù)據(jù)內(nèi)容做了統(tǒng)計,剩下多少數(shù)據(jù)就不難計算了,所以必須要有統(tǒng)計信息。”
牛二哥點了點頭說:“嗯,通過統(tǒng)計信息,代價估算系統(tǒng)就可以了解一個表有多少行數(shù)據(jù)、用了多少個數(shù)據(jù)頁面、某個值出現(xiàn)的頻率等等,然后就能根據(jù)這些信息計算出一個約束條件能過濾掉多少數(shù)據(jù),這種約束條件過濾出的數(shù)據(jù)占總數(shù)據(jù)量的比例稱之為‘選擇率’,所謂選擇率就是一個比例,它的公式是這樣的。”說著牛二哥繼續(xù)在紙上寫下了選擇率的公式:
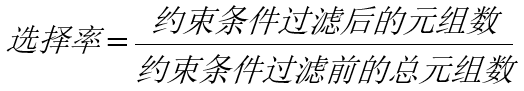
“不過上面的示例有點簡單了,實際應(yīng)用中通常約束條件會比較多,而且比較復(fù)雜,通常我們會計算每個子約束條件的選擇率,然后就可以根據(jù)AND運算符和OR運算符計算它們的綜合的選擇率,AND運算符和OR運算符的選擇率計算是基于概率的,你看這里的概率公式。”說著,牛二哥又繼續(xù)在紙上寫了起來。
- P(A+B)=P(A)+P(B)-P(AB)
- P(AB)=P(A)×P(B)
“有了這些,我們就可以求解多種類型的約束條件的選擇率了,比如……”牛二哥繼續(xù)寫出:
- P(ssex IS NOT NULL OR sno > 5)
- = P(ssex IS NOT NULL) + P(sno > 5) – P(ssex IS NOT NULL AND sno > 5)
- = P(ssex IS NOT NULL) + P(sno > 5) – P(ssex IS NOT NULL) × P(no > 5)
小明覺得牛二哥講解的進展有點快,趕緊問:“那么統(tǒng)計信息是什么形式的呢?”
牛二哥撓撓頭說:“這個還真是有點麻煩,我們說常用的統(tǒng)計信息的形式就是distinct率、NULL值率、高頻值、直方圖、相關(guān)系數(shù)這些,它們分別有不同的作用。比如說distinct率,你可以獲知某一列有多少個獨立值,這種信息對于像性別這種列就顯得特別有用。NULL值率呢,在統(tǒng)計的過程中,NULL值是不好處理的,因此把它獨立出來,形成NULL值率,這樣在高頻值、直方圖這些里面就不用考慮NULL值的情況了。高頻值屬于奇異值,顧名思義,就是出現(xiàn)得比較多的一些列值。去掉了NULL值,再去掉高頻值,剩下的值可以用來做一個等頻的直方圖。”
大明看小明有點跟不上,過來說:“統(tǒng)計信息嘛,主要的還是高頻值、直方圖和相關(guān)系數(shù),實際上我建議還是不要糾結(jié)于統(tǒng)計信息有哪些形式,只要知道它是用來算代價的就可以了。”
牛二哥對大明說:“這怎么可以,我還沒有說統(tǒng)計信息是如何生成的呢,比如它通過了兩階段采樣,然后對樣本進行統(tǒng)計時使用的統(tǒng)計方法,哪些值可以作為高頻值,直方圖有幾個桶,相關(guān)系數(shù)是怎么計算的,相關(guān)系數(shù)在計算索引掃描路徑代價的時候怎么用的……而且我和你說,PostgreSQL還出了基于多列的擴展統(tǒng)計信息,多列統(tǒng)計信息分成了哪些類型,分別是什么含義,各自是怎么計算的,還有選擇率是怎么結(jié)合統(tǒng)計信息計算的,這些我還沒說呢……”
大明忍不住說:“像你這樣講優(yōu)化器,豈不是要出一本書了?”
