













從技術(shù)角度聊聊,短視頻為何讓人停不下來?
基于時間碎片化、視頻交互強(qiáng)、內(nèi)容豐富、體驗(yàn)好等因素,短視頻近幾年處在流量風(fēng)暴的中心,各大平臺紛紛涉足短視頻領(lǐng)域。因此,平臺對短視頻內(nèi)容的推薦尤為重要,千人千面是短視頻推薦核心競爭力。短視頻一般從“點(diǎn)擊率”與“觀看時長”兩方面優(yōu)化來提升用戶消費(fèi)時長。
接下來,UC事業(yè)部國際研發(fā)團(tuán)隊的童鞋,將從這兩方面重點(diǎn)論述短視頻模型點(diǎn)擊時長多目標(biāo)優(yōu)化。
背景
目前,信息流短視頻排序是基于CTR預(yù)估Wide&Deep深層模型。在Wide&Deep模型基礎(chǔ)上做一系列相關(guān)優(yōu)化,包括相關(guān)性與體感信號引入、多場景樣本融合、多模態(tài)學(xué)習(xí)、樹模型等,均取得不錯收益。
總體上,短視頻模型優(yōu)化可分為兩部分優(yōu)化:
- 感知相關(guān)性優(yōu)化——點(diǎn)擊模型以優(yōu)化(CTR/Click為目標(biāo))
- 真實(shí)相關(guān)性優(yōu)化——時長多目標(biāo)優(yōu)化(停留時長RDTM/播放完成率PCR)
上述收益均基于點(diǎn)擊模型的優(yōu)化,模型能夠很好地捕抓USER-ITEM之間感知相關(guān)性,感知權(quán)重占比較高,弱化真實(shí)相關(guān)性,這樣可能導(dǎo)致用戶興趣收窄,長尾問題加劇。此外,觀看時長,無論是信息流、競品均作為重要優(yōu)化目標(biāo)。在此背景下,短視頻排序模型迫切需要引入時長多目標(biāo)優(yōu)化,提升推薦的真實(shí)相關(guān)性,尋求在時長上取得突破。
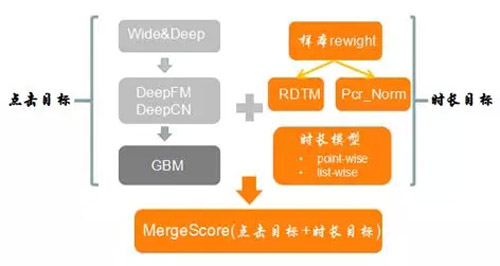
時長多目標(biāo)的引入,排序模型不僅僅優(yōu)化點(diǎn)擊目標(biāo),同時也要兼顧時長目標(biāo),使得排序模型的感知相關(guān)性與真實(shí)相關(guān)性之間取得收益最大化的平衡;目前業(yè)界點(diǎn)擊+時長目標(biāo)優(yōu)化有多種方式,包括多模態(tài)學(xué)習(xí)(點(diǎn)擊+時長)、聯(lián)合建模、樣本reweight等。
本次我們使用樣本reweight方法,在點(diǎn)擊label不變的前提下,時長作為較強(qiáng)的bias去影響時長目標(biāo),保證感知相關(guān)性前提,去優(yōu)化真實(shí)相關(guān)性。此外,我們正調(diào)研更加自適應(yīng)的時長建模方式(point-wise、list-wise),后續(xù)繼續(xù)介紹。上述是模型時長多目標(biāo)優(yōu)化簡介,樣本reweight取得不錯的收益,下面展開介紹下。
RDTM REWEIGHTING
觀看時長加權(quán)優(yōu)化,我們使用weightlogistic regression方法,參照RecSys2016上Youtubb時長建模,提出點(diǎn)擊模型上樣本reweight。模型訓(xùn)練時,通過觀看時長對正樣本加權(quán),負(fù)樣本權(quán)重不變,去影響正負(fù)樣本的權(quán)重分布,使得觀看時長越長的樣本,在時長目標(biāo)下得到充分訓(xùn)練。
