問題來了,PostgreSQL的好處都有啥?
PostgreSQL的Slogan是“世界上最先進的開源關系型數據庫”,但我覺得這口號不夠清晰,啥叫‘先進’?而且一看就是在懟MySQL那個“世界上最流行的開源關系型數據庫”的口號,有碰瓷之嫌。要我說最能生動體現PG特色的描述應該是:一專多長的全棧數據庫,一招鮮吃遍天。
全棧數據庫
成熟的應用可能會用到許許多多的數據組件(功能):緩存,OLTP,OLAP/批處理/數據倉庫,流處理/消息隊列,搜索索引,NoSQL/文檔數據庫,地理數據庫,空間數據庫,時序數據庫,圖數據庫。傳統的架構選型呢,可能會組合使用多種組件,典型的如:Redis + MySQL + Greenplum/Hadoop + Kafuka/Flink + ElasticSearch,一套組合拳基本能應付大多數需求了。不過比較令人頭大的就是異構系統集成了:大量的代碼都是重復繁瑣的搬磚代碼,干著把數據從A組件搬運到B組件的事情。

在這里,MySQL就只能扮演OLTP關系型數據庫的角色,但如果是PostgreSQL,就可以身兼多職,One handle them all,比如:
- OLTP:事務處理是PostgreSQL的本行
- OLAP:citus分布式插件,ANSI SQL兼容,窗口函數,CTE,CUBE等高級分析功能,任意語言寫UDF
- 流處理:PipelineDB擴展,Notify-Listen,物化視圖,規則系統,靈活的存儲過程與函數編寫
- 時序數據:timescaledb時序數據庫插件,分區表,BRIN索引
- 空間數據:PostGIS擴展(殺手锏),內建的幾何類型支持,GiST索引。
- 搜索索引:全文搜索索引足以應對簡單場景;豐富的索引類型,支持函數索引,條件索引
- NoSQL:JSON,JSONB,XML,HStore原生支持,至NoSQL數據庫的外部數據包裝器
- 數據倉庫:能平滑遷移至同屬Pg生態的GreenPlum,DeepGreen,HAWK等,使用FDW進行ETL
- 圖數據:遞歸查詢
- 緩存:物化視圖
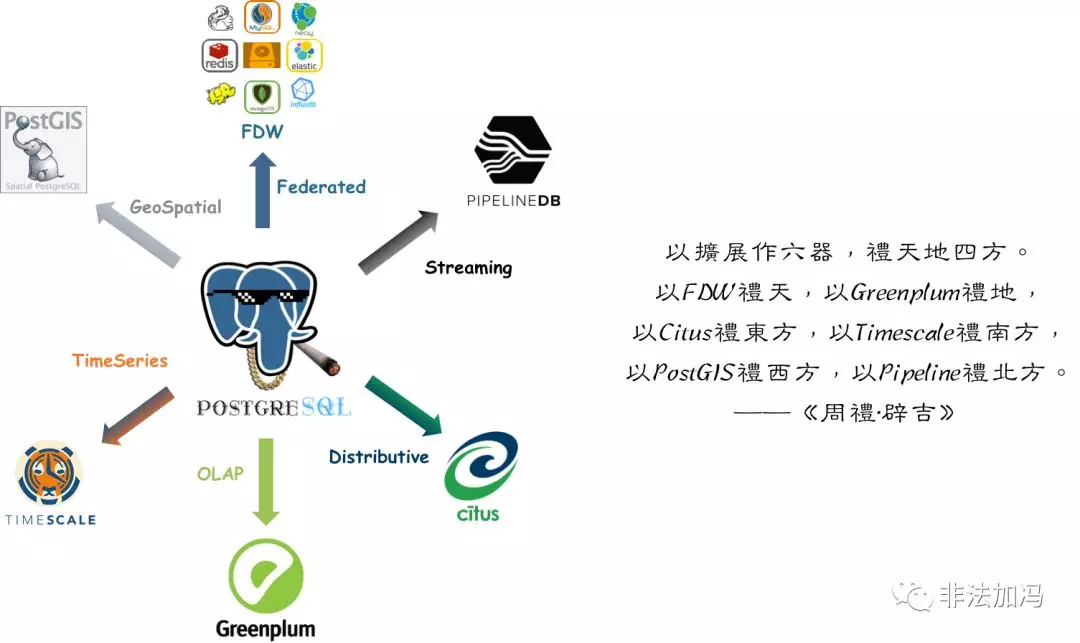
以擴展作六器,禮天地四方。
以FDW禮天,以Greenplum禮地,
以Citus禮東方,以Timescale禮南方,