牛二哥做痛苦狀:“那好吧,統(tǒng)計信息我們就說到這里,但是它確實是代價計算的基石,小明同學,你理解了它的作用就可以了。”
大明繼續(xù)神秘地說:“實際上統(tǒng)計信息往往也不準,你想想本來就是采樣的結(jié)果嘛,樣本是否顯著壓根就不好說,而且隨著應(yīng)用程序?qū)Ρ淼母拢y(tǒng)計信息可能更新不及時,那就更會出現(xiàn)偏差。更嚴重的是,如果我們遇到a > b這樣的約束條件,使用統(tǒng)計信息計算選擇率也很不好計算,即使算出來,也不準嘛。”
牛二哥說:“是的,統(tǒng)計信息確實也有不準確的問題。我聽說有個DBA,他家后院出了一口泉水,他爸爸覺得是吉兆,去找風水大師看。風水大師掐指一算說:你兒子是個DBA,每次數(shù)據(jù)庫性能慢就知道更新統(tǒng)計信息,可是統(tǒng)計信息太水了,都從你家后院冒出來了。”
三個人頓時笑做一團。
關(guān)于物理路徑
玩笑過后,小明說:“不如給我說說物理路徑吧,我們代價算來算去,最終還是為了物理路徑計算代價嘛。大明和我說過它大體分成掃描路徑和連接路徑,我查過一些說明,知道掃描路徑有順序掃描路徑、索引掃描路徑、位圖掃描路徑等等;而連接路徑通常有嵌套循環(huán)連接路徑、哈希連接路徑、歸并連接路徑,另外還有一些其他的路徑,比如排序路徑、物化路徑等等。”
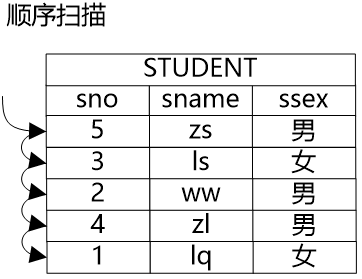
牛二哥說:“是的,我們就來說說這些路徑的含義吧。如果要獲得一個表中的數(shù)據(jù),最基礎(chǔ)的方法就是將表中的所有的數(shù)據(jù)都遍歷一遍,從中挑選出符合條件的數(shù)據(jù),這種方式就是順序掃描路徑。順序掃描路徑的優(yōu)點是具有廣泛的適用性,各種表都可以用這種方法,缺點自然是代價通常比較高,因為要把所有的數(shù)據(jù)都遍歷一遍。”大明同時在紙上畫了個圖,說:“這個圖大概就是順序掃描路徑。”
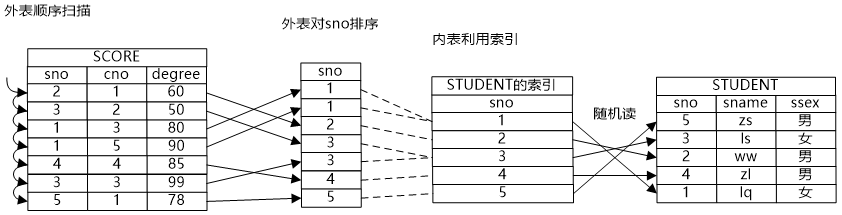
牛二哥則繼續(xù)說:“如果將數(shù)據(jù)做一些預(yù)處理,比如建立一個索引,如果要想獲得一個表的數(shù)據(jù),可以通過掃描索引獲得所需數(shù)據(jù)的‘地址’,然后通過地址將需要的數(shù)據(jù)獲取出來。尤其是在選擇操作帶有約束條件的情況下,在索引和約束條件共同的作用下,表中有些數(shù)據(jù)就不用再遍歷了,因為通過索引就很容易知道這些數(shù)據(jù)是不符合約束條件的,更有甚者,因為索引上也保存了數(shù)據(jù),它的數(shù)據(jù)和關(guān)系中的數(shù)據(jù)是一致的,因此如果索引上的數(shù)據(jù)就能滿足要求,只需要掃描索引就可以獲得所需數(shù)據(jù)了,也就是說在掃描路徑中還可以有索引掃描路徑和快速索引掃描路徑兩種方式。”
大明則繼續(xù)為牛二哥“捧哏”,在紙上畫出了索引掃描和快速索引掃描的圖。
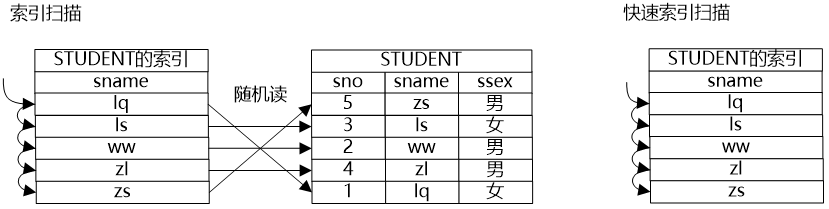
小明看到圖上寫了“隨機讀”三個字,問道:“我看這個索引掃描有隨機讀的問題,這個問題能否解決掉呢?也就是說即利用了索引,還避免了隨機讀的問題,有這樣的辦法嗎?”
