













MySQL主從信息的元數據維護
前幾天專門花了時間開始做元數據的稽核,其實這只是一個初步的開始,也算是才開始走上正道。
后續我又推出了幾個方面的改進,準備在元數據的粒度和深度上逐步改善,把已有的元數據完善起來,能夠發現很多潛在的問題,然后再逐步的改進,對于團隊內的同學來說,他們不需要花費很多的精力去收集信息,這個事情讓任務去做,他們需要做的是確認和問題修正。
比如通用元信息部分,對于MySQL實例來說,基本就是IP,端口,機房,數據庫角色(Master,Slave等),數據版本,應用信息等,系統層的元數據,比如硬盤,內存,CPU應該是由專有的模塊來維護。
確切的說,上面的這些信息只是通用,很難滿足業務的實際需求,比如一個MySQL服務端配置,是否開啟GTID,版本,角色,socket文件路徑,數據文件路徑,buffer_pool大小,是否開啟binlog,server_id,VIP等這些信息其實是我們需要明確了解的。
有了這些信息,其實能夠讓我們對于實例的屬性有一個基本的了解。
整個信息的收集看起來是一個很苦逼的過程,實際上我們可以讓它變得高大上一些,比如我們把信息收集后使用前端頁面做匯總和信息稽核,比如讓數據的收集實現自動化,批量完成,而不需要手工來觸發完成。
這些工作我們可以寫腳本來完成,信息可以收集到,但是信息的管理和統籌和單純的信息收集就不是一個層級了。我們在這個地方需要做的是元數據的管理和稽核,提前發現更多的問題,來逐步的完善,這樣一來元數據最起碼是可以參考和依賴的。
到了這個層級之后,其實我們能夠得到一個基本的實例屬性列表,但是顯然還是還是存在短板,我們的MySQL實例基本上是主從復制的關系,有些實例可能是測試環境,或者是數據流轉的節點,所以可能沒有從庫也沒有備份。所以對于MySQL信息的歸類我會這樣來分類和處理:
1.***個維度是單點實例,單點實例是那些測試環境,數據流轉節點或者業務優先級不高的業務。這些業務允許數據丟失,甚至允許環境重建,有一個基本的備份即可,這類的業務我們首先剝離出來,后面處理的時候就可以可以繞過這些節點,比如對于這些節點來說,可能不需要備份,可能不需要每天備份,壓根不需要增量備份,binlog備份,按照這個規劃,做了這些信息確認之后,后期要完成的備份恢復就有據可依,要不費了半天勁,***發現業務優先級不高,做事情的性價比就大打折扣。
2.第二個維度是數據庫角色,數據庫的角色其實不能嚴格意義上歸類為Master,Slave,其實可以有更多的類型,比如單點業務,我們可以歸類為SingleDB,如果是中繼節點(show master status或者show slave status持有雙重角色),我們可以歸類為RelayDB,如果是主庫或者是從庫即為Master,Slave,如果屬于MHA或者MGR的集群環境等,其實這個角色可以更加清晰,對于這部分信息我們需要做減法,即MHA或者MGR的環境,這類信息可以歸類為集群信息,我們可以對其他的信息按照SingleDB,RelayDB,Master,Slave這四個維度來統計即可。
要實現這個功能,就有一些技巧需要補充了。
我們在這里需要兩個腳本:
1)通過IP和端口信息得知實例的角色(Master,Slave,RelayDB,SingleDB等)
2)通過Slave和RelayDB的信息來得到Master的信息,亮點也就在此,通過這些信息我們可以清晰的達到一個復制關系圖,甚至可以看到一些意想不到的問題。
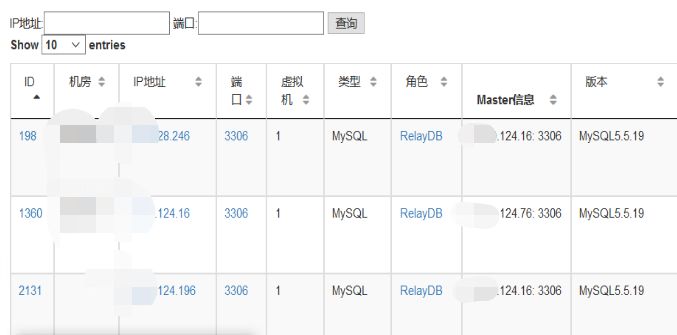
比如下面的IP信息,數據庫角色是中繼節點RelayDB(既是Master又是Slave)
我們根據IP的后兩段內容搜索得到下面的一個基本列表。
這樣一個關系,如果自己來刻意維護,其實很容易就會迷茫,或者意識不到這種級聯關系的存在,但是我們對這些數據進行抽象,就很快能夠得到這樣的餓一個關系圖,原來是這樣的一個級聯關系。這樣一來124.16這個中繼節點的角色和上下游的關系就很清晰了,那么從這個角度來看,我們是否需要對124.76做數據的備份就很容易得出結論了。
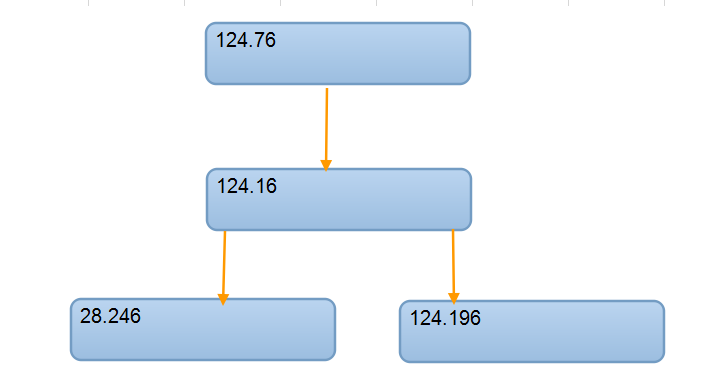
或者你可以基于這樣的一個關系型結構來構建出一個更加完整的關系圖,如果哪個環境缺少了信息也能夠很清晰的判斷出來。
到了這個階段,就是發揮數據分析價值的時候了,數據一直在那兒,就看你是怎么處理它的。
