以PostGIS禮西方,以Pipeline禮北方。
——《周禮·辟吉》
在探探的舊版架構中,整個系統就是圍繞PostgreSQL設計的。幾百萬日活,幾百萬全局DB-TPS,幾百TB數據的規模下,數據組件只用了PostgrSQL。獨立的數倉,消息隊列和緩存都是后來才引入的。而且這只是驗證過的規模量級,進一步壓榨PG是完全可行的。
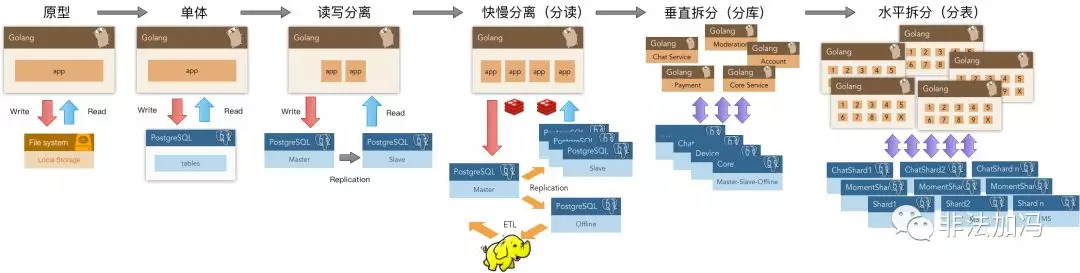
因此,在一個很可觀的規模內,PostgreSQL都可以扮演多面手的角色,一個組件當多種組件使。雖然在某些領域它可能比不上專用組件,至少都做的都還不賴。而單一數據組件選型可以極大地削減項目額外復雜度,這意味著能節省很多成本。它讓十個人才能搞定的事,變成一個人就能搞定的事。
對絕大多數應用而言,終其生命周期都不會有超出Pg能力范圍之外的數據量級。為了不需要的規模而設計是白費功夫,實際上這屬于過早優化的一種形式。 此外,只有當沒有單個軟件能滿足你的所有需求時,才會存在分拆與集成的利弊權衡。集成多種異構技術是相當棘手的工作,如果真有那么一樣技術可以滿足你所有的需求,那么使用該技術就是最佳選擇,而不是試圖用多個組件來重新實現它。
當業務規模增長到一定量級時,可能不得不使用基于微服務/總線的架構,將數據庫的功能分拆為多個組件。但PostgreSQL的存在極大地推后了這個權衡到來的閾值,而且分拆之后依然能繼續發揮重要作用。
運維友好
當然除了功能強大之外,Pg的另外一個重要的優勢就是運維友好。有很多非常實用的特性:
- DDL能放入事務中,刪表,TRUNCATE,創建函數,索引,都可以放在事務里原子生效,或者回滾。
- 這就能進行很多騷操作,比如在一個事務里通過RENAME,完成兩張表的王車易位。
- 能夠并發地創建、刪除索引,添加非空字段,重整索引與表(不鎖表)。
- 這意味著可以隨時在線上不停機進行重大的模式變更,按需對索引進行優化。
- 復制方式多樣:段復制,流復制,觸發器復制,邏輯復制,插件復制等等。
- 這使得不停服務遷移數據變得相當容易:復制,改讀,改寫三步走,線上遷移穩如狗。
- 提交方式多樣:異步提交,同步提交,法定人數同步提交。
- 這意味著Pg允許在C和A之間做出權衡與選擇,例如交易庫使用同步提交,普通庫使用異步提交。
- 系統視圖非常完備,做監控系統相當簡單。