牛二哥說:“索引掃描路徑確實帶來隨機讀的問題,因為索引中記錄的是數(shù)據(jù)元組的地址,索引掃描是通過掃描索引獲得元組地址,然后通過元組地址訪問數(shù)據(jù),索引中保存的“有序”的地址,到數(shù)據(jù)中就可能是隨機的了。位圖掃描就能解決這個問題,它通過位圖將地址保存起來,把地址收集起來之后,然后讓地址變得有序,這樣就通過中間的位圖把隨機讀消解掉了。”大明則繼續(xù)在紙上畫出了位圖掃描的示意圖。
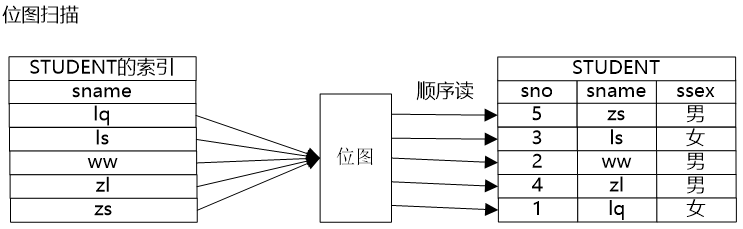
大明補充說道:“掃描過程中還會結(jié)合一些特殊的情況有一些非常高效的掃描路徑,比如TID掃描路徑,TID實際上是元組在磁盤上的存儲地址,我們能夠根據(jù)TID直接就獲得元組,這樣查詢效率就非常高了。”
牛二哥點了點頭繼續(xù)說:“掃描路徑通常是執(zhí)行計劃中的葉子結(jié)點,也就是在最底層對表進行掃描的結(jié)點,掃描路徑就是為連接路徑做準備的,掃描出來的數(shù)據(jù)就可以給連接路徑來實現(xiàn)連接操作了。”
大明一邊在紙上畫一邊說:“要對兩個關(guān)系做連接,受笛卡爾積的啟發(fā),可以用一個算法復(fù)雜度是O(mn)的方法來實現(xiàn),我們叫它Nestlooped Join方法。這種方法雖然復(fù)雜度比較高,但是和順序掃描一樣,勝在具有普適性。”
牛二哥說:“嵌套循環(huán)連接這種方法的復(fù)雜度比較高,看上去沒什么意義,但是如果Nestlooped Join的內(nèi)表的路徑是一個索引掃描路徑,那么算法的復(fù)雜度就會降下來。索引掃描的算法復(fù)雜度是O(logn),因此如果Nestlooped Join的內(nèi)表是一個索引掃描,它的整體的算法復(fù)雜度就變成了O(mlogn),看上去這樣也是可以接受的。”
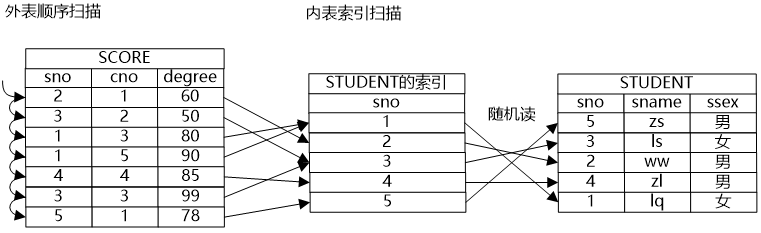
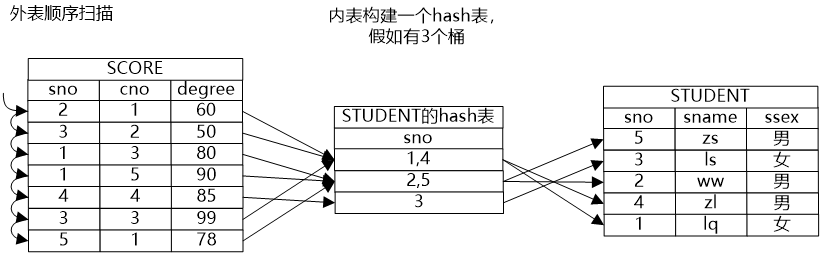
小明點了點頭說:“嗯,索引實際上是對數(shù)據(jù)做了一些預(yù)處理,我想如果哈希連接方法就是將內(nèi)表做一個哈希表,這樣也等于將內(nèi)表的數(shù)據(jù)做了預(yù)處理,也能方便外表的元組在里面探測吧?”