加權(quán)邏輯回歸方法在稀疏點(diǎn)擊場景下可以很好使得時長逼近與期望值。假設(shè)就是weighted logistic regression學(xué)到的期望,其中N是樣本數(shù)量,K是正樣本,Ti是停留時長,真實(shí)期望就近似逼近E(T)*(1+P),P是點(diǎn)擊概率,E(T)是停留時長期望值,在P<<1情況下,真實(shí)期望值就逼近E(T)。因此,加權(quán)邏輯回歸方式做樣本加權(quán),切合我們點(diǎn)擊稀疏的場景,通過樣本加權(quán)方式使得模型學(xué)到item在觀看時長上偏序關(guān)系。
樣本加權(quán)優(yōu)化我們參照了Youtube的時長建模,但做法上又存在一些差異:
- Label:Youtube以時長為label做優(yōu)化,而我們還是基于點(diǎn)擊label,這樣是為了保證模型感知相關(guān)性(CTR/Click)。
- 分類/回歸:Youtube以回歸問題作時長加權(quán),serving以指數(shù)函數(shù)擬合時長預(yù)測值,我們則是分類問題,優(yōu)化損失函數(shù)logloss,以時長bias優(yōu)化時長目標(biāo)。
- 加權(quán)形式:時長加權(quán)方式上我們考慮觀看時長與視頻長短關(guān)系,采用多分段函數(shù)平滑觀看時長和視頻長短關(guān)系,而youtube則是觀看時長加權(quán)。
上述差異主要從兩個方面考慮:
- 保證CTR穩(wěn)定的前提下(模型label依然是點(diǎn)擊),通過樣本reweight去優(yōu)化時長目標(biāo)。
- 分段函數(shù)平滑避免長短視頻的下發(fā)量嚴(yán)重傾斜,盡可能去減少因?yàn)橐曨l長短因素,而使模型打分差距較大問題。
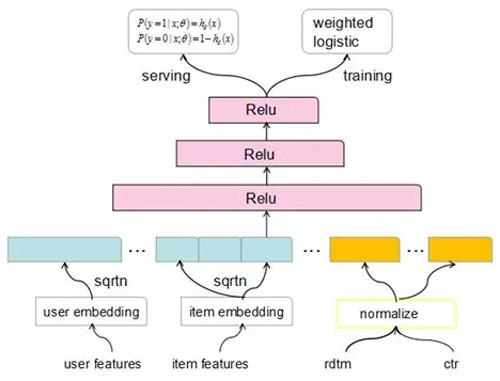
在模型網(wǎng)絡(luò)結(jié)構(gòu)上,底層類目或內(nèi)容特征做embedding共享,連續(xù)特征離散歸一化。訓(xùn)練時通過引入weighted logistic去優(yōu)化時長目標(biāo),在線預(yù)測依然是0/1概率,而在0/1概率跟之前不同是的經(jīng)過時長bias修正,使得模型排序考慮真實(shí)相關(guān)性。
離線評估指標(biāo)
1、AUC:AUC作為排序模型常用離線評估特別適用是0/1分類問題,短視頻排序模型依然是0/1問題,所以,AUC是一個基礎(chǔ)離線指標(biāo)。此外,AUC很難準(zhǔn)確地評估模型對于時長優(yōu)化好壞,AUC只是作為模型準(zhǔn)入的條件,保證AUC持平/正向前提下,我們需要時長指標(biāo)衡量準(zhǔn)確地模型收益。
2、AVG_RDTM:(預(yù)測平均停留時長):每一batch中選取模型打分top k正樣本,取該批樣本觀看時長均值作為AVG_RDTM,AVG_RDTM的大小來離線評估模型在時長推薦的好壞。物理意義: 取打分top k正樣本,保證模型推薦感知相關(guān)性(CTR)前提下,AVG_RDTM指標(biāo)衡量點(diǎn)擊正樣本的觀看時長收益,AVG_RDTM越大,時長收益越好。在線時長指標(biāo)趨勢與AVG_RDTM一致,漲幅上有diff。
PCR_NORM REWEIGHTING
一期在觀看時長樣本加權(quán)上取得不錯的收益,二期是集中播放完成率上的優(yōu)化。