- FDW的存在讓ETL變得無比簡單,一行SQL就能解決。
- FDW可以方便地讓一個實例訪問其他實例的數據或元數據。在跨分區操作,數據庫監控指標收集,數據遷移等場景中妙用無窮。同時還可以對接很多異構數據系統。
還有很多功能,就不一一列舉了。
生態健康
PostgreSQL的生態也很健康,社區相當活躍。
相比MySQL,PostgreSQL的一個巨大的優勢就是協議友好。PG采用類似BSD/MIT的PostgreSQL協議,差不多理解為只要別打著Pg的旗號出去招搖撞騙,隨便你怎么搞,換皮出去賣都行。君不見多少國產數據庫,或者不少“自研數據庫”實際都是Pg的換皮或二次開發產品。
當然,也有很多衍生產品會回饋主干,比如timescaledb,pipelinedb, citus 這些基于PG的“數據庫”,最后都變成了原生PG的插件。很多時候你想實現個什么功能,一搜就能找到對應的插件或實現。開源嘛,還是要講一些情懷的。
Pg的代碼質量相當之高,注釋寫的非常清晰。C的代碼讀起來有種Go的感覺,代碼都可以當文檔看了。能從中學到很多東西。相比之下,其他數據庫,比如MongoDB,看一眼我就放棄了讀下去的興趣。
而MySQL呢,社區版采用的是GPL協議,這其實挺蛋疼的。要不是GPL傳染,怎么會有這么多基于MySQL改的數據庫開源出來呢?而且MySQL還在烏龜殼的手里,讓自己的蛋蛋攥在別人手中可不是什么明智的選擇,更何況是業界毒瘤呢?Facebook修改React協議的風波就算是一個前車之鑒了。
問題
當然,要說有什么缺點或者遺憾,那還是有幾個的:
- 因為使用了MVCC,數據庫需要定期VACUUM,需要定期維護表和索引避免膨脹導致性能下降。
- 沒有很好的開源集群監控方案(或者太丑!),需要自己做。
- 慢查詢日志和普通日志是混在一起的,需要自己解析處理。
- 官方Pg沒有很好用的列存儲,對數據分析而言算一個小遺憾。
當然都是些無關痛癢的小毛小病,不過真正的問題可能和技術無關……
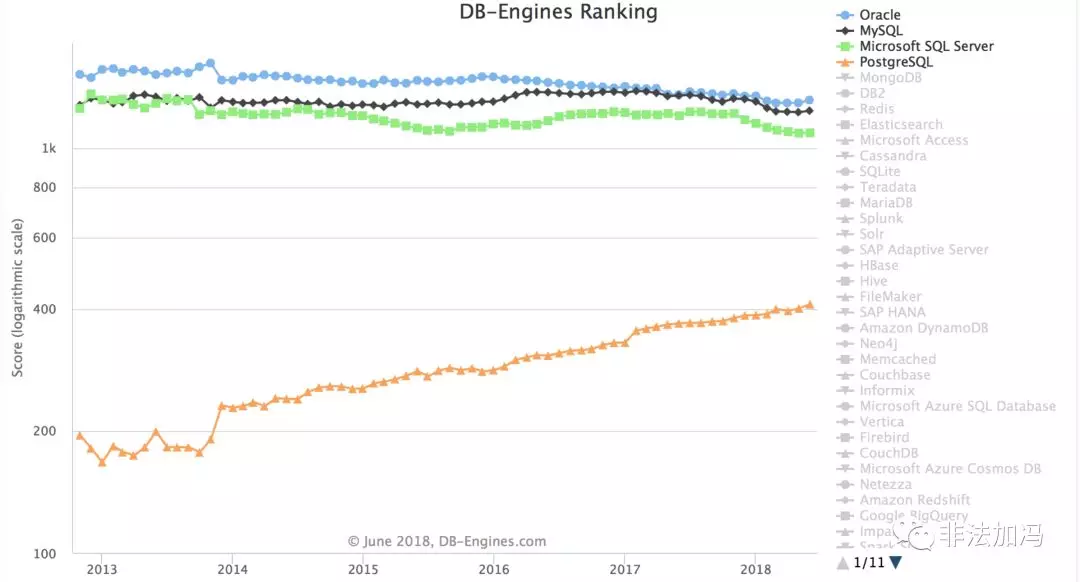
說到底,MySQL確實是最流行的開源關系型數據庫,沒辦法,寫Java的,寫PHP的,很多人最開始用的都是MySQL…,所以Pg招人相對困難是一個事實,很多時候只能自己培養。不過看DB Engines上的流行度趨勢,未來還是很光明的。