牛二哥點了點頭說:“假設(shè)Hash表有N個桶,內(nèi)表數(shù)據(jù)均勻的分布在各個桶中,那么Hash Join的時間復(fù)雜度就是O(m * n /N),當然,這里我們沒有考慮上建立Hash表的代價。”
大明則在紙上畫出了Hash連接的示意圖,并補充道:“Hash連接通常只能用來做等值判斷。”
牛二哥繼續(xù)說:“如果將兩個表先排序,那么就可以引入第三種連接方式,Merge Join。這種連接方式的代價主要浪費在排序上,如果兩個關(guān)系的數(shù)據(jù)量都比較小,那么排序的代價是可控的,MergeJoin就是適用的。另外如果關(guān)系上有有序的索引,那就可以不用單獨排序了,這樣也比較適用于MergeJoin。你看我畫的這個歸并連接的示意圖,外表是需要排序的,而內(nèi)表則借用了原有的索引的順序,消除了排序的時間,降低了物理路徑的代價。”
“這些路徑屬于SPJ路徑,在PostgreSQL的優(yōu)化器中,通常會先生成SPJ的路徑,然后在這基礎(chǔ)上再疊加Non-SPJ的路徑,比如說聚集操作、排序操作、limit操作、分組操作……”牛二哥繼續(xù)補充道。
關(guān)于代價的計算
小明說:“可是算來算去,物理路徑的代價還是有選不準的時候啊。”
牛二哥說:“最優(yōu)路徑選得不準是誰的原因?那就是代價模型不行啊。代價模型不行賴誰?那就是程序員沒建好啊,所以要怪就怪到程序員自己頭上。”
小明問道:“可是我看PostgreSQL的代價計算已經(jīng)很復(fù)雜了啊。”
“但數(shù)據(jù)庫的周邊環(huán)境更復(fù)雜啊。你想想,在實際應(yīng)用中,數(shù)據(jù)庫用戶的配置硬件環(huán)境千差萬別,CPU的頻率、主存的大小和磁盤介質(zhì)的性質(zhì)都會影響執(zhí)行計劃在實際執(zhí)行時的效率。”牛二哥說。
大明接過來繼續(xù)說道;“雖然在代價估算的過程中,我們無法獲得‘絕對真實’的代價,但是‘絕對真實’的代價也是不必要的。因為我們只是想從多個路徑(Path)中找到一個代價最小的路徑,只要這些路徑的代價是可以‘相互比較’的就可以了。因此可以設(shè)定一個‘相對’的代價的單位1,同一個查詢中所有的物理路徑都基于這個“相對”的單位1來計算的代價,這樣計算出來的代價就是可以比較的,也就能用來對路徑進行挑選了。”
牛二哥接著說:“PostgreSQL采用順序讀寫一個頁面的IO代價作為單位1,而把隨機IO定為了順序IO的4倍。”
小明說:“我知道,這個我查過相關(guān)的書。首先,目前的存儲介質(zhì)很大部分仍然是機械硬盤,機械硬盤的磁頭在獲得數(shù)據(jù)庫的時候需要付出尋道時間。如果要讀寫的是一串在磁盤上連續(xù)的數(shù)據(jù),就可以節(jié)省尋道時間,提高IO性能。而如果隨機讀寫磁盤上任意扇區(qū)的數(shù)據(jù),那么會有大量的時間浪費在尋道上。其次,大部分磁盤本身帶有緩存,這就形成了主存→磁盤緩存→磁盤的三級結(jié)構(gòu)。