向Kubernetes容器云平臺遷移,你必須知道的9件事
一、現有平臺面臨的挑戰
不同企業開始往容器方向發展的初衷是不一樣的,有些企業是因為沒有運維工程師或運維團隊,而想要借助某個平臺實現運維自動化。
有些企業可能是由于計算資源的利用率比較低。雖然一些大型的互聯網公司都是動輒擁有成千上萬臺服務器,但實際上以我個人的經歷來看計算資源的利用率都不高,這里有很多歷史的原因,其中之一就是為了獲得更好的隔離性,而實現隔離***的辦法就是采用從物理機到基于虛擬的私有云技術。
對于有著比較長歷史的公司,應用部署往往會和本地的運行環境強相關,使得遷移變得非常困難,這時也需要有一個好的解決方案來解耦。另外業務總量的繁多,也會帶來管理的復雜度的提高。
二、為什么選擇Kubernetes
上面提到的這些問題在我們的生產實踐中都有不同程度的遇到,雖然有很多的解決方案,但是我們最終還是選擇了Kubernetes。
Kubernetes首要解決了計算資源利用率低下的問題,得益于此我們的服務器數量減少了一半。容器化解決了計算資源利用率問題。
業務容器鏡像一次構建,就能夠運行在多種環境上,這種方式減少了對運行環境的以來,給運維平臺帶來了足夠的靈活性,解決了服務商鎖定的問題,我們當時考慮的是如果某個IDC服務商不滿足服務要求如何做到快速遷移,一般來說大批量的服務遷移代價非常高,需要很長時間,容器化之后業務遷移時間只需要30分鐘左右。
通過Kubernetes的架構設計思想我們還可以規范網站系統的架構設計。***還有一點就是它實現了運維自動化。
三、向容器云平臺遷移前的準備工作
要想向容器云遷移,企業內部需要一定的運維能力,如果企業的規模還不夠大,也可以考慮一些國內的容器云服務提供商。下面來說下我們自己所做的一些準備工作。
首先自然是搭建Kubernetes集群,私有Docker鏡像倉庫構建采用的是harbor,然后是獨立出來的集群監控,CI/CD基礎設置使用的是Jenkins和helm,分布式存儲解決方案用的是Glusterfs。
四、業務遷移中使用的規范
從2015年底1.0版到之后的1.2、1.3版Kubernetes中的問題還是比較多的,企業要使用它是需要一定勇氣的。但現在基本上趨于成熟,對于大部分應用不用太多的改造也可以跑的很好。
即使是這樣,也不是所有的應用都可以遷移到容器云中,如果應用能夠很好的符合云原生的設計原則當然可以遷移進來,但是大部分的應用并不是按照這樣的設計原則設計的。這個時候***的辦法是先將業務遷移進來,然后再逐步演進成微服務架構。
在這個過程中我們剛開始其實也沒有任何規范,之后才陸續制定了相關規范,下面來具體看下遷移規范。
1. 容器鏡像封裝的基本原則
早期很多系統架構師都將Docker當做輕量級的虛擬機在使用,但這并不是***實踐,要想正確的使用Docker需要符合以下基本原則:
- 盡可能設計成無狀態服務,它帶來的好處就是能夠非常容易的做水平擴展
- 盡可能消除不必要的運行環境依賴,如果容器內業務依賴太多水平擴展就會變的非常困難,在傳統的部署形式下,無論是虛擬機部署還是物理機部署都經常會產生各種各樣沒必要的依賴,對于有一定歷史的企業這個問題就會非常嚴重
- 需要持久化的數據寫入到分布式存儲卷
- 盡可能保證業務單一性,這樣能夠讓分布式應用很容易擴展,同樣它也是微服務架構中的設計原則
- 控制輸出到stdout和stderr的日志寫入量
- 配置與容器鏡像內容分離
- 容器中使用K8S內部dns代替ip地址配置形式
- 日志采用集中化處理方案(EFk)
- 采用獨立的容器處理定時任務
2. NameSpace的使用
由于考慮到測試環境和staging等運行環境的資源利用率并不高,所以就想在一個集群內部同時運行開發、測試、staging、生產環境。通過NameSpace實現不同運行環境的隔離,同時應用軟件在不同的運行環境之間也不會產生命名沖突。
