













一文解讀合成數據在機器學習技術下的表現
作者:Eric Le Fort
編譯:蔣雨暢 盧苗苗
想法
相比于數量有限的“有機”數據,我將分析、測評合成數據是否能實現改進。
動機
我對合成數據的有效性持懷疑態度——預測模型只能與用于訓練數據的數據集一樣好。這種懷疑論點燃了我內心的想法,即通過客觀調查來研究這些直覺。
需具備的知識
本文的讀者應該處于對機器學習相關理論理解的中間水平,并且應該已經熟悉以下主題以便充分理解本文:
- 基本統計知識,例如“標準差”一詞的含義
- 熟悉神經網絡,SVM和決策樹(如果您只熟悉其中的一個或兩個,那可能就行了)
- 了解基本的機器學習術語,例如“訓練/測試/驗證集”的含義
合成數據的背景
生成合成數據的兩種常用方法是:
- 根據某些分布或分布集合繪制值
- 個體為本模型的建模
在這項研究中,我們將檢查***類。為了鞏固這個想法,讓我們從一個例子開始吧!
想象一下,在只考慮大小和體重的情況下,你試圖確定一只動物是老鼠,青蛙還是鴿子。但你只有一個數據集,每種動物只有兩個數據。因此不幸的是,我們無法用如此小的數據集訓練出好的模型!
這個問題的答案是通過估計這些特征的分布來合成更多數據。讓我們從青蛙的例子開始
參考這篇維基百科的文章(只考慮成年青蛙):https://en.wikipedia.org/wiki/Common_frog
***個特征,即它們的平均長度(7.5cm±1.5cm),可以通過從正態分布中繪制平均值為7.5且標準偏差為1.5的值來生成。類似的技術可用于預測它們的重量。
然而,我們所掌握的信息并不包括其體重的典型范圍,只知道平均值為22.7克。一個想法是使用10%(2.27g)的任意標準偏差。不幸的是,這只是純粹猜測的結果,因此很可能不準確。
鑒于與其特征相關信息的可獲得性,和基于這些特征來區分物種的容易程度,這可能足以培養良好的模型。但是,當您遷移到具有更多特征和區別更細微的陌生系統時,合成有用的數據變得更加困難。
數據
該分析使用與上面討論的類比相同的想法。我們將創建一些具有10個特征的數據集。這些數據集將包含兩個不同的分類類別,每個類別的樣本數相同。
“有機”數據
每個類別將遵循其中每個特征的某種正態分布。例如,對于***種特征:***個類別樣本的平均值為1500,標準差為360;第二個類別樣本的平均值為1300,標準差為290。其余特征的分布如下:

該表非常密集,但可以總結為:
- 有四個特征在兩類之間幾乎無法區分,
- 有四個特征具有明顯的重疊,但在某些情況下應該可以區分,并且
- 有兩個特征只有一些重疊,通常是可區分的。
創建兩個這樣的數據集,一個1000樣本的數據集將保留為驗證集,另一個1000樣本的數據集可用于訓練/測試。
這會創建一個數據集,使分類變得足夠強大。
合成數據
現在事情開始變得有趣了!合成數據將遵循兩個自定義分布中的其中一個。***個我稱之為“ Spikes Distribution”。此分布僅允許合成特征采用少數具有每個值的特定概率的離散值。例如,如果原始分布的平均值為3且標準差為1,則尖峰(spike)可能出現在2(27%),3(46%)和4(27%)。
第二個自定義分布我稱之為“ Plateaus Distribution”。這種分布只是分段均勻分布。使用平臺中心的正態分布概率推導出平穩點的概率。您可以使用任意數量的尖峰或平臺,當添加更多時,分布將更接近正態分布。
為了清楚說明這兩個分布,可以參考下圖:
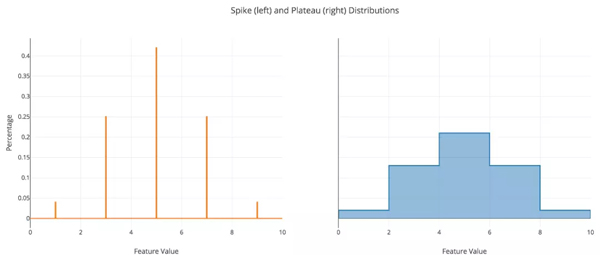
(注:尖峰分布圖不是概率密度函數)
在這個問題中,合成數據的過程將成為一個非常重要的假設,它有利于使合成數據更接近于“有機”數據。該假設是每個特征/類別對的真實平均值和標準差是已知的。實際上,如果合成數據與這些值相差太遠,則會嚴重影響訓練模型的準確性。
好的,但為什么要使用這些分布?他們如何反映現實?
我很高興你問這個問題!在有限的數據集中,您可能會注意到,對于某個類別,某個特征只會占用少量值。想象一下這些值是:
- (50,75,54,49,24,58,49,64,43,36)
或者如果我們可以對這列進行排序:
- (24,36,43,49,49,50,54,58,64,75)
為了生成此特征的數據,您可以將其拆分為三個部分,其中***部分將是最小的20%,中間的60%將是第二部分,第三部分將是***的20%。然后使用這三個部分,您可以計算它們的平均值和標準差:分別為(30,6.0),(50.5,4.6)和(69.5,5.5)。如果標準差相當低,比如大約為相應均值的10%或更小,則可以將該均值視為該部分的尖峰值。否則,您可以將該部分視為一個平臺,其寬度是該部分標準差的兩倍,并以該部分的平均值作為中心。
或者,換句話說,他們在模擬不***的數據合成方面做得不錯。
我將使用這些分布創建兩個800樣本數據集 - 一個使用尖峰,另一個使用平臺。四個不同的數據集將用于訓練模型,以便比較每個數據集的有用性:
- 完整 (Full) - 完整的1000個樣本有機數據集(用于了解上限)
- 真實 (Real) - 只有20%的樣本有機數據集(模擬情況而不添加合成數據)
- 尖峰(Spike) - “真實”數據集與尖峰數據集相結合(1000個樣本)
- 平臺(Plateaus) - “真實”數據集與平臺數據集相結合(1000個樣本)
現在開始令人興奮的部分!
訓練
為了測試每個數據集的強度,我將采用三種不同的機器學習技術:多層感知器(MLP),支持向量機(SVM)和決策樹(Decision Trees)。為了幫助訓練,由于某些特征的幅度比其他特征大得多,因此利用特征縮放來規范化數據。使用網格搜索調整各種模型的超參數,以***化到達***的超參數集的概率。
總之,我在8個不同的數據集上訓練了24種不同的模型,以便了解合成數據對學習效果的影響。
相關代碼在這里:https://github.com/EricLeFort/DataGen
結果
經過幾個小時調整超參數并記錄下精度測量結果后,出現了一些反直覺的結果!完整的結果集可以在下表中找到:
☟多層感知器(MLP)
")
☟支持向量機(SVM)
")
☟決策樹(Decision Trees)

在這些表中,“Spike 9”或“Plateau 9”是指分布和使用的尖峰/平臺的數量。單元格中的值是使用相應的訓練/測試數據對模型進行訓練/測試,并用驗證集驗證后的的最終精度。還要記住,“完整”(Full)類別應該是準確性的理論上限,“真實”(Rea;)類別是我們在沒有合成數據的情況下可以實現的基線。
一個重要的注意事項是,(幾乎)每次試驗的訓練/測試準確度都明顯高于驗證準確度。例如,盡管MLP在Spike-5上得分為97.7%,但在同一試驗的訓練/測試數據上分別得分為100%和99%。當在現實世界中使用時,這可能導致模型有效性的過高估計。
完整的這些測量可以在GitHub找到:https://github.com/EricLeFort/DataGen
讓我們仔細看看這些結果。
首先,讓我們看一下模型間的趨勢(即在所有機器學習技術類型中的合成數據集類型的影響)。似乎增加更多尖峰/平臺并不一定有助于學習。你可以看到在3對 5時尖峰/平臺之間的一般改善,但是當看到5對9時,則要么變平或稍微傾斜。
對我來說,這似乎是違反直覺的。隨著更多尖峰/平臺的增加,我預計會看到幾乎持續的改善,因為這會導致分布更類似于用于合成數據的正態分布。
現在,讓我們看一下模型內的趨勢(即各種合成數據集對特定機器學習技術的影響)。對于MLP來說,尖峰或平臺是否會帶來更好的性能似乎缺少規律。對于SVM,尖峰和平臺似乎表現得同樣好。然而,對于決策樹而言,平臺是一個明顯的贏家。
總的來說,在使用合成數據集時,始終能觀察到明顯的改進!
以后的工作
需要注意的一個重要因素是,本文的結果雖然在某些方面有用,但仍然具有相當的推測性。因此,仍需要多角度的分析以便安全地做出任何明確的結論。
這里所做的一個假設是每個類別只有一個“類型”,但在現實世界中并不總是如此。例如,杜賓犬和吉娃娃都是狗,但它們的重量分布看起來非常不同。
此外,這基本上只是一種類型的數據集。應該考慮的另一個方面是嘗試類似的實驗,除了具有不同維度的特征空間的數據集。這可能意味著有15個特征而不是10個或模擬圖像的數據集。
相關報道:https://www.codementor.io/ericlefort/my-thoughts-on-synthetic-data-kq719a5ss
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】



