二期我們策略review結(jié)果發(fā)現(xiàn),目前一大部分高播放完成率的視頻,CTR較低,模型打分靠后,這批item中較短視頻內(nèi)占比較大。一期通過時長分段函數(shù)樣本加權(quán),雖然一定程度上平滑了視頻長短對打分影響,但是播放完成率體現(xiàn)用戶對item的關(guān)注度程度更能反映推薦的真實(shí)相關(guān)性。短視頻觀看時長,視頻播放完成率上取得突破對于短視頻規(guī)模化和口碑打造具有強(qiáng)推進(jìn)劑作用。
針對以上較短,較長的優(yōu)質(zhì)視頻打分靠后,下發(fā)量不足的問題,我們引入分位數(shù)播放完成率來做平滑加權(quán)。進(jìn)一步升級觀看時長的優(yōu)化。主要是以下兩種方式:
- 時長目標(biāo)優(yōu)化從停留時長加權(quán)演變至播放完成率加權(quán),更好的平滑長短視頻之間的打分差異,使得模型打分更加注重于真實(shí)相關(guān)性。
- 視頻時長分段,停留時長完成率分位數(shù)歸一化+威爾遜置信區(qū)間平滑,使得各視頻時長段播放完成率相對可比,避免出現(xiàn)打分因視頻長度嚴(yán)重傾斜情況。
此外,較短或較長的視頻在播放完成率上存在天然的差距,我們按視頻本身長度離散,觀看時長做分位數(shù)處理,在此基礎(chǔ)添加威爾遜置信區(qū)間。歸一化長短視頻播放完成率上的差異,使得各長度段的視頻播放完成率處在可比區(qū)間內(nèi)。


時長多目標(biāo)優(yōu)化從觀看時長(RDTM)升級至播放完成率(PCR_Norm), 使得短視頻觀看時長處在相對可比的狀態(tài),盡可能減少視頻長短對打分影響,使得模型打分更加專注于User-Item真實(shí)相關(guān)性與視頻質(zhì)量,提升長尾優(yōu)質(zhì)的視頻消費(fèi),拉升整體視頻觀看時長。
二期Pcr_norm優(yōu)化在一期觀看時長優(yōu)化基礎(chǔ)上,離線評估AUC與AVG_RDTM,歸一化播放完成率更能反映用戶對視頻的專注度,通過優(yōu)化視頻單次閱讀時長,閱讀完成率來提升整體的觀看時長的消費(fèi)。
優(yōu)化收益:
一期+二期離線AUC累積提升6%以上,在線人均時長累積提升10%以上。
結(jié)語
信息流短視頻多目標(biāo)優(yōu)化目前處于探索階段,初步探索出短視頻多目標(biāo)優(yōu)化漸進(jìn)路線,從樣本reweight -> point-wise/list-wise時長建模 -> 多模態(tài)聯(lián)合學(xué)習(xí)的方向。此外,沉淀了套策略review和數(shù)據(jù)分析方法論,為后續(xù)時長優(yōu)化提供數(shù)據(jù)基礎(chǔ)。
雖然現(xiàn)階段短視頻時長多目標(biāo)優(yōu)化取得不錯收益,但是規(guī)則性較多,后續(xù)我們將逐步轉(zhuǎn)向自適應(yīng)的時長建模,從point-wise到全局list-wise時長優(yōu)化,由感知相關(guān)性優(yōu)化轉(zhuǎn)向真實(shí)相關(guān)性優(yōu)化,力爭在消費(fèi)時長取得重大突破。自適應(yīng)點(diǎn)擊目標(biāo)與時長目標(biāo)的權(quán)衡收益最大化,將是我們面臨一大挑戰(zhàn)。
【本文為51CTO專欄作者“阿里巴巴官方技術(shù)”原創(chuàng)稿件,轉(zhuǎn)載請聯(lián)系原作者】

