在將磁盤的內(nèi)容加載到內(nèi)存的時候,考慮到磁盤的IO性能,磁盤會進行數(shù)據(jù)的預(yù)讀,把預(yù)讀到的數(shù)據(jù)保存在磁盤的緩存中。也就是說如果用戶只打算從磁盤讀取100個字節(jié)的數(shù)據(jù),那么磁盤可能會連續(xù)地讀取磁盤中的512字節(jié)(不同的磁盤預(yù)讀的數(shù)量可能不同)并將其保存到磁盤緩存。如果下一次是順序讀取100個字節(jié)之后的內(nèi)容,那么預(yù)讀的512字節(jié)的數(shù)據(jù)就會發(fā)揮作用,性能會大大的增加。而如果讀取的內(nèi)容超出了512字節(jié)的范圍,那么預(yù)讀的數(shù)據(jù)就沒有發(fā)揮作用,磁盤的IO性能就會下降。”說完小明得意地說:“怎么樣,我說得對吧?”
牛二哥說:“你說得對,目前PostgreSQL的查詢優(yōu)化大量的考慮了隨機IO和順序IO所帶來的性能差別,在這方面做了不少優(yōu)化。但是現(xiàn)在的磁盤技術(shù)越來越發(fā)達了,以后隨機IO和順序IO是不是還差這么多,就值得商榷了。”
“那到底還有哪些代價基準單位呢?”小明繼續(xù)問道。
大明回答:“基于磁盤IO的代價單位當然就是和Page有關(guān)的了,也就是說我們剛才說的順序IO和隨機IO都屬于IO方面的基準代價。讓牛二哥給你介紹一下CPU方面的代價基準單位吧。”
牛二哥說:“CPU方面的基準單位有哪些呢?比如說我們通過IO把磁盤頁面讀到了緩存,但我們要處理的是元組啊,所以還需要把元組從頁面里解出來,還要處理元組,這部分主要消耗的是CPU,所以會有一個元組處理的代價基準單位。另外,我們在投影、約束條件里有大量的表達式,這些表達式求解也主要消耗CPU資源,所以還有一個表達式代價的基準單位。”
牛二哥繼續(xù)說道:“現(xiàn)在PostgreSQL增加了很多并行路徑,因此它也產(chǎn)生了通信代價,這個也需要計算的。”
小明聽后說:“那我們就能得到一個這樣的公式。”說著在紙上寫了一個公式:
總代價 = CPU代價 + IO代價 + 通信代價
然后繼續(xù)說:“可是我通過EXPLAIN還查看過PostgreSQL的執(zhí)行計劃,從執(zhí)行計劃中還看到有啟動代價和總代價,這是怎么回事呢?”
牛二哥想了想,在紙上寫了一個公式:
總代價 = 啟動代價 + 執(zhí)行代價
然后說:“這是從另一個角度來計算代價,啟動代價是指從語句開始執(zhí)行到查詢引擎返回第一條元組的代價(另一種說法是準備好去獲得第一條元組的代價),總代價是SQL語句從開始執(zhí)行到結(jié)束的所有代價。”
“可是……為什么要區(qū)分啟動代價和執(zhí)行代價呢?”
“這個嘛……”牛二哥思考了一下,覺得一兩句話不容易說清楚,于是寫了個例子:
- SELECT * FROM TEST_A WHERE a > 1 ORDER BY a LIMIT 1;
“我們假設(shè)這個在TEST_A(a)上有一個B樹索引,曉得不,那這個語句可能會形成什么樣的執(zhí)行計劃呢?”
