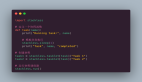
AI新人必看 | 參數和超參數還分不清楚嗎?
作者:佚名
計算機學科里有太多的術語,而且許多術語的使用并不一致。哪怕是相同的術語,不同學科的人理解一定有所不同。
計算機學科里有太多的術語,而且許多術語的使用并不一致。哪怕是相同的術語,不同學科的人理解一定有所不同。
比如說:“模型參數(model parameter)”和“模型超參數(model Hyperparameter)”。
對于初學者來說,這些沒有明確定義的術語肯定很令人困惑。尤其是對于些來自統計學或經濟學領域的人。
我們來仔細研究一下這些條款。
什么是模型參數?
模型參數是模型內部的配置變量,其值可以根據數據進行估計。
- 模型在進行預測時需要它們。
- 它們的值定義了可使用的模型。
- 他們是從數據估計或獲悉的。
- 它們通常不由編程者手動設置。
- 他們通常被保存為學習模型的一部分。
參數是機器學習算法的關鍵。它們通常由過去的訓練數據中總結得出。
在經典的機器學習文獻中,我們可以將模型看作假設,將參數視為對特定數據集的量身打造的假設。
***化算法是估計模型參數的有效工具。
- 統計:在統計學中,您可以假設一個變量的分布,如高斯分布。高斯分布的兩個參數是平均值(μ)和標準偏差(西格瑪)。這適用于機器學習,其中這些參數可以從數據中估算出來并用作預測模型的一部分。
- 編程:在編程中,您可以將參數傳遞給函數。在這種情況下,參數是一個函數參數,它可能具有一個值范圍之一。在機器學習中,您使用的特定模型是函數,需要參數才能對新數據進行預測。
模型是否具有固定或可變數量的參數決定了它是否可以被稱為“參數”或“非參數”。
模型參數的一些示例包括:
- 神經網絡中的權重。
- 支持向量機中的支持向量。
- 線性回歸或邏輯回歸中的系數。
什么是模型超參數?
模型超參數是模型外部的配置,其值無法從數據中估計。
- 它們通常用于幫助估計模型參數。
- 它們通常由人工指定。
- 他們通常可以使用啟發式設置。
- 他們經常被調整為給定的預測建模問題。
我們雖然無法知道給定問題的模型超參數的***值,但是我們可以使用經驗法則,在其他問題上使用復制值,或通過反復試驗來搜索***值。
當機器學習算法針對特定問題進行調整時(例如,使用網格搜索或隨機搜索時),那么正在調整模型的超參數或順序以發現導致最熟練的模型的參數預測。
- “許多模型有不能從數據直接估計的重要參數。例如,在K近鄰分類模型中......因為沒有可用于計算適當值的分析公式,這種類型的模型參數被稱為調整參數。”
- 第64-65頁,《應用預測模型》,2013
如果模型超參數被稱為模型參數,會造成很多混淆。克服這種困惑的一個經驗法則如下:
如果必須手動指定模型參數,那么它可能是一個模型超參數。
模型超參數的一些例子包括:
- 訓練神經網絡的學習速率。
- 用于支持向量機的C和sigma超參數。
- K最近鄰的K。
總之,模型參數是根據數據自動估算的。但模型超參數是手動設置的,并且在過程中用于幫助估計模型參數。
模型超參數通常被稱為參數,因為它們是必須手動設置和調整的機器學習的一部分。
責任編輯:龐桂玉
來源:
機器學習算法與Python學習