3. Service的命名規范
在v1.5版之前Service的命名不能超過24個字符,v1.5版之后最多63個字符。另外還需要滿足正則regex[a-z]([-a-z0-9]*[a-z0-9])?的要求,這意味著首字母必須是a-z的字母,末字母不能是-,其他部分可以是字母數字和-符號。一般來說命名方式都是使用“業務名-應用服務器類型-其他標識”的形式,如book-tomcat-n1、book-mysql-m1等。
4. 應用健康檢查規范
應用健康檢查規范是實現自動化運維的重要組成部分,也是系統故障自動發現和自我恢復的重要手段。目前有兩種健康檢查方式,分別是進程級和業務級。
進程級健康檢查是Kubernetes本身具備的,它用來檢驗容器進程是否存活,是默認開啟的。
業務級的健康檢查由我們自己實現,它有三點要求,一是必須要檢查自身核心業務是否正常,二是健康檢查程序執行時間要小于健康檢查周期,三是健康檢查程序消耗資源要合理控制,避免出現服務抖動。
健康檢查程序在不同環境下有著不同的實現:
- web服務下采用HTTPGET方式進行健康檢查,需要實現一個“/healthz”URL,這個URL對應的程序需要檢查所有核心服務是否正常,健康檢查程序還應該在異常情況下輸出每一個檢查項的狀態明細。
- 其他網絡服務下可以采用探查容器指定端口狀態來判斷容器健康狀態。
- 非網絡服務下需要在容器內部執行特定命令,根據退出碼判斷容器健康狀態。
5. Yaml中Image tag配置規范
部署容器鏡像時應該避免使用latest tag形式,否則一旦出現問題就難以跟蹤到當前運行的Image版本,也難以進行回滾操作。所以建議每個容器Image的tag應該用版本號來標識。
6. 使用ConfigMap實現應用平滑遷移
早期的1.0版本配置信息都是寫在配置文件中的,要做遷移就需要改很多東西,當時就只有幾種方法可以傳遞配置信息,其中一種是通過環境變量傳遞,然后內部還要有一個對應機制進行轉化,這其實是非常麻煩的過程。但是現在有了ConfigMap之后,就只需要將原先的配置文件導入到ConfigMap中就行了。
五、遷移中遇到的其他問題
1. 關于CI/CD
我們在做遷移的時候采用的是Jenkins來實現CI/CD的,然后通過Helm來實現軟件包管理,Helm是Kubernetes的官方子項目,作為企業內部的應用管理是非常方便的,它使得開發者不用再去關注Kubernetes本身而只需要專注于應用開發就夠了。
2. 時區的配置問題
從官方下載的鏡像都會有默認時區,一般我們使用的時候都需要更改時區,更改時區的方式有多種,這里簡單說兩種。一是將容器鏡像的/etc/loacltime根據需要設置為對應的時區,二是采用配置文件中的volume掛載宿主機對應的localtime文件的方式。推薦采用第二種方式。
3. 外部網絡訪問Service
在沒有Ingress的時候我們是使用內建Nginx容器來轉發集群內部服務,現在則是通過Ingress轉發集群內部服務,Ingress通過NodePort方式暴露給外網。
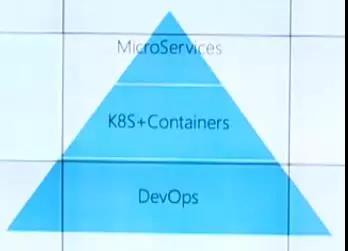
***組合
上圖展示的是Kubernetes的***組合,它以DevOps作為基礎,上層是k8s加上Containers,頂層構筑的是微服務應用。這樣的組合帶來的不僅是一個容器云,更多的是改變了研發流程和組織結構,這主要是受微服務的架構思想影響。
過去完成一個應用的版本發布可能要多人協同,一旦有緊急發布的時候就會發現這其實是非常笨重的。但是如果是基于微服務架構做的應用,往往一到兩個人就可以維護一個微服務,他們自己就可以決定這個微服務是否獨立部署上線。
關于微服務和Kubernetes還有一個優勢必須要強調,配合CI/CD開發人員終于可以不再考慮部署環境的細節了。