小明想了想,覺得空想可能有點困難,于是在紙上畫了一下,最終畫出了兩個執(zhí)行路徑:
執(zhí)行路徑1:LIMIT 1
-> SORT(a)
-> SeqScan WHERE A > 1;
執(zhí)行路徑2:LIMIT 1
-> IndexScan WHERE A > 1;
(小明注:B樹索引有序,不用再排序了)
小明說:“我覺得這兩個都可以,不過第二個更好,因為節(jié)省了排序的時間。”
牛二哥問:“你知道的,PostgreSQL采用動態(tài)規(guī)劃的方法來實現(xiàn)路徑的搜索,它是一種自底向上的方法,也就是說會先建立篩選掃描路徑,然后用篩選后的掃描路徑再去形成連接路徑。那么在我們篩選掃描路徑的時候,是不知道它的上層有沒有LIMIT的,這時候如果單獨看SeqScan + SORT和IndexScan你覺得哪個好呢?”
“嗯,我知道陷阱在哪里,大明和我說過,A > 1的選擇率高的話會選擇順序掃描,而A > 1的選擇率低的情況下,會選擇索引掃描。這是因為索引掃描會產(chǎn)生隨機IO,也就是說在選擇率高的情況下,有可能SeqScan + SORT會優(yōu)于IndexScan。雖然SeqScan + SORT會有排序,但是IndexScan的隨機IO實在是太可觀了。”
牛二哥點了點頭說:“對的,假設(shè)選擇率比較高,這時選擇了SeqScan + SORT,是因為它不知道再上層是LIMIT 1。如果上面是LIMIT 1,就會導(dǎo)致索引掃描不用全部掃完,只要掃一丟丟就可以了。這時隨機IO就很小了,但是SeqScan + SORT就還必須全部執(zhí)行完才能獲取到LIMIT 1,也就是說SeqScan + SORT、或者說SORT要獲取第一條元組的啟動代價是比較高的。如果上面有LIMIT 1這樣的子句,那么啟動代價高的路徑可能就沒有優(yōu)勢了,這就是啟動代價的作用。”
小明恍然大悟地說:“SORT要全部做完才能獲取第一條元組,它的啟動代價大,但是總代價小。而索引掃描呢,因為本身有序,它的啟動代價是小的,但是由于有隨機IO,所以它的總代價是大的。如果我們只按照總代價進行篩選,就沒辦法獲得最優(yōu)的代價了。”
“什么什么?啟動代價……你們進展很快嘛。”這時大明跑過來說:“讓我們想一下晚上吃點什么吧?”
小明:“吃點好的,很有必要。我這腦細胞已經(jīng)快用沒了。”
關(guān)于最優(yōu)路徑
小明、大明和牛二哥在外賣APP里搜索附近的飯店,大明突然感嘆道:“看,這就是藍海,我們可以創(chuàng)業(yè)搞一個AI點評,只能推薦最優(yōu)的飯店啊,我準確地找到了吃貨們的痛點,這里面隱含著很大的商機啊!”
牛二哥瞥了他一眼說:“AI推薦當然好,可是要推薦得準才行啊。一個人一個口味,你這個需求太‘智能’了,我估計不好弄。”
小明突然說:“我最近在算法課上學過一些最優(yōu)解問題的解決方法,應(yīng)該能用得上。”
牛二哥嘆口氣說:“可是這些方法用到優(yōu)化器里都不一定夠用,何況用到一個更加智能的項目上呢?”
“嗯?優(yōu)化器里也用到最優(yōu)解問題的方法了嗎?我們學過動態(tài)規(guī)劃、貪心算法……”小明如數(shù)家珍地說起來。
大明說:“用到了啊, 雖然物理路徑看上去也不多,但實際上枚舉起來,它的搜索空間也不小。例如在掃描路徑中,我們就可以有順序掃描、索引掃描和位圖掃描。假如一個表上有多個索引,就可能產(chǎn)生多個不同的索引掃描,那么哪個索引掃描路徑好呢?還有索引掃描和順序掃描、位圖掃描相比,哪個好呢?”
大明看著小明迷離的眼神后繼續(xù)說:“數(shù)據(jù)庫路徑的搜索方法通常有3種類型:自底向上方法、自頂向下方法、隨機方法,而PostgreSQL采用了其中的兩種方法。”
“采用了哪兩種方法?”牛二哥明知故問。
“采用了自底向上和隨機方法,其中自底向上的方法是采用動態(tài)規(guī)劃方法,而隨機方法采用的是遺傳算法。”
“那有誰使用了自頂向下的方法呢?”牛二哥繼續(xù)“捧哏”道。
“嗯……這個嘛,Pivotal公司的開源優(yōu)化器ORCA用的就是自頂向下的方法。可以讓牛二哥先給你說說怎樣用動態(tài)規(guī)劃方法搜索最優(yōu)物理路徑。”
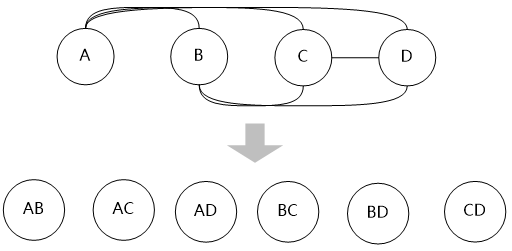
牛二哥拿出紙來畫了幾個圈,然后說:“這代表四個表,自底向上嘛,所以是從底下向上堆積,這是最底層,我們叫它第一層”。

“動態(tài)規(guī)劃方法首先考慮兩個表的連接,其中優(yōu)先考慮有連接關(guān)系的表進行連接,兩個表的連接可以建立一個新的表,我們把這些新表叫做第二層。”牛二哥通過連線,產(chǎn)生了一些新的“表”。
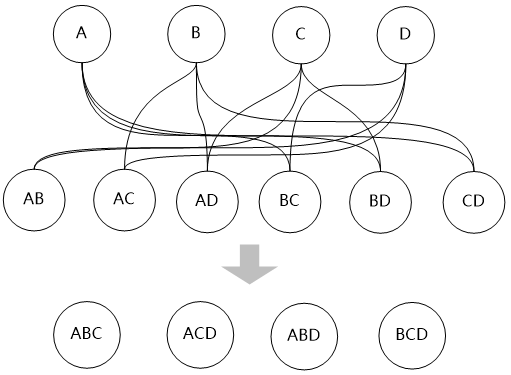
“第二層的表和第一層的表再連接,可以生成基于三個表連接的新的‘表’,這樣就又向前推進了一層,我們產(chǎn)生了第三層”
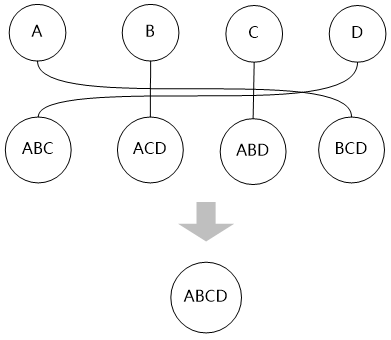
“然后再用第三層的表和第一層的表進行連接,最終生成整個問題的最優(yōu)路徑。”
“可是,這不就是窮舉嗎?”小明問道。
牛二哥解釋說:“動態(tài)規(guī)劃有兩個特點,一個是要重復(fù)地利用子問題的解,這樣能減少計算量,降低復(fù)雜度;另外一點就是通過子問題的最優(yōu)解能夠構(gòu)造出最終的最優(yōu)解,也就是說需要具有最優(yōu)子結(jié)構(gòu)的性質(zhì),所以動態(tài)規(guī)劃的復(fù)雜度和窮舉是不一樣的。”
大明繼續(xù)解釋說:“還有,雖然你看圖里的連線比較多,但在實際情況里,并不是所有的圈圈之間都能產(chǎn)生連線,連接關(guān)系也有個合法性的問題嘛,所以復(fù)雜度是可以控制住的。”
小明感覺好像明白了一點,然后趕緊追問:“那遺傳算法呢?”
大明說:“雖然動態(tài)規(guī)劃的復(fù)雜度是可以控制的,但是如果表比較多,它的搜索空間還是很大,所以如果在表比較多的時候,可以嘗試使用遺傳算法,這個算法獲得的不一定是全局最優(yōu)解,可能是局部最優(yōu)解。”
“那遺傳算法是怎么實現(xiàn)物理路徑搜索的呢?”小明問。
牛二哥從書柜里找到了一本算法的書,恰好里面有遺傳算法的介紹,于是朗讀了起來:“遺傳算法的實現(xiàn)步驟如下:
- 種群初始化:對基因進行編碼,并通過對基因進行隨機的排列組合,生成多個染色體,這些染色體構(gòu)成一個新的種群。另外,在生成染色體的過程中同時計算染色體的適應(yīng)度;
- 選擇染色體:通過隨機選擇(實際上通過基于概率的隨機數(shù)生成算法,這樣能傾向于選擇出優(yōu)秀的染色體),選擇出用于交叉和變異的染色體;
- 交叉操作:染色體進行交叉,產(chǎn)生新的染色體并加入到種群;
- 變異操作:對染色體進行變異操作,產(chǎn)生新的染色體并加入到種群;
- 適應(yīng)度計算:對不良的染色體進行淘汰。”
大明笑著說:“盡信書不如無書,我來說一下遺傳算法是如何解決貨郎問題的。我們可以將城市作為基因,走遍各個城市的路徑作為染色體,路徑的總長度作為適應(yīng)度,適應(yīng)度函數(shù)負責篩選掉比較長的路徑,保留較短的路徑,算法的步驟如下:
- 對各個城市進行編號,將各個城市根據(jù)編號進行排列組合,生成多條新的路徑(染色體)。然后根據(jù)各城市間的距離計算整體路徑長度(適應(yīng)度),多條新路徑構(gòu)成一個種群;
- 選擇兩個路徑進行交叉(需要注意交叉生成新染色體中不能重復(fù)出現(xiàn)同一個城市),對交叉操作產(chǎn)生的新路徑計算路徑長度;
- 隨機選擇染色體進行變異(通常方法是交換城市在路徑中的位置),對變異操作后的新路徑計算路徑長度;
- 對種群中所有路徑進行基于路徑長度有小到大排序,淘汰掉排名靠后的路徑。”
大明一口氣說完了整個流程,長舒了一口氣,繼續(xù)說道:“怎么樣,是不是so easy?”
小明想了想牛二哥和大明說的流程,然后說,“我來猜想一下PostgreSQL是如何實現(xiàn)遺傳算法的。PostgreSQL應(yīng)該是模擬了解決貨郎問題的方法,它將表作為基因,最終生成的執(zhí)行計劃作為染色體,執(zhí)行計劃的總代價作為適應(yīng)度,適應(yīng)度函數(shù)則是基于路徑的代價進行篩選,對不對?”
牛二哥贊嘆道:“說得非常好,不過需要注意的是,PostgreSQL的基因算法實現(xiàn)方式和通常的遺傳算法略有不同,在于其沒有變異的過程,只通過交叉產(chǎn)生新的染色體,不過這都不是重點了。”
大明說:“哎哎哎,我們不是在搜索飯店嗎,怎么就說起最優(yōu)路徑了?先點餐吧,再晚飯都沒得吃了。”
于是三個人又熱火朝天地搜起飯店來……
總結(jié)
本故事到此暫時劇終了。通過上下兩篇文章,我們基本已了解到大部分查詢優(yōu)化的概念,但篇幅有限,沒能把細節(jié)說得特別到位,請大家多多包涵。
兩篇文章中大部分內(nèi)容均摘錄自我的新書《PostgreSQL技術(shù)內(nèi)幕:查詢優(yōu)化深度探索》,然后以小明、大明和牛二哥的對話方式展現(xiàn)出來。而書中介紹的代碼分析部分以及比較深入的實現(xiàn)細節(jié),由于不太便于展示,所以在故事中沒有涉及到,有興趣的同學歡迎從書中獲取相關(guān)